Algorithmica-HPC研读记录2
Algorithmica HPC研读记录(4-6章)
四、编译(Compilation)
概述
学习汇编语言的主要好处并不在于能够用它编写程序,而是在于理解编译后的代码在执行过程中发生了什么,以及它对性能的影响。
在极少数情况下,我们确实需要手写汇编代码以达到最高性能,但大多数时候,编译器本身就能生成接近最优的代码。如果编译器未能做到这一点,通常是因为程序员比编译器掌握了更多关于问题的特定知识,但却未能通过源代码有效地传达这些信息。
在本章中,我们将讨论如何让编译器精确地按照我们的意图生成代码,并探讨如何收集有助于进一步优化的有用信息。
编译阶段
在直接讨论编译器优化之前,让我们先简要回顾一下“整体流程”。将 C 代码转换为可执行文件的过程大致可分为四个阶段:
预处理(Preprocessing) 预处理阶段会展开宏(macros)、从头文件中引入源代码,并去除源代码中的注释。可以使用以下命令查看预处理后的代码:
1
gcc -E source.c
这会将预处理后的源代码输出到标准输出(stdout)。
编译(Compiling) 编译器会解析源代码,检查语法错误,并将代码转换为中间表示(Intermediate Representation,IR)。在此过程中,它还会进行一些优化,并最终将 IR 翻译成汇编代码。可以使用以下命令生成汇编文件:
1
gcc -S file.c
这将产生一个扩展名为
.s的汇编代码文件。汇编(Assembly) 这一阶段会将汇编代码转换为机器码(machine code)。需要注意的是,此时所有外部函数调用(如
printf)仍然是占位符,并未真正解析。可以使用以下命令进行汇编:1
gcc -c file.c
这会生成一个
.o(目标文件,Object File)。链接(Linking) 最后,链接器会解析所有函数调用,并填充它们的真实地址,从而生成最终的可执行文件:
1
gcc -o binary file.c
这将生成一个可执行的二进制文件
binary。
在这四个阶段的每一个阶段,都有可能通过不同的方式来优化程序的性能。
编译选项与目标平台
过程间优化(Interprocedural Optimization)
我们之所以有链接(linking)这个最后阶段,是因为逐个文件进行编译再进行链接,既更容易实现,也更快。这种方式可以并行编译多个文件,并缓存中间结果,提高编译效率。
此外,它还允许代码以库(library)的形式分发,库可以是静态的,也可以是共享的:
- 静态库(Static Libraries) 静态库就是一组预编译的目标文件(object files)的集合,编译器会将它们与其他源代码合并,最终生成一个单一的可执行文件,就像正常编译时那样。
- 动态库或共享库(Dynamic/Shared Libraries) 共享库是预编译的可执行文件,其中包含额外的元信息(meta-information),用于标识库中的可调用函数和数据。这些引用会在运行时(runtime)解析。正如其名称所示,这种方式允许多个程序共享已编译的二进制代码。
使用静态库的主要优势是可以执行各种过程间优化(interprocedural optimizations),这些优化需要比普通库函数签名更多的上下文信息,例如:
- 函数内联(Function Inlining)
- 无用代码消除(Dead Code Elimination)
要强制链接器(linker)仅查找和接受静态库,可以使用
-static 选项,例如:
1 | gcc -static -o my_program my_program.c -lmylib |
链接时优化(Link-Time Optimization, LTO)
这一过程被称为链接时优化(LTO)。现代编译器在目标文件(object files)中存储了一种中间表示(intermediate representation, IR),因此可以在整个程序的层面进行轻量级优化。
此外,LTO 还允许在不同的编程语言之间进行优化——只要它们的编译器使用相同的中间表示,就可以进行跨语言优化。
LTO 是一个相对较新的特性(GCC 直到2014 年左右才支持),但它仍然远未完善。在 C 和 C++ 中,为了确保不会因独立编译(separate compilation)损失性能,一种解决方案是创建仅包含头文件的库(header-only library)。
头文件库(Header-Only Library)的特点:
- 仅由头文件(
.h或.hpp)组成,包含所有函数的完整定义,而不仅仅是声明。 - 只需直接包含(
#include)这些头文件,编译器就能访问所有可用的优化。 - 缺点是每次编译时都必须重新编译库的代码,但它确保了不会丢失性能,并且提供了更好的控制权。
1. 为什么需要 LTO?
