webpwn
一、web与pwn的联系
在某些 Web 服务中,会通过调用二进制程序来处理特定请求,尤其是在涉及动态内容生成、脚本执行、数据处理等场景时。以下是一些常见的例子:
1. CGI (Common Gateway Interface)
- 概述: CGI 是一种通用的接口标准,允许 Web 服务器调用外部的二进制程序或脚本来生成动态内容。
- 调用方式: 当用户请求特定路径时,Web 服务器会通过 CGI 将请求转发给二进制程序(例如 C/C++ 编写的可执行文件)。程序运行后将生成的输出(通常是 HTML)返回给用户。
- 示例:
httpd、nginx等服务器常通过 CGI 调用二进制文件,如/usr/lib/cgi-bin/中的程序。
2. FastCGI
- 概述: FastCGI 是 CGI 的增强版,通常用于调用长时间运行的二进制程序或脚本,以提高性能。
- 调用方式: Web 服务器将请求传递给 FastCGI 进程,该进程是一个长期运行的二进制程序,能快速处理多个请求,而不必每次请求都重新启动程序。
- 示例: PHP-FPM 就是一个常见的 FastCGI 进程管理器,它可以调用 PHP 解释器来处理请求。
3. 后端服务调用
- 概述: 有些 Web 服务会在后台调用二进制程序来执行任务,例如图像处理、数据分析、或其他复杂计算。
- 调用方式: 通常通过系统调用(如
exec或popen)从 Web 应用程序(如 Python、Ruby、PHP 等)中调用二进制程序,并获取其输出结果。 - 示例: 图像处理库 ImageMagick 或者 FFMPEG 等工具经常在 Web 服务中被调用来处理用户上传的媒体文件。
4. 嵌入式设备 Web 服务
- 概述: 在一些嵌入式系统(如路由器、NAS 设备等)中,Web 界面通常用于配置设备,而这些界面可能会调用二进制程序来执行系统命令或获取状态信息。
- 调用方式: 嵌入式设备的 Web 服务器可能直接调用设备上的二进制文件来执行配置变更或获取系统状态。
- 示例: 路由器的管理界面可能调用二进制程序来重启设备或修改网络设置。
5. Server-Side Includes (SSI)
- 概述: SSI 是一种服务器端技术,允许在 HTML 文件中包含其他文件或执行命令行程序。
- 调用方式: 通过 SSI,可以在 HTML 中直接调用二进制程序,并将其输出嵌入到页面中。
- 示例: 例如,在 Apache 中,可以通过
<!--#exec cmd="path/to/program"-->来调用一个二进制程序并将其输出嵌入到 HTML 中。
