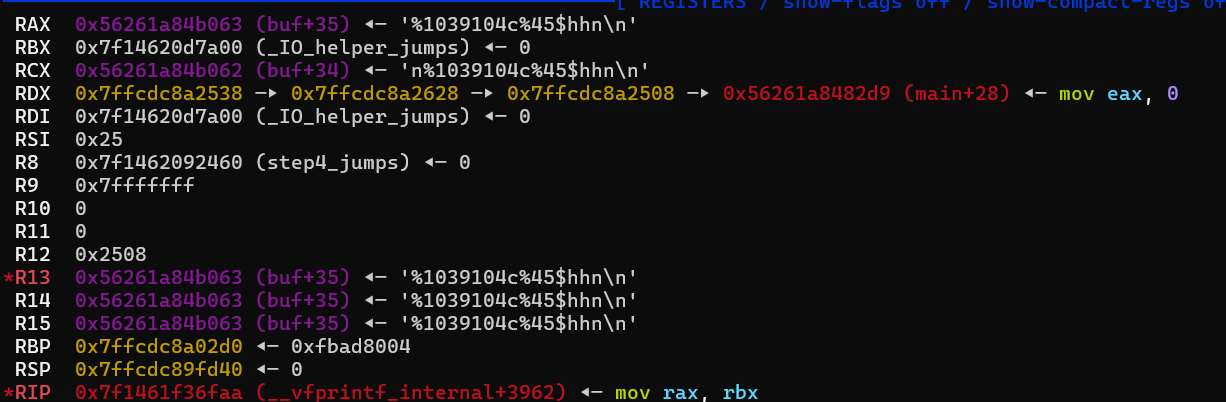
/* Write formatted output to stdout from the format string FORMAT. */ /* VARARGS1 */ int __printf (constchar *format, ...) { va_list arg; //声明一个 va_list 类型的变量 arg,用于存储可变参数列表。 int done; //写入的字符数或其他状态信息。
然后会检查文件流 s
是否处于无缓冲模式,如果处于无缓冲模式,代码调用一个辅助函数
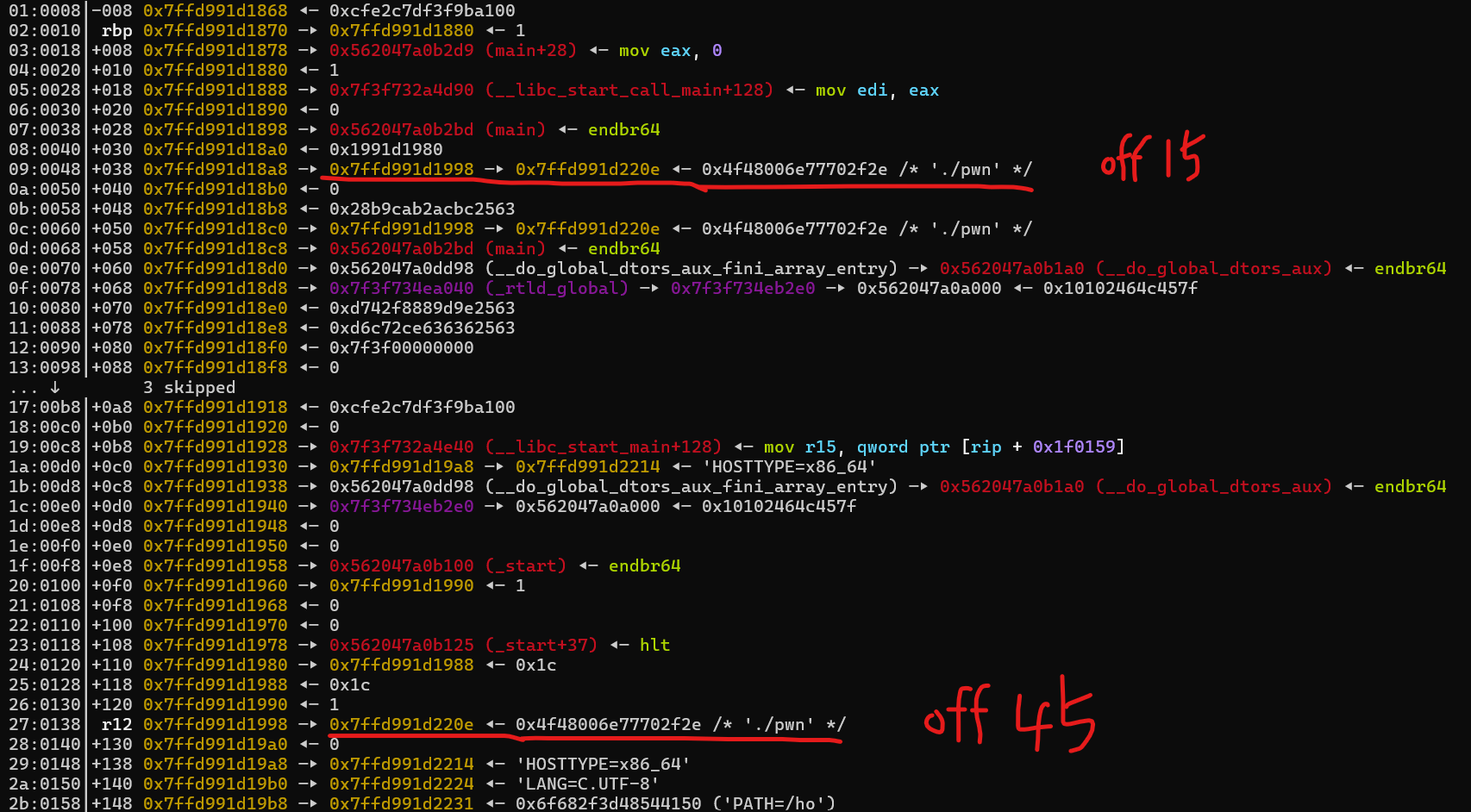
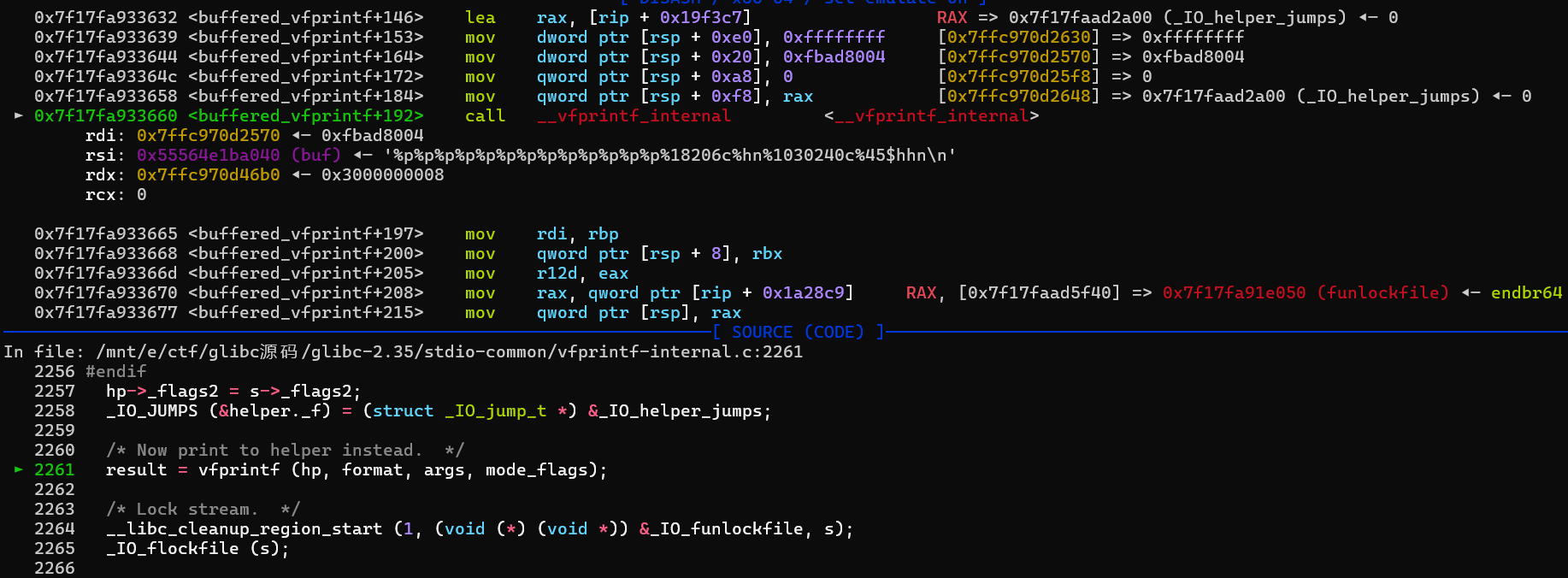
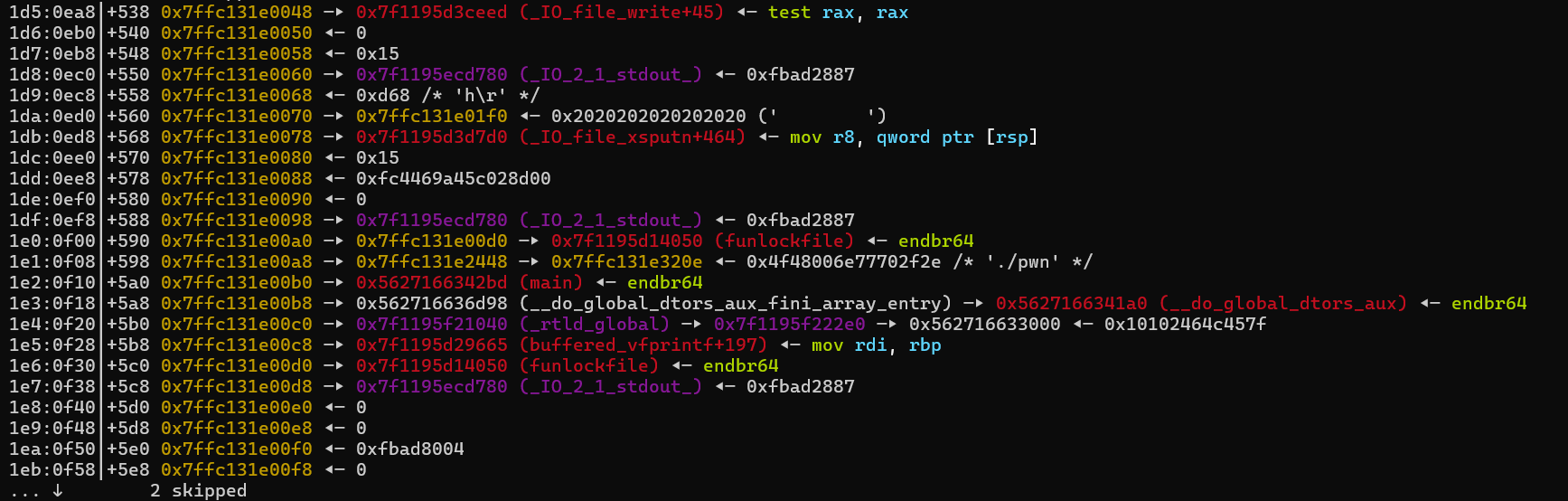
buffered_vfprintf。这个函数的作用是为该流分配一个局部临时缓冲区,然后重新调用原来的格式化输出函数。这样可以在处理输出时提供一个缓冲层,即使原始流不支持缓冲。这里我们调试时会进到buffered_vfprintf里面,最后实际还会调用回vfprintf。
1 2 3 4
if (UNBUFFERED_P (s)) /* Use a helper function which will allocate a local temporary buffer for the stream and then call us again. */ return buffered_vfprintf (s, format, ap, mode_flags);
然后会判断代码是否支持宽字符的处理,然后查找格式字符串中的第一个格式说明符。
1 2 3 4 5 6 7
#ifdef COMPILE_WPRINTF /* Find the first format specifier. */ f = lead_str_end = __find_specwc ((const UCHAR_T *) format); #else /* Find the first format specifier. */ f = lead_str_end = __find_specmb ((const UCHAR_T *) format); #endif