通常,我们编译 C/C++ 程序时是逐个文件进行编译,然后在链接时合并这些编译结果。但这样会有一个问题:编译器只能在单个源文件内进行优化,它无法跨文件进行全局优化。例如:
1 | // lib.c |
在单文件编译时,编译 main.c 时无法看到
add()
的具体实现,因此它不会进行内联优化,而是必须生成函数调用指令。
但是,LTO 允许编译器在链接阶段看到整个程序的代码,从而进行:
- 跨文件内联(Cross-File Inlining)
- 跨文件常量传播(Cross-File Constant Propagation)
- 消除未使用的代码(Dead Code Elimination)
2. 静态库 vs 共享库
| 特性 | 静态库(Static Library) | 共享库(Shared Library) |
|---|---|---|
| 链接方式 | 编译时合并到可执行文件中 | 运行时动态加载 |
| 可执行文件大小 | 较大(包含所有库代码) | 较小(只包含引用) |
| 运行时性能 | 更快(所有代码已加载) | 略慢(可能需要动态加载) |
| 更新库的影响 | 需要重新编译整个程序 | 直接替换库文件即可生效 |
| 是否支持 LTO | 支持(可优化跨文件调用) | 不支持(只知道函数签名) |
对于性能敏感的程序(如游戏引擎、嵌入式系统),通常会选择静态库 + LTO,以最大化优化。 对于需要动态更新的程序(如操作系统、应用程序),则更倾向于共享库,以减少存储占用并方便维护。
3. 头文件库(Header-Only Library)
头文件库是一种特殊的优化方式,它的优点是:
- 所有代码都可见,编译器能进行最大程度的优化(比如内联和常量折叠)。
- 避免了 LTO 可能带来的编译器兼容性问题。
- 使用方便,只需
#include头文件即可,无需额外的编译步骤。
但它的缺点是:
- 每次编译都要重新编译库的代码,可能会导致编译时间变长。
- 难以控制 ABI 兼容性,更新库时可能会影响已编译的代码。
优化级别
GCC 主要提供 4.5 个主要的优化级别,用于 优化程序运行速度:
| 优化级别 | 作用 |
|---|---|
-O0(默认) |
不进行优化(但实际上优化了 编译时间)。 |
-O1(或 -O) |
启用一些简单优化,几乎 不影响编译时间,但能提升性能。 |
-O2 |
启用所有已知的、不会引入负面影响的优化,且优化时间较合理(生产环境常用)。 |
-O3 |
启用几乎所有正确的优化,但编译时间可能更长,某些优化可能不适用于所有场景。 |
-Ofast |
包含 -O3 的所有优化,再加上一些
可能违反标准但大多数情况下无害的优化(如
浮点运算重排,可能导致
少量精度丢失)。 |
此外,GCC 还有 许多其他优化选项,但它们 过于特殊,默认情况下不会启用,甚至在某些情况下会 降低性能。在接下来的章节,我们会讨论其中的一些高级优化选项。
指定目标架构(Specifying Targets)
接下来,我们希望告诉编译器更多关于代码将在哪些计算机上运行的信息。支持的平台范围越小,优化效果越好。默认情况下,编译器会生成可以在 任何 2000 年以后发布的 x86 处理器 上运行的二进制文件。