调用二进制程序的 Web 服务在动态内容生成和复杂任务处理时非常有用,尤其是在需要高效处理和利用已有二进制工具的情况下。使用这些技术时,可能会产生二进制的漏洞。
二、题目复现
1.gateway
以CGI产生的漏洞进行分析,这里分析时比较重要的是要在default文件里看Nginx配置信息。
Nginx配置信息
1 | listen 80 default_server; |
listen 80 default_server;
- 配置 Nginx 监听
80端口,这是默认的 HTTP 端口。 default_server表示这是默认的服务器块,当请求的主机名没有匹配到其他服务器块时,将使用此服务器块。
listen [::]:80 default_server;
- 这个指令与上面的类似,但它用于监听 IPv6 地址上的
80端口。
root /var/www/html;
- 定义服务器的根目录。当请求的 URI 没有指向具体文件时,Nginx 会在此目录中查找资源。
index index.html index.htm index.nginx-debian.html;
- 定义默认的主页文件列表。当用户访问一个目录时,Nginx 会依次查找这些文件作为首页。
**server_name _;**
- 设置服务器名。_ 表示匹配任何请求的服务器名。
1 | location / { |
location / { ... }
- 这个
location块用于定义如何处理根路径/下的请求。try_files $uri $uri/ =404;:首先尝试按文件路径处理请求,如果找不到相应的文件或目录,则返回404错误。
location /cgi-bin/note_handler { ... }
- 这个
location块内部处理/cgi-bin/note_handler的请求,并通过proxy_pass将请求转发到http://127.0.0.1。internal;:这个指令表示该路径是内部路径,不能直接从外部访问。proxy_set_header设置了X-Forwarded-For头部为127.0.0.1,通常用于标识原始请求的 IP 地址。
location /cgi-bin/ { ... }
- 这个块定义了对
/cgi-bin/目录下的请求的处理。if ($uri = "/cgi-bin/note_handler") { return 403; }:如果请求的 URI 是/cgi-bin/note_handler,则返回403 Forbidden。expires +1h;:设置响应缓存时间为1小时。limit_rate 10k;:限制响应速率为10KB/s。root /usr/share;:定义此块的根目录为/usr/share。