后面也有类似的,但是会自增f,用于逐个解析。
1 2 3 4 5 6 7 8 9 10
/* Get current character in format string. */ JUMP (*++f, step0_jumps); ...... #ifdef COMPILE_WPRINTF f = __find_specwc ((end_of_spec = ++f)); #else f = __find_specmb ((end_of_spec = ++f)); #endif /* Write the following constant string. */ outstring (end_of_spec, f - end_of_spec);
/* Process 'l' modifier. There might another 'l' following. */ LABEL (mod_long): is_long = 1; JUMP (*++f, step3b_jumps);
/* Process 'L', 'q', or 'll' modifier. No other modifier is allowed to follow. */ LABEL (mod_longlong): is_long_double = 1; is_long = 1; JUMP (*++f, step4_jumps);
处理 h 修饰符:
LABEL (mod_half)
当遇到 h 修饰符时,将 is_short 设置为
1,表示后续的参数应被视为 short int 类型。
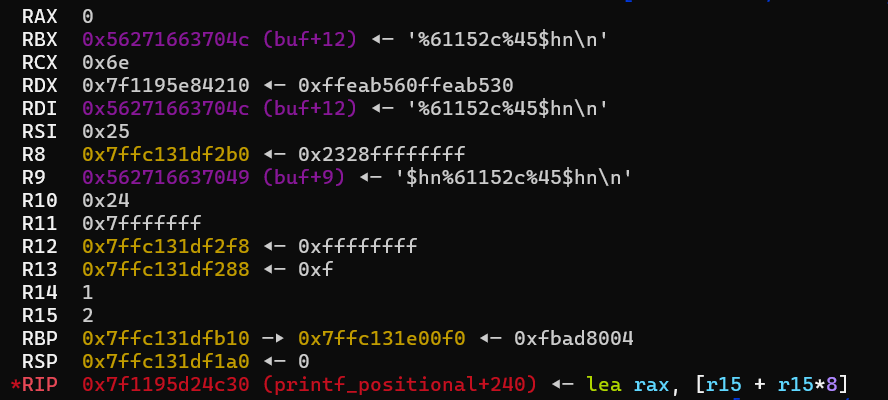