最简单的方式 来缩小适用范围是使用
-march 选项来指定确切的微架构。例如:
1 | -march=haswell # 生成适用于 Haswell 微架构的代码 |
如果你是在同一台将运行程序的计算机上进行编译,可以使用
-march=native 让编译器自动检测本机 CPU
并生成相应的优化代码。
由于指令集通常是向后兼容的,因此通常只需要指定最老的微架构即可。例如,如果你的目标平台范围包括
Haswell 及更新的 CPU,使用 -march=haswell
就可以确保所有更老的 CPU 仍然可以运行。
另一种更精细的方式是直接列出 你希望使用的特定指令集,例如:
1 | -mavx2 # 启用 AVX2 指令集 |
如果你仅仅想针对某个 CPU 进行优化,但仍希望它可以在其他 CPU
上运行,可以使用 -mtune 选项,例如:
1 | -mtune=haswell |
与 -march 不同,-mtune
只是优化,不会使用不兼容的指令,所以不会导致程序在不支持的 CPU
上崩溃。 (注意:默认情况下,-march=x
也会隐含 -mtune=x,即自动优化目标 CPU。)
除了在编译时传递这些参数,也可以直接在代码中使用
#pragma 指令:
1 |
这种方法适用于仅优化特定的高性能函数,也就是局部优化,而不影响整个项目的编译时间。
有时候,你可能希望在同一个库中提供多个针对不同 CPU 架构优化的实现。
我们可以使用基于 __attribute__
的语法,让编译器自动选择最合适的函数版本:
1 | __attribute__(( target("default") )) // 默认回退实现 |
在 Clang 编译器中,不能使用 #pragma
直接在代码中设置目标架构和优化选项, 但可以像 GCC
一样使用 __attribute__
来实现多版本函数。
条件优化
条件优化不完全符合标准,而且对具体场景依赖性很强,需要程序员提供额外的信息来判断是否启用。所以即使开了O3优化编译器也不会默认采用这些优化方式。
循环展开
循环展开是一种编译器优化技术,它减少循环控制的开销,通过复制循环体的代码来减少循环的迭代次数。这样可以减少
cmp(比较)、jmp(跳转)等指令的执行,提高 CPU
指令流水线的效率。
默认情况下是关闭的,除非:
- 迭代次数是编译时的常数(例如
for (int i = 0; i < 4; i++))。 - 在这种情况下,GCC 可能会完全去掉循环,直接替换成一系列不带跳转的指令。
如何启用循环展开?
(1)使用编译选项
1 | -funroll-loops |
- 让编译器尝试展开所有已知迭代次数的循环(包括编译时可知和运行时进入循环时可知的)。
- 但这会增加二进制文件大小,并不总是提高性能。
(2)使用 #pragma 控制单个循环
如果只想对某个特定循环展开,可以使用
#pragma:
1 |
|
- 这里
#pragma GCC unroll 4告诉编译器展开 4 次迭代。 - 适用于
n较大且无法静态确定的情况。