fastcgi_pass和fastcgi_index指定了 FastCGI 处理脚本的位置。include /etc/nginx/fastcgi_params;包含了 FastCGI 的标准配置文件。fastcgi_param SCRIPT_FILENAME $document_root/cgi-bin/http;:设置SCRIPT_FILENAME参数,指定 CGI 脚本的路径。
location /cgi-bin/forward { ... }
- 这个块处理
/cgi-bin/forward请求,并将其代理到http://127.0.0.1/cgi-bin/http?action=print。proxy_set_header X-Forwarded-For 127.0.0.1;:设置了X-Forwarded-For头部为127.0.0.1。proxy_pass http://127.0.0.1/cgi-bin/http?action=print;:将请求代理到指定的 URL。
location /get_flag { ... }
- 这个块处理
/get_flag请求。alias /tmp/flag;:将请求/get_flag映射到/tmp/flag文件。default_type text/plain;:将响应的内容类型设置为text/plain。
cgi脚本信息
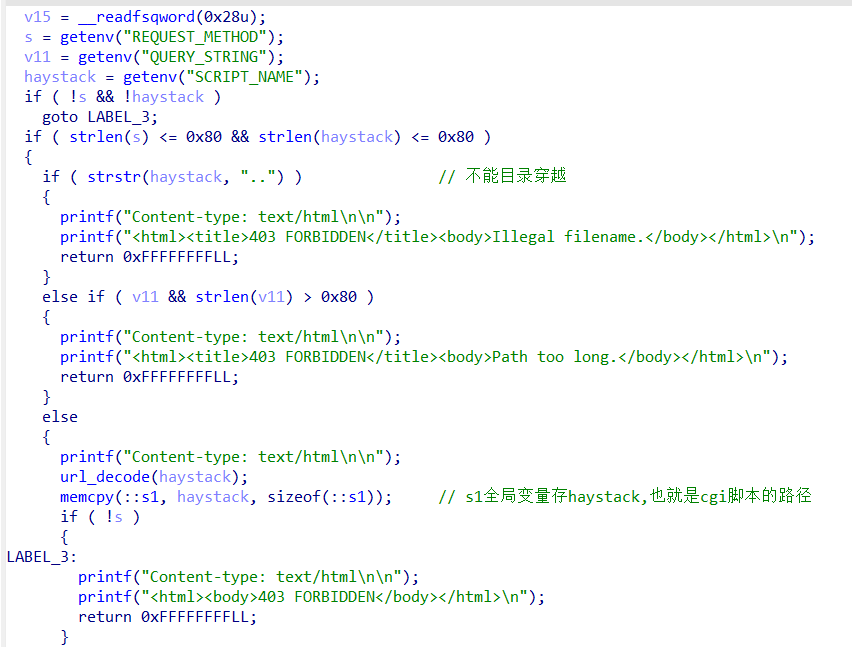
先是通过三个getenv函数获取环境变量。如果我们发起如下的请求
1 | http://example.com/cgi-bin/script?param1=value1¶m2=value2 |
该请求的参数会加入到服务器的环境变量,具体的环境变量值如下:
REQUEST_METHOD:GETQUERY_STRING:param1=value1¶m2=value2SCRIPT_NAME:/cgi-bin/script
后续的几个判断就是限制了各参数的长度,以及限制了用..来进行目录穿越的手段。其中比较重要的就是这个url_decode函数,其作用是进行url解码,也正是这个函数结合Nginx服务器的配置产生了漏洞。
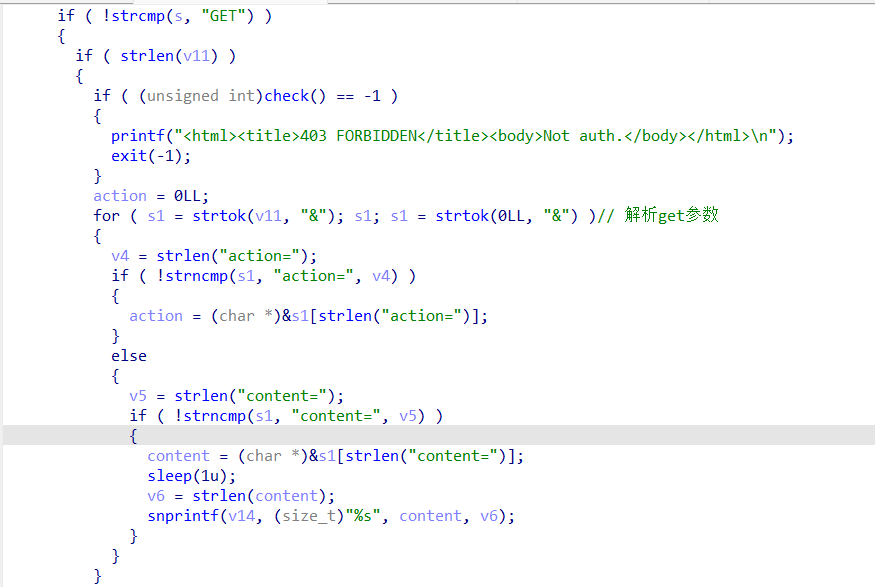
后续先对请求方式进行判断,如果不是GET的话最后会返回<html><title>403 FORBIDDEN</title><body>Method not support.</body></html>这样的页面。后面的循环实现了逐个取出get的参数,其中解析了action以及content这两个参数。而最主要的漏洞也就是发生在content参数会用snprintf(v14, (size_t)"%s", content, v6);来处理,这个函数的参数设置产生了错误,导致格式化字符串%s被当成了一个数字大小来作为存到v14缓冲区的字节数量,而content也就成了解析的格式化字符串,于是产生了格式化字符串漏洞。