for (cnt = 0; cnt < nspecs; ++cnt) { /* If the width is determined by an argument this is an int. */ if (specs[cnt].width_arg != -1) args_type[specs[cnt].width_arg] = PA_INT;
/* If the precision is determined by an argument this is an int. */ if (specs[cnt].prec_arg != -1) args_type[specs[cnt].prec_arg] = PA_INT;
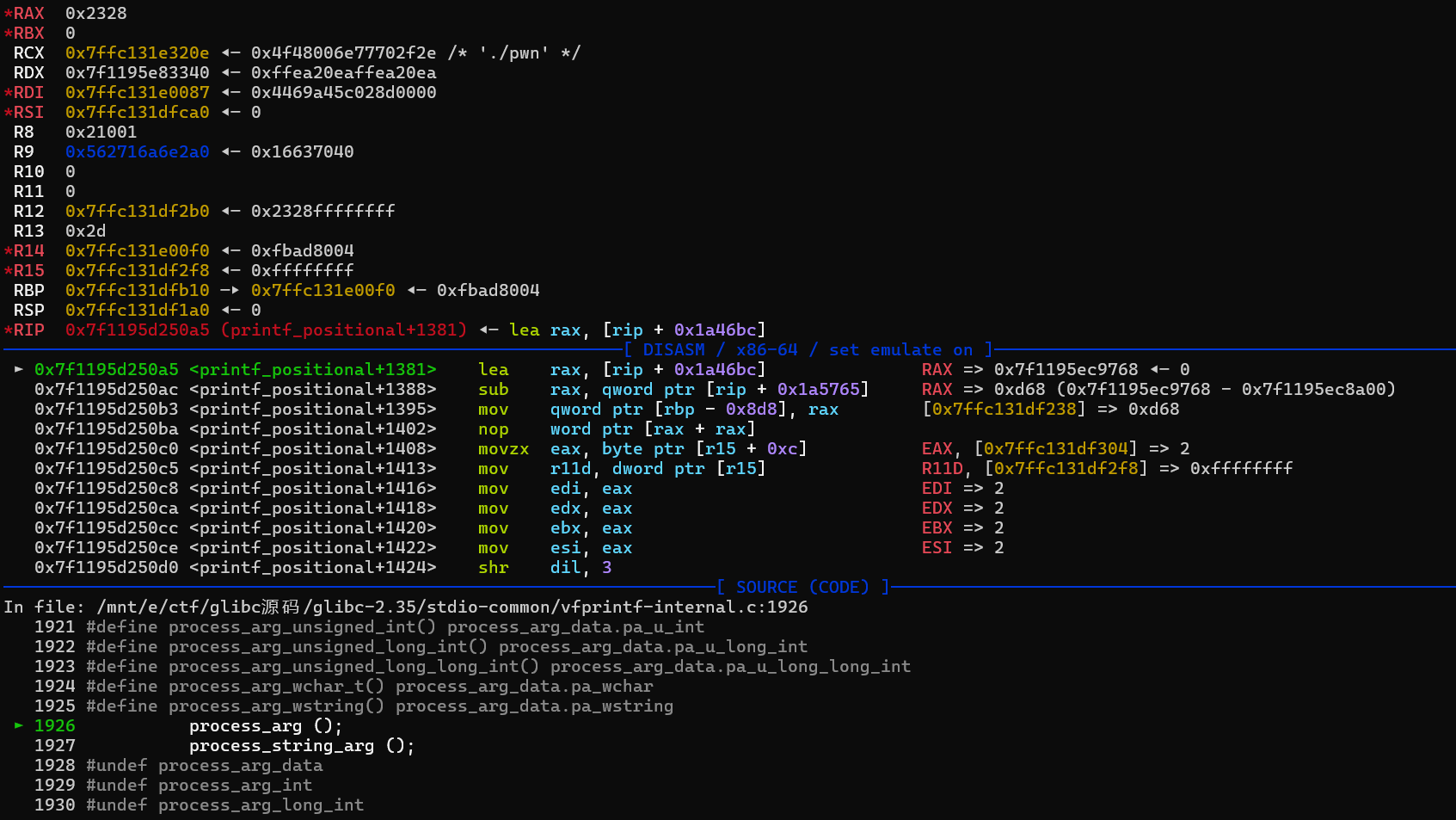
switch (specs[cnt].ndata_args) { case0: /* No arguments. */ break; case1: /* One argument; we already have the type and size. */ args_type[specs[cnt].data_arg] = specs[cnt].data_arg_type; args_size[specs[cnt].data_arg] = specs[cnt].size; break; default: /* We have more than one argument for this format spec. We must call the arginfo function again to determine all the types. */ (void) (*__printf_arginfo_table[specs[cnt].info.spec]) (&specs[cnt].info, specs[cnt].ndata_args, &args_type[specs[cnt].data_arg], &args_size[specs[cnt].data_arg]); break; } -------------------------------------------------------------------------------------------------- for (cnt = 0; cnt < nargs; ++cnt) switch (args_type[cnt]) { #define T(tag, mem, type) \ case tag: \ args_value[cnt].mem = va_arg (*ap_savep, type); \ break
T (PA_WCHAR, pa_wchar, wint_t); case PA_CHAR: /* Promoted. */ case PA_INT|PA_FLAG_SHORT: /* Promoted. */ #if LONG_MAX == INT_MAX case PA_INT|PA_FLAG_LONG: #endif T (PA_INT, pa_int, int); #if LONG_MAX == LONG_LONG_MAX case PA_INT|PA_FLAG_LONG: #endif T (PA_INT|PA_FLAG_LONG_LONG, pa_long_long_int, longlongint); #if LONG_MAX != INT_MAX && LONG_MAX != LONG_LONG_MAX # error"he?" #endif case PA_FLOAT: /* Promoted. */ T (PA_DOUBLE, pa_double, double); case PA_DOUBLE|PA_FLAG_LONG_DOUBLE: if (__glibc_unlikely ((mode_flags & PRINTF_LDBL_IS_DBL) != 0)) { args_value[cnt].pa_double = va_arg (*ap_savep, double); args_type[cnt] &= ~PA_FLAG_LONG_DOUBLE; } #if __HAVE_FLOAT128_UNLIKE_LDBL elseif ((mode_flags & PRINTF_LDBL_USES_FLOAT128) != 0) args_value[cnt].pa_float128 = va_arg (*ap_savep, _Float128); #endif else args_value[cnt].pa_long_double = va_arg (*ap_savep, longdouble); break; case PA_STRING: /* All pointers are the same */ case PA_WSTRING: /* All pointers are the same */ T (PA_POINTER, pa_pointer, void *); #undef T default: if ((args_type[cnt] & PA_FLAG_PTR) != 0) args_value[cnt].pa_pointer = va_arg (*ap_savep, void *); elseif (__glibc_unlikely (__printf_va_arg_table != NULL) && __printf_va_arg_table[args_type[cnt] - PA_LAST] != NULL) { args_value[cnt].pa_user = alloca (args_size[cnt]); (*__printf_va_arg_table[args_type[cnt] - PA_LAST]) (args_value[cnt].pa_user, ap_savep); } else memset (&args_value[cnt], 0, sizeof (args_value[cnt])); break; case-1: /* Error case. Not all parameters appear in N$ format strings. We have no way to determine their type. */ assert ((mode_flags & PRINTF_FORTIFY) != 0); __libc_fatal ("*** invalid %N$ use detected ***\n"); }