内联函数
函数内联是一种优化技术,它将函数调用替换为函数体本身,从而减少函数调用的开销(如参数传递、栈操作等)。
在 C/C++ 中,可以使用 inline
关键字提示编译器进行内联:
1 | inline int square(int x) { |
- 编译器可能会忽略
inline,如果它认为内联后不会提高性能或代码膨胀太严重。 - 适用于短小、频繁调用的函数(例如
math函数)。
如果一定要让编译器强制内联,可以使用
__attribute__((always_inline)):
1 |
|
- 这会强制编译器内联,除非编译器优化级别不允许(如
-O0)。 - 适用于性能关键代码(如高频调用的
getter/setter)。
分支可能性提示
从 C++20 开始,[[likely]] 和
[[unlikely]]
属性可以用来提示编译器某个分支是否更可能被执行。这对提高分支预测的准确性和优化性能非常有帮助。
1 | int factorial(int n) { |
[[likely]]表示此分支更有可能发生。[[unlikely]]表示此分支不太可能发生。
这告诉编译器如何生成更高效的代码,尤其是在有多个条件判断时。
在 C++20 之前,GCC 提供了
__builtin_expect
函数来告诉编译器分支的可能性:
1 | int factorial(int n) { |
__builtin_expect函数的第二个参数表示“预测值”:
1表示该分支“更可能发生”。0表示该分支“不太可能发生”。
这虽然是编译器的内建功能,但并没有像 [[likely]] 和
[[unlikely]] 那样成为 C++
标准的一部分,使用时需要依赖编译器的特定实现。
PGO
Profile-Guided Optimization (PGO) 是一种利用实际运行数据来优化程序性能的技术。通过收集程序在运行时的数据(例如分支的执行频率、函数调用次数、循环迭代次数等),编译器可以做出更有针对性的优化决策,从而超过仅通过静态分析所能实现的优化效果。
PGO 的基本流程包括以下步骤:
- 生成分析数据:编译程序并在实际数据上运行,通过添加计时器和计数器来收集数据。
- 使用分析数据优化编译:使用从第一次运行中收集到的 profiling 数据重新编译程序。
步骤 1:生成 Profiling 数据
使用 -fprofile-generate 标志,GCC 会在程序中插入
profiling
代码,生成能够跟踪执行情况的数据文件。假设你在编译源代码时使用如下命令:
1 | g++ -fprofile-generate [其他编译选项] source.cc -o binary |
然后运行该程序,理想情况下使用与真实场景接近的数据输入,这样生成的数据才具有代表性。运行程序后,会生成
.gcda 文件,这些文件包含了测试运行期间的 profiling
数据。
步骤 2:基于 Profiling 数据优化编译
在第二次编译时,使用 -fprofile-use
标志,这样编译器就能使用第一次运行中收集到的 profiling
数据来进行优化:
1 | g++ -fprofile-use [其他编译选项] source.cc -o binary |
这时,编译器能够利用收集到的信息做出更加精准的优化。PGO 可以显著提升程序的执行效率,尤其是在大型代码库中,通常可以带来 10-20% 的性能提升。由于这种优化是基于实际数据的,它能比传统的静态优化方法更有效。对于性能至关重要的项目,PGO 是一个常见的优化手段。
契约式编程
在 Java 和 Rust
这样的“安全”语言中,通常对每个可能的操作和输入都有明确的行为定义。有些细节(如哈希表的键顺序或
std::vector
的增长因子)可能会因实现不同而有所不同,但这些通常只是为了性能优化而留给实现的细节。
相比之下,C 和 C++ 的 未定义行为(Undefined Behavior, UB) 概念则要极端得多。在这些语言中,某些操作不会在编译或运行时产生错误,但在标准中它们是不被允许的。这意味着程序员和编译器之间有一种契约:如果代码触发了未定义行为,编译器可以做任何事情,包括使显示器爆炸或格式化硬盘(虽然实际不会发生)。编译器工程师不会故意制造这些后果,而是利用未定义行为来消除边界情况(corner cases),从而进行更激进的优化。
未定义行为的主要原因可以分为 两大类:
这些错误几乎总是程序员的无心之失,例如:
- 明显的程序错误
- 除零
- 解引用空指针
- 访问未初始化的内存
与其让这些操作返回一个固定的回退值(如 0),不如让程序在测试时崩溃或表现出不可预测的行为,以便尽早发现错误。
- 平台相关的行为
有些操作在不同的 CPU 架构上表现不同。例如:
整数左移超出位宽
1
int x = 1 << 32; // UB
这个操作在 x86 和 ARM 上可能会产生不同的结果。如果 C++ 标准指定某种行为,那就意味着某些架构必须额外做一次检查,影响性能。因此,C++ 直接规定它是 UB,避免额外的运行时开销。
负数的右移
1 | int x = -42; |
在某些架构上,右移负数会补 1(算术右移),在其他架构上可能会补 0(逻辑右移)。C++ 允许这种行为由实现决定,而不是设为 UB,因此它是 实现定义(implementation-defined) 而不是未定义行为。
保留未定义行为有时候能够帮助编译器优化,比如实际在c++中,有符号整型(signed
int)的溢出就是一个UB,但无符号整型(unsigned
int)的溢出是被允许的,也就是说其实如果x为有符号整型,那么(x + 1) > x这个条件就恒为true,体现在编译器的处理过程上,他可能会直接优化整个分支。比如有如下代码:
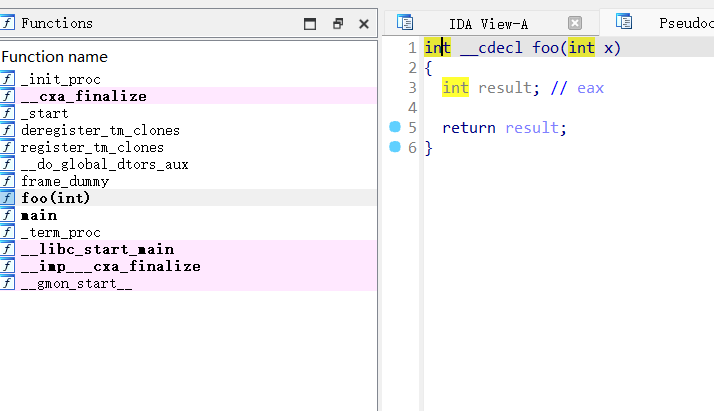
1 |
|
我们可能认为程序最后会打印"Overflow happened!",但实际上我们用g++编译后拿IDA查看对应的代码,就会发现整个foo函数的分支就被优化掉了。而如果foo参数类型为unsigned
int,编译器就会如我们所想,编译出实现对应分支的汇编。
去除边界情况
"安全“的编程模式经常包括大量的边界检测,但这不一定会带来性能损失,因为编译器可能在编译阶段就能保证数据是在边界范围内的,由此可以直接安全的优化掉边界检测。