然后我们来看看前面有个check函数,这个函数也就是我们需要构造条件来绕过的一个检测函数。
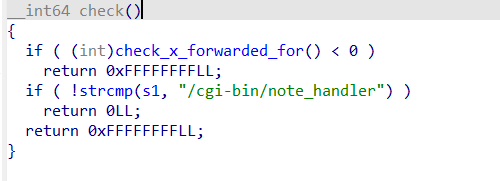
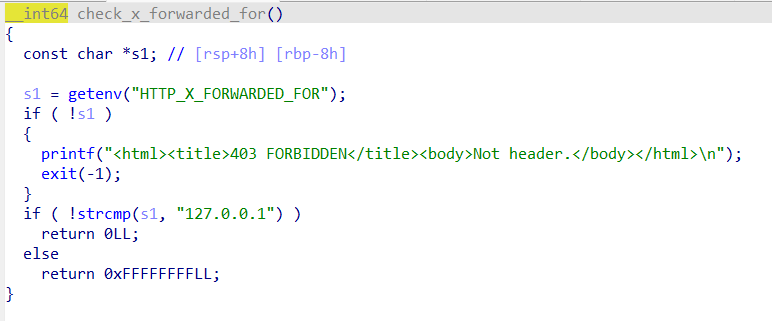
我们发现这里主要做了两个检测,也就是X-Forwarded-For这个http请求头字段要为127.0.0.1。而且s1,也就是之前获取的cgi脚本路径要为/cgi-bin/note_handler。然而之前在nginx配置中/cgi-bin/note_handler有用internal来指定其不能被外部请求访问,绕不开这个就不能进行下一步利用,这该怎么办呢?这时候前面的url_decode就起了作用,我们可以把/cgi-bin/note_handler转成其url编码的形式传入(其实只用编码一个字符就能够绕过检测),此时能够通过如上check函数,因为s1是解码后的url。这里需要注意的是,由于http请求到达nginx服务器时会先进行一次url解码,所以如果我们想要把r进行url编码,直接转成%72是不够的,因为一开始它就被解码然后进location块而过不了检测。我们需要再把%也进行url编码,把r转成%2572输入,那么cgi程序最后调用url_decode后就得到了我们想要的/cgi-bin/note_handler。
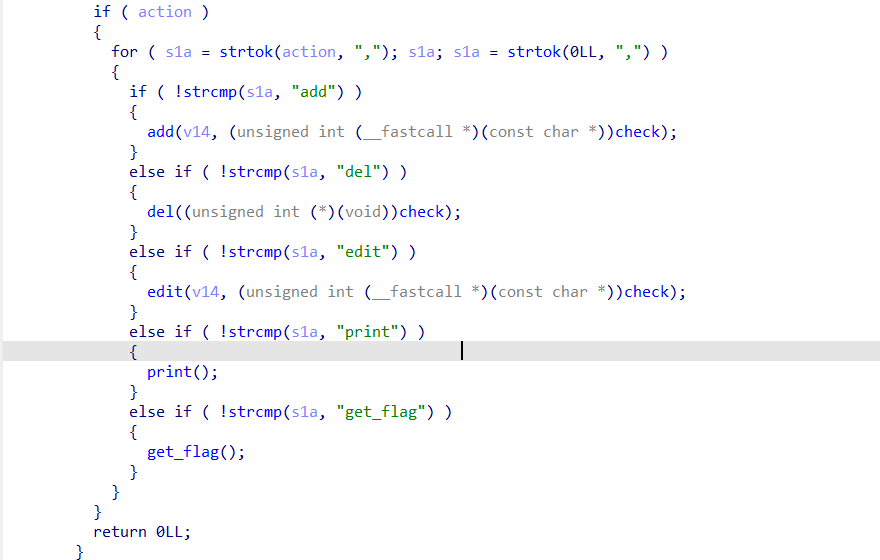
然后就是处理程序的主体逻辑了,使用之前与处理get参数相同的for循环来逐个获取以逗号分割的指令,实现了一个类似堆菜单题的操作。
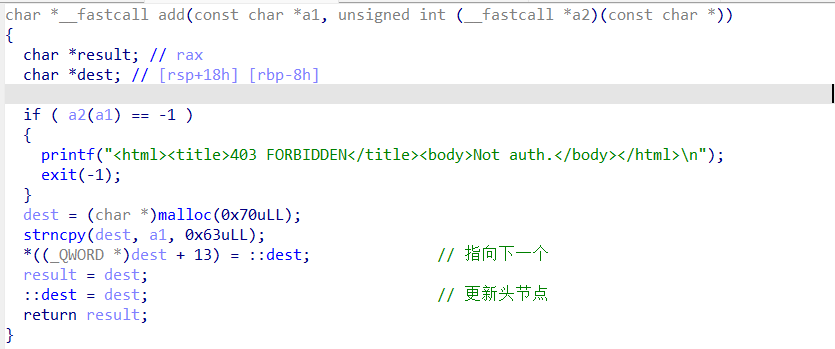
从这个add方法中可以看出,每个add的chunk中都有一个指向下一个节点的next域(*((_QWORD *)dest + 13)这个位置),全局变量dest存的是头节点。
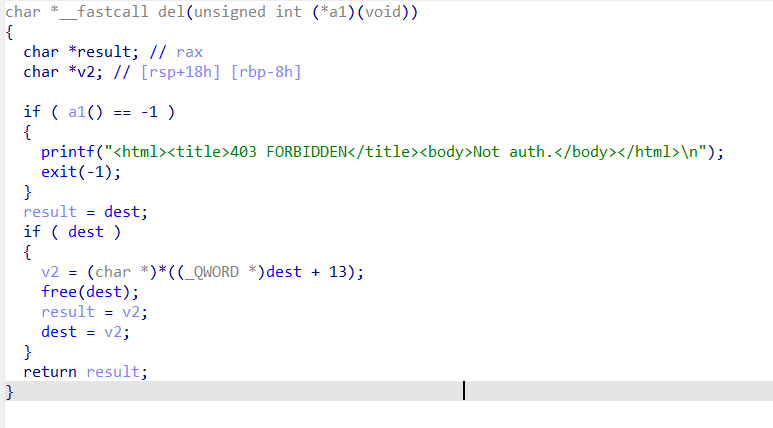
由于是每次释放掉链表头节点,每次都会更新头节点,所以不会有悬挂指针,就不存在UAF。
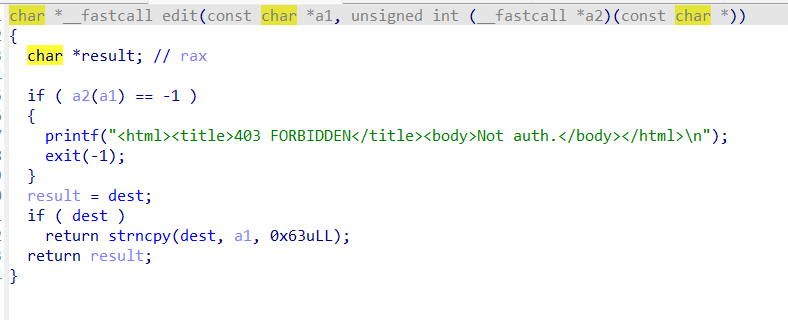
edit功能没啥用,改的内容和原来content里的内容相同。
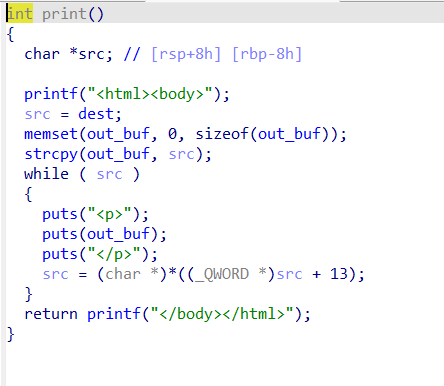