我们也可以手动使用__builtin_unreachable
来消除边界检查,比如我们有如下代码:
1 |
|
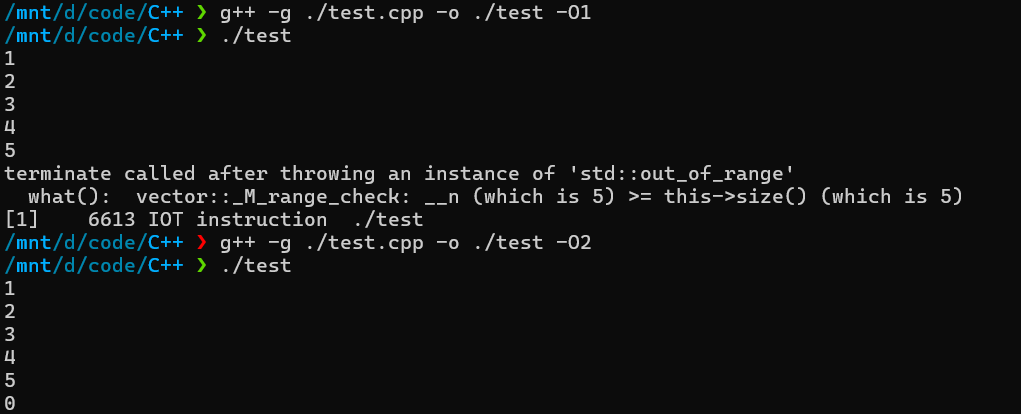
这里我把循环次数设置为了v.size()+1,也就是刚好越界,之后我们进行编译测试一下会发现,当开启O2及以上优化时,编译器就会根据我们的提示,优化掉vector的at中的边界检测了。
我们还可以结合 assert() 进行 Debug
1 |
|
- Debug 版本:
assert(k < v.size());可以在运行时捕捉错误。 - Release 版本:编译器会移除
assume(),并优化掉不必要的边界检查。
在进行算术运算时,我们尤其要关注边界条件。而其中浮点数的优化比较简单,我们只用加入-ffast-math编译选项即可。
在默认情况下,编译器 必须 严格遵守 IEEE 754 浮点运算标准,例如:
- 保证 运算的顺序 不能随意改变
- 处理 NaN(非数
Not a Number)和 无穷大 - 保证 精度 及 舍入模式
但是,这种严格遵守会 阻碍优化。使用
-ffast-math 选项后,编译器可以 忽略一些 IEEE 754
规则,以换取更快的执行速度。
然后我们考虑一下整数的情况,首先是无符号整型,比如有以下代码。
1 | unsigned div_unsigned(unsigned x) { |
我们知道除法对应的指令开销是很大的,一种非常常用的优化就是改为移位运算x >> 1。也就是shr eax。
但如果换成有符号整型,情况就有一点不同了。
1 | int div_signed(int x) { |
如果x是负数,那么无论是算术右移位还是逻辑右移位,都会得到错误的结果。所以为了考虑到所有情况,需要用以下的汇编技巧实现:
1 | mov ebx, eax |
这样的技巧比起简单的shr eax开销大了不少,效率只有原来的1/4,所以我们有时候如果认定x为正数,就可以用之前提到的assume方式来提示编译器优化掉边界条件的处理。
编译器在优化涉及内存读写的操作时通常比较困难,因为它们可能无法确定不同指针是否指向相同的内存区域。这会影响 指令重排、向量化(SIMD)、并行执行 等优化策略。
考虑如下代码:
1 | void add(int *a, int *b, int n) { |
编译器的视角:
- 在每次
a[i] += b[i]操作中,a[i]依赖于b[i]的值。 - 由于
a和b都是指针,编译器无法确定它们是否指向重叠的内存区域(aliasing)。 - 如果
b == a - 1(即b第二个元素指向a),那么b[i]可能是前一次循环a[i-1]的结果,导致数据依赖链,必须顺序执行。
C 语言中的 restrict 关键字
告诉编译器:
这个指针是唯一访问该内存区域的方式,不会与其他指针发生 aliasing。
优化后的代码:
1 | void add(int * __restrict__ a, const int * __restrict__ b, int n) { |