print会遍历整个链表,可以展示每个节点的内容。
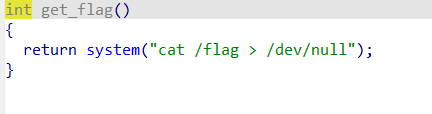
get_flag就是一个后门函数,不过这里把获取到flag的内容重定向到/dev/null丢弃了,直接调用也不会显示flag内容。
利用方式
如何调试
由于在CGI环境中,Web服务器(如Nginx)会将HTTP请求中的某些信息解析并传递给运行的CGI程序作为环境变量。我们这里看到的参数都是通过getenv传递的。所以如果我们像正常做pwn题那样直接对二进制程序进行分析,会发现少了服务器将http请求解析到环境变量这一环节,这时我们需要寻求别的方式来进行调试。
解决方法其实也很容易想到,既然是getenv加载参数,那么我们可以在gdb中直接来设置环境变量,这样之后就是正常的本地环境漏洞分析了。需要注意的是,本地在设置环境变量时都是模拟服务器处理后的参数,比如我们要传/cgi-bin/note_handle%2572,在调试时就要经过一层url解码,传入的是/cgi-bin/note_handle%72。
大致的调试方法如下:
1 | p = process("./http") |
这时我们可能会遇到如下问题
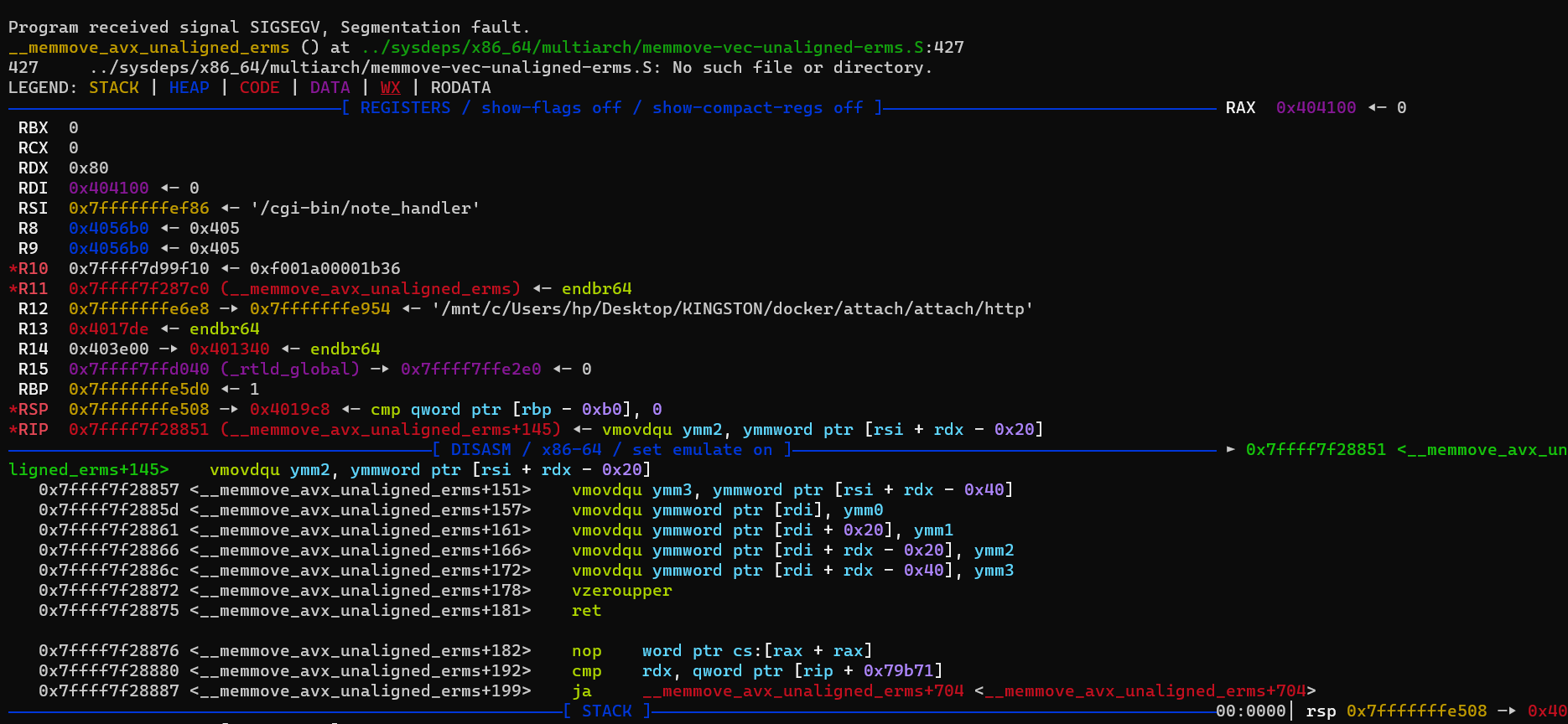
首先猜测是地址对其的问题,这里rsi的值为0x7fffffffef86,rsi+rdx-0x40不是16字节对齐的,我们看看0x7fffffffef86附近的内存布局:
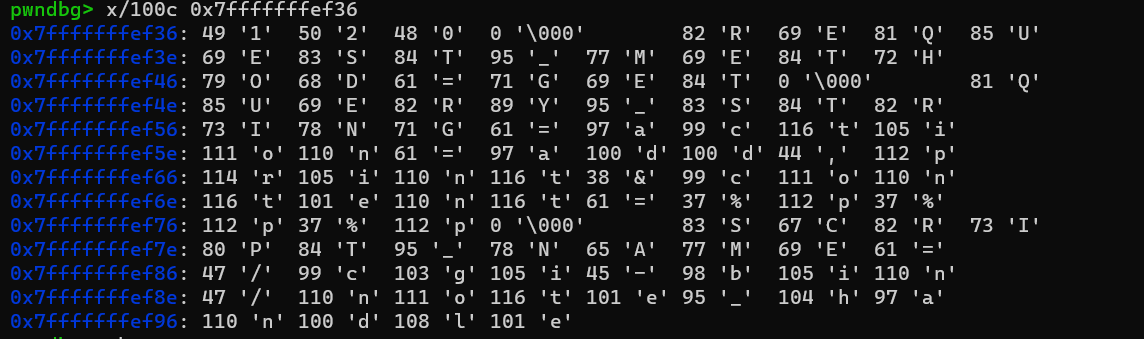
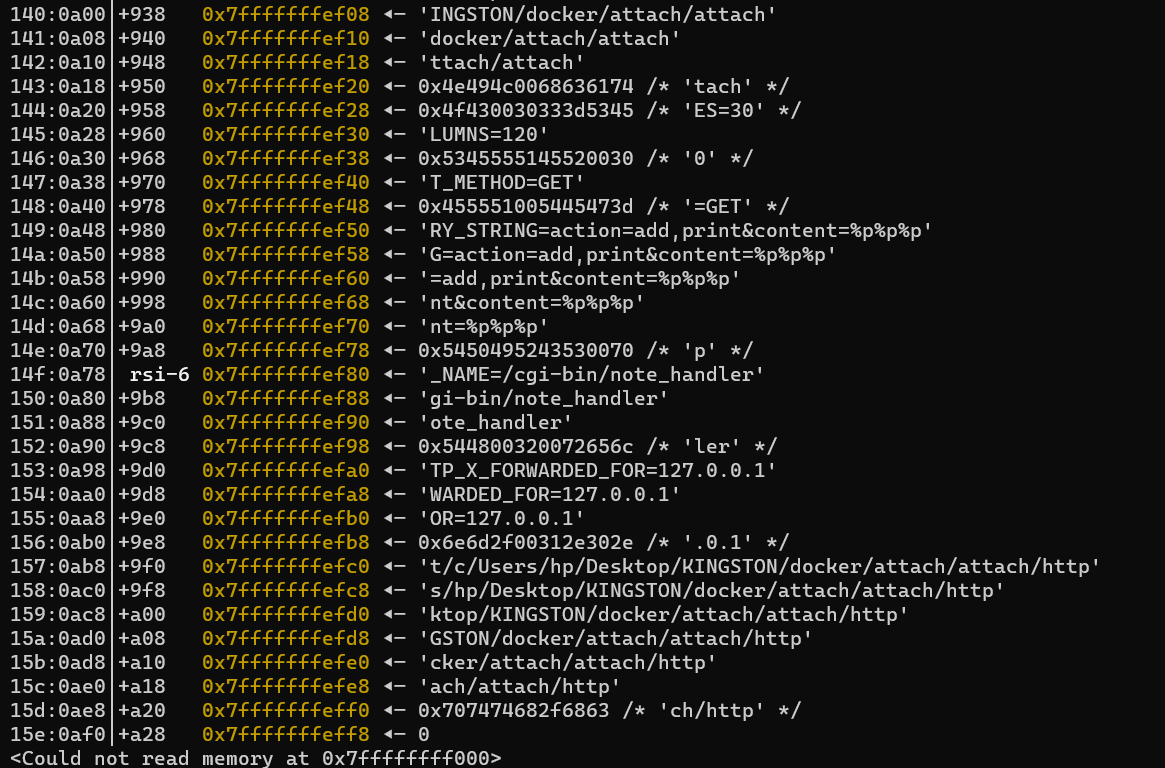
可以发现这个getenv返回的是一个指向环境变量地址的指针,而且环境变量依次存在这个栈段的高地址处。我们可以尝试构造环境变量时使其大小刚好满足对齐条件试试。我首先是尝试把query_string那个环境变量变长从而把后面的script_name弄对齐,但是发现不会改变script_name值的位置。那么就猜测这个环境变量是从高地址往低地址存的,换一下环境变量设置的顺序后再改payload长度。

此时就能不报上述错误继续调试,其实这里我在执行memcpy时rsi指针末位还是f,并没有对齐。这时可能就是原来rsi+rdx-0x40,也就是rsi+0x40这个地址已经越过了环境变量段,是一个不能访问的地址。而调换顺序后rsi+0x40仍然在环境变量这个可访问的地址当中。误打误撞也算是能够过了。(很有意思的是,gdb调试中可以继续,然而执行脚本的主程序的显示却是早早退出,显示403,但只要能够调试就行)。
漏洞利用
为了方便起见,一开始可以直接在print函数上打断点,这样一进去执行一下就能看到格式化字符串漏洞的执行效果。
1 | gdb.attach(p,f''' |
经过调试我们可以确定,我们控制的content中的内容偏移为10。(用AAAAAAAA%10$p测得)
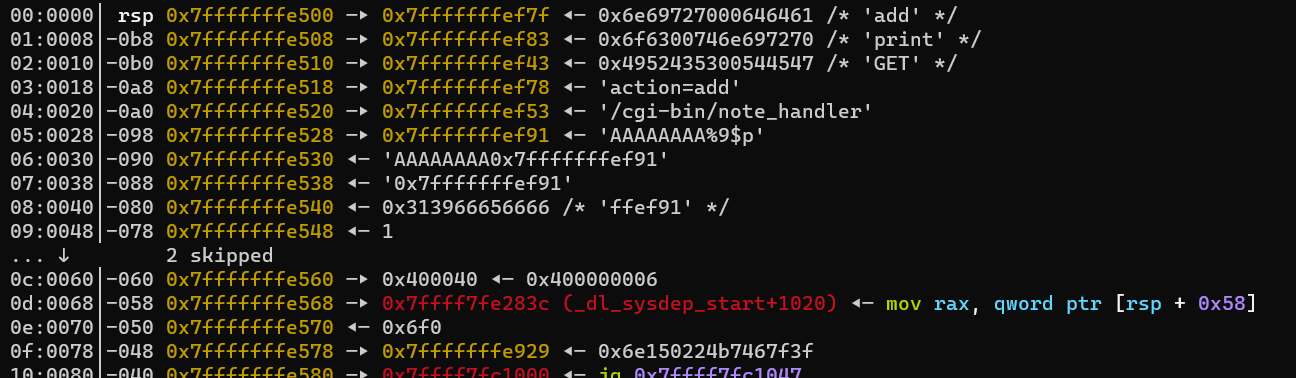
之后修改puts的got表为system就行。
exp
1 | # -*- coding=utf-8 -*- |
2.desktop
xinetd信息
xinetd 配置文件是用于配置和管理 xinetd
服务的文件。xinetd(Extended Internet Service
Daemon)是一个超级服务器守护进程,用于管理和启动各种 Internet 服务(如
FTP、Telnet
等),它可以监听指定的端口并在有连接请求时启动相应的服务。
xinetd配置文件的主要类型
- 主配置文件 (
/etc/xinetd.conf):- 这是
xinetd的全局配置文件,用于设置全局选项,如日志记录、服务目录等。
- 这是
- 服务配置文件 (
/etc/xinetd.d/目录):- 在这个目录中,每个文件定义了一个服务的配置。这些文件可以定义服务的启动方式、端口、协议、运行环境等。我们dockerfile中就有一句COPY ./pwn.xinetd /etc/xinetd.d/pwn,将配置导进去。
1 | service pwn |
相关设置解释
disable = no:
- 表示该服务是启用的。
flags = REUSE:
- 允许重用端口,使得服务能够在连接关闭后快速重新绑定端口。
socket_type = stream:
- 指定服务使用流套接字(即 TCP),用于可靠的双向通信。
protocol = tcp:
- 指定使用 TCP 协议。
wait = no:
- 指定服务不等待新连接,而是立即返回并处理新的连接请求。
user = root:
- 指定服务以 root 用户身份运行。这意味着服务将具有系统上最高权限,因此需要小心安全设置。
type = UNLISTED:
- 表示服务不是标准服务(即不在服务列表中)。
port = 1933:
- 指定服务监听的端口是 1933。我们就是把主机端口映射到这个端口。
bind = 0.0.0.0:
- 表示服务绑定在所有网络接口上,允许来自任何 IP 地址的连接。
server = /usr/sbin/chroot:
- 指定用于运行服务的命令。在这里,
chroot用于创建一个新的根文件系统环境,以限制服务的访问范围。
server_args = --userspec=1000:1000 /home/pwn ./pwn /var/www/html 2>/dev/null:
--userspec=1000:1000:指定以用户 ID 1000 和组 ID 1000 的权限运行pwn程序。根据配置,用户 ID 1000 可能是pwn用户。/home/pwn:指定chroot环境的根目录。./pwn:指定要执行的二进制文件pwn。这个路径相对于/home/pwn。/var/www/html:pwn程序的参数,可能是 Web 服务器的根目录或其他服务相关目录。2>/dev/null:将错误输出重定向到/dev/null,忽略错误信息。
per_source = 5:
- 限制每个源 IP 地址可以启动的服务实例数量为 5 个。
rlimit_cpu = 20:
- 限制服务可以使用的最大 CPU 时间为 20 秒。
rlimit_as = 100M:
- 限制服务使用的最大地址空间为 100 MB。
access_times = 8:50-17:10(注释掉了):
- 如果启用,限制服务的访问时间。
环境搭建踩坑
这里题目给出的镜像如果直接build的话可能会有以下报错
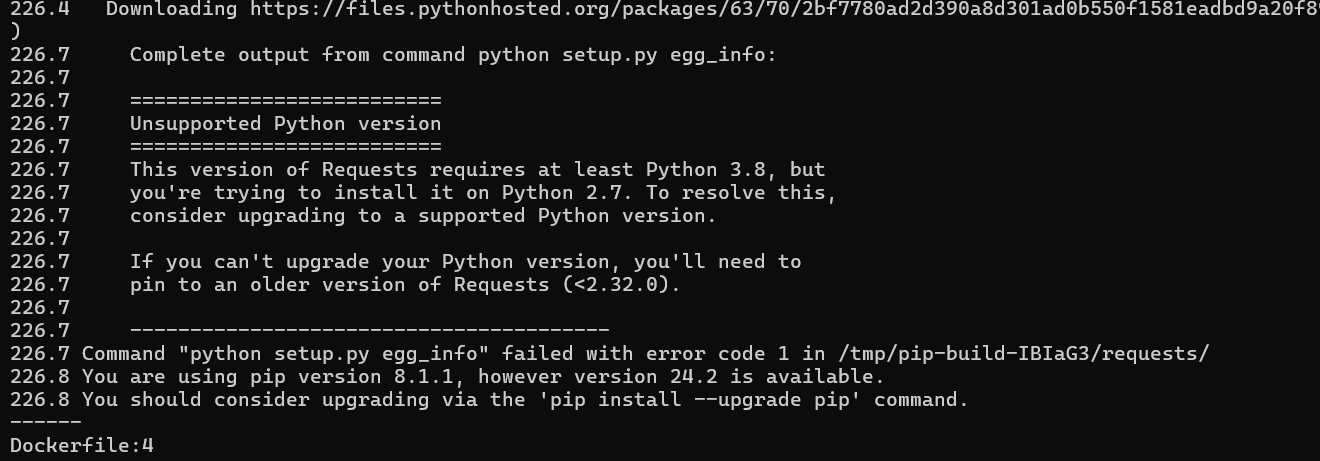
解决方法可以是在dockerfile中手动把requests的版本指定好,我本地requests==2.21.0可以成功构建。
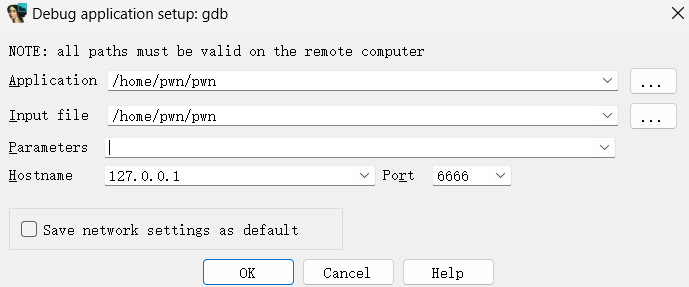
然后IDA调试中,其中上面设置的信息的路径是容器中的路径,然后我用主机的6666端口映射到容器中gdbserver的默认端口
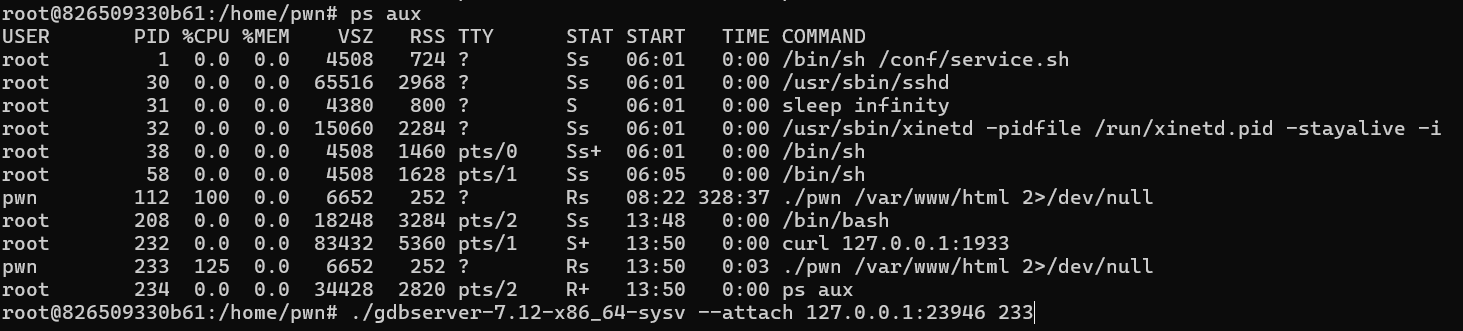
之后patch时除了patch出一个死循环以外,还要把alarm给nop掉,不然会很快退出。
之后要curl连的时候注意在容器中用的端口是它虚拟的端口,而不是主机映射的端口。(这里我把主机1337映射到容器1933端口)

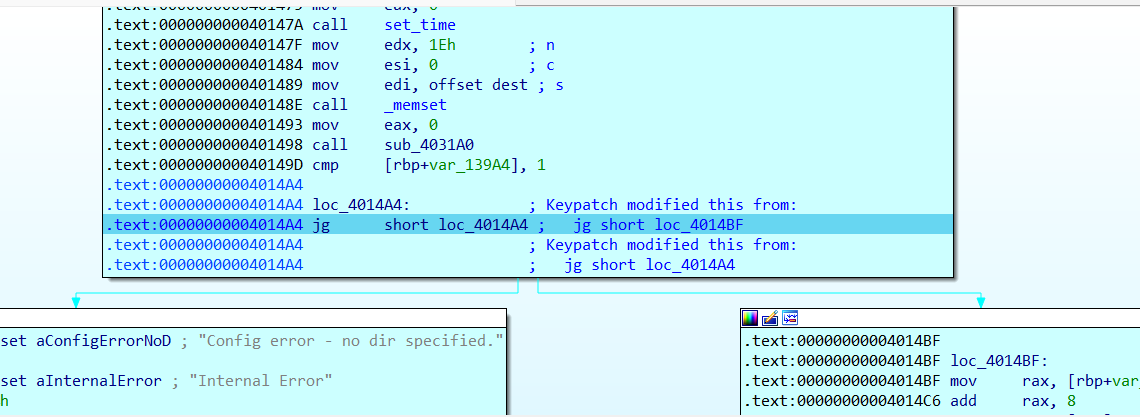
然后把死循环跳转改回来就可以继续调试了。这种方法也可以用于上一题的调试。
题目信息
前面的一些检测正常发包是不会被卡住的,除非curl时手动加上的X-Forwarded-For长度或格式不对。
main函数主要逻辑在这里,其中会从Cgi表中逐个匹配我们所请求的资源名,如果匹配上就检测X-Forwarded-For的值是否为192.168.1.x(x<=20),这里dest全局变量就是存着X-Forwarded-For的值。v21是'?'后面的get请求参数,必须要有。v22是ring_token参数,也必须被设置。之后会调用对应的cgi函数。题目中的cgi函数有那么几个:login.cgi,logout.cgi,wifictl.cgi,logctl.cgi。
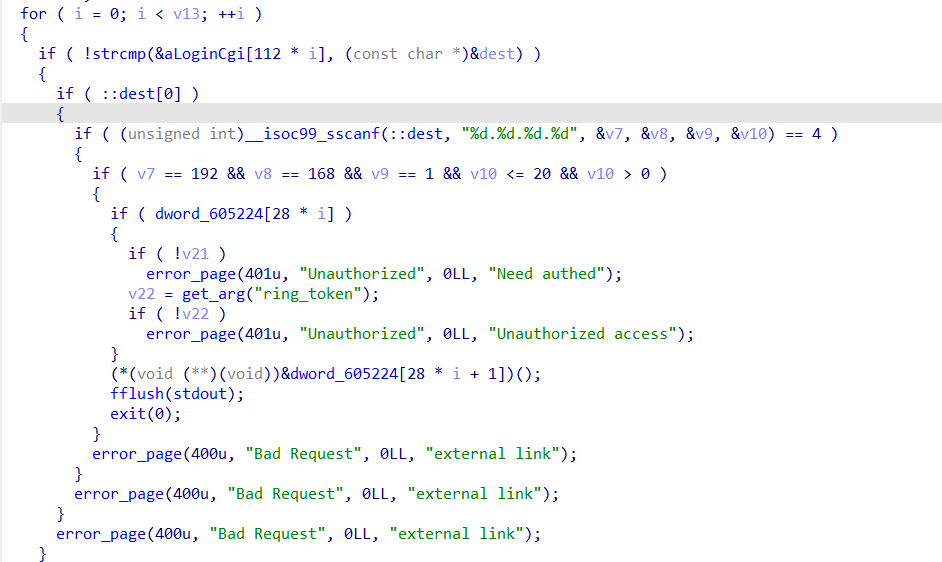
然后我们查看函数表,发现里面有popen危险函数,然后看交叉引用就能找到logctl的具体实现。
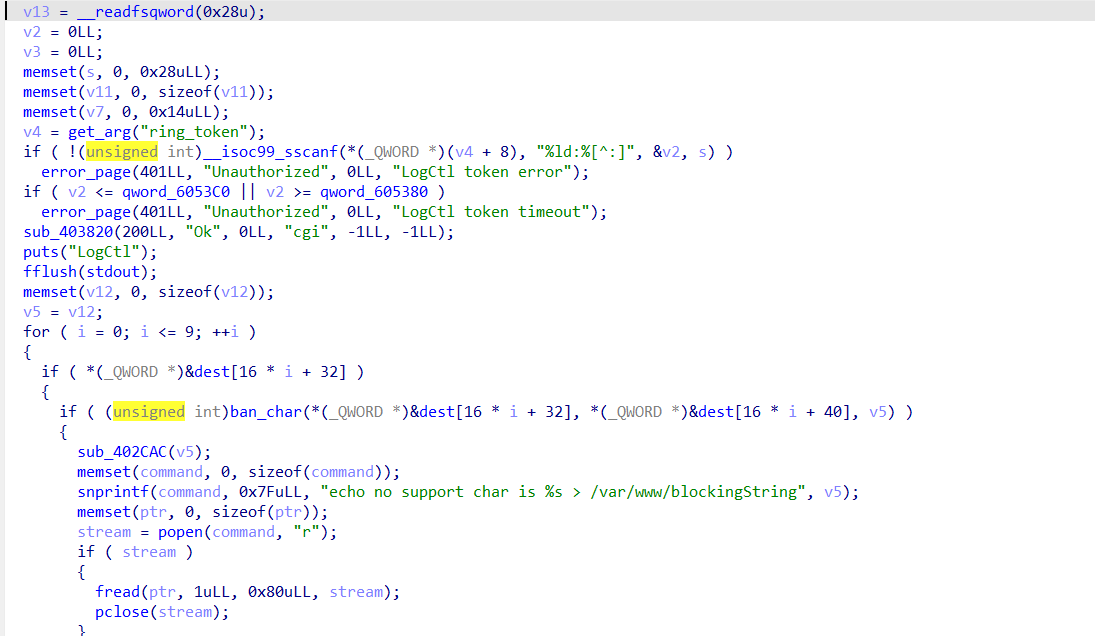
然后就能看到其具体实现,我们的目标就很明确了,想办法实现command的任意控制。
利用方式
这里sscanf函数没见过,查一下是可以以一个格式化字符串匹配,然后把第一个参数分割成若干块存在后面的参数中。
%[^:]表示匹配直到遇到下一个冒号为止的所有字符,并将它们存储在第二个参数指定的字符数组中。
首先得绕过logctl函数中前面两个判断,token的格式必须为
数字:数字,然后:前面的数字会和两个值进行比较,要在范围外才能过。那么我们继续看交叉引用。
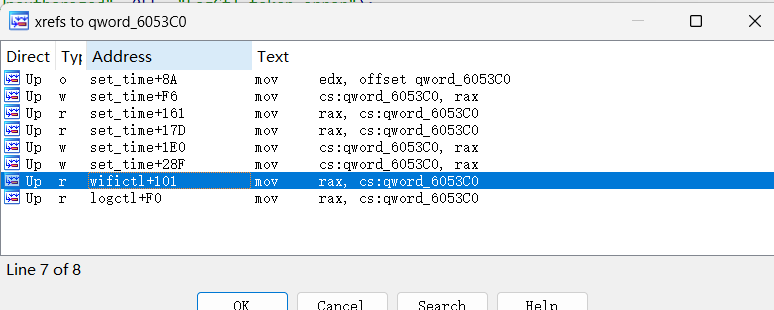
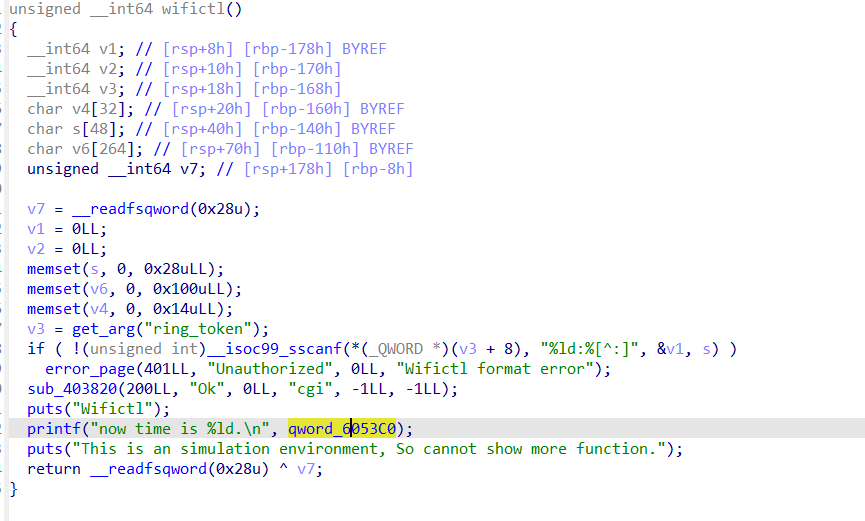
发现是一个时间值,而且如果调用wifictl会把这个值打印出来。那么只要先访问这个cgi,就可以得到time的值,而另一端边界值固定为0x3c,那么我们设置token前半部分为time+1就行。
之后发现command的值与v5有关,sub_402CAC这个函数会获取特殊字符,而前面的ban_char函数则是漏洞所在点。

主体逻辑是判断是否有v12中存的非法字符,我们通过logctl本体中echo no support char is %s > /var/www/blockingString就能猜测这个逻辑。但是strcpy(s,a2)没有长度限制,可以溢出写v14,最后又会把v14写回a3,也就是v5,就实现了对command的控制。a2就是我们get传的参数值,上面会进行遍历参数键值对,所以我们用哪个参数触发漏洞都行。
之后就能直接打了,由于是与web服务器交互,所以要用request库进行exp编写。这里我也懒得再写一份exp了,直接用提供的exp,改个端口,能正常获取flag。
exp
1 | import warnings |
- 标题: webpwn
- 作者: collectcrop
- 创建于 : 2024-09-21 21:21:04
- 更新于 : 2024-09-21 21:35:45
- 链接: https://collectcrop.github.io/2024/09/21/webpwn/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