这样做的好处:
- 保证
a和b不会指向重叠内存,编译器可以自由优化。 - 开启自动向量化(SIMD),提升性能。
- 增强代码可读性,明确表达数据的访问方式。
预计算
在 C++ 编译优化中,预计算(Precomputation) 是一个关键技术。当编译器能够推断出某个变量的值仅依赖于编译时已知的数据,它可以直接在编译期计算这个值,并将其作为常量嵌入到机器代码中。
这可以显著提高运行时性能,但:
- 这并非 C++ 标准的一部分,因此不同编译器可能会有不同的优化策略。
- 如果计算量过大,编译器可能会放弃预计算,转而保留运行时计算。
常量表达式(Constant Expressions)
为了解决预计算的不确定性,C++ 允许显式指定某些函数为
constexpr,这样编译器必须在编译期计算它们的值(如果参数是常量)。
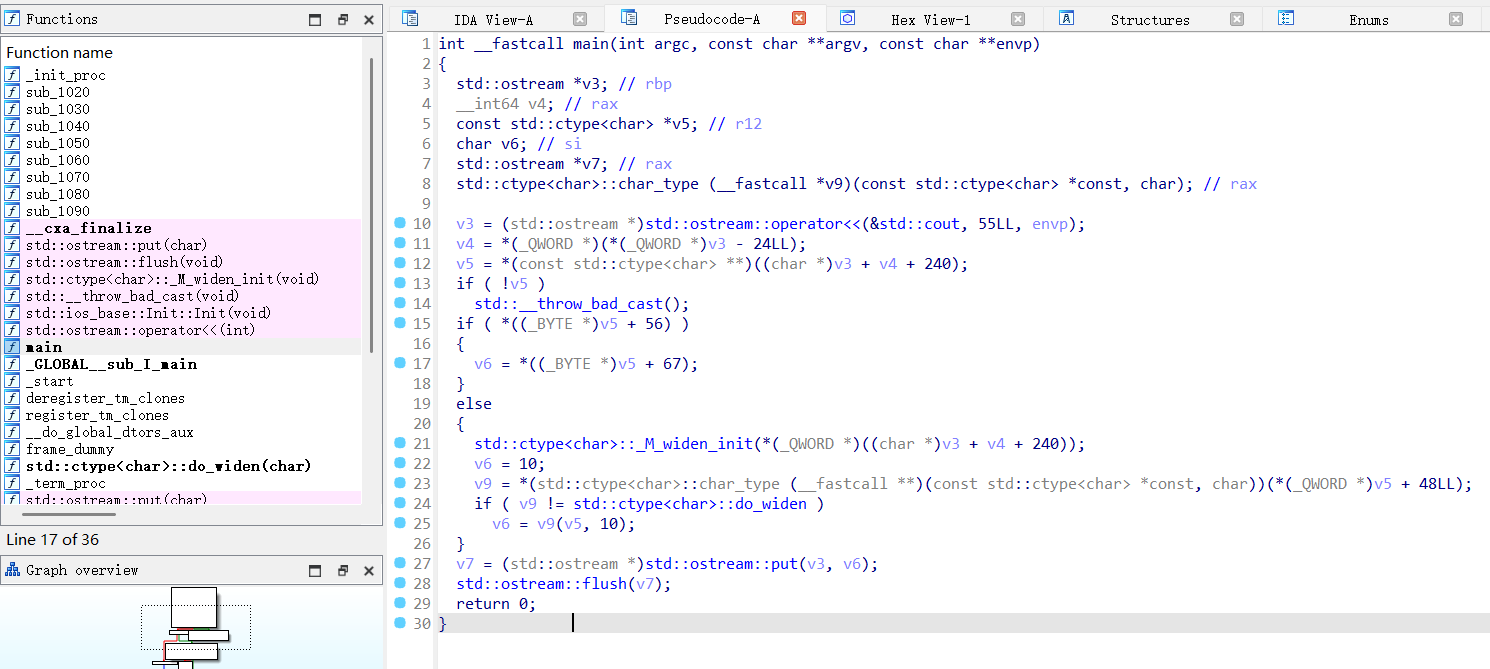
1 | constexpr int fibonacci(int n) { |
在这个例子中fibonacci(10)
会在编译时计算并被替换成
55,而不会出现在运行时计算中。比如我们开O2优化后,就能看到已经不存在fibonacci函数,而是直接硬编码55输出了。
constexpr 关键字带有一定限制:
- 只能调用其他
constexpr函数。 - 不能进行动态内存分配(如
new)。 - 不能有运行时不可预测的行为(如读取文件、I/O 操作等)。
但随着 C++
标准的演进,这些限制逐渐减少。由于递归版本效率低,C++17
允许 constexpr 函数使用
循环,提高计算效率:
1 | constexpr int fibonacci(int n) { |
这样 fibonacci(100) 之类的计算在编译期就能高效完成。
C++17 之后,可以使用 constexpr
构造静态查找表,这对于预计算平方根、对数等复杂数学运算特别有用。
1 | struct Precalc { |
在这个例子中:
Precalc结构体在编译期计算isqrt数组,并存储所有0~999的整数平方根。- 这样,在运行时我们可以直接查表,而不需要重复计算
sqrt()。
五、性能测试(Profiling)
概述
仅仅看源代码或者汇编并不能精准找到性能瓶颈,必须使用合适的性能分析工具。分析方法主要分为三种:
Instrumentation(插桩分析)
Statistical Profiling(统计分析)
Program Simulation(程序模拟)
插桩分析(Instrumentation)
计时
用于测量代码执行时间,找到需要优化的部分。基本方法是使用
clock() 记录起始时间,执行函数后计算时间差。例如:
1 | clock_t start = clock(); |
由于 clock()
本身精度有限(微秒级),如果函数执行时间很短,单次测量会受到较大误差的影响。改进的方法是在循环中多次执行函数,然后计算平均时间:
1 | const int N = 1e6; |
这种方法能够降低误差,但仍需注意缓存、编译器优化等影响。
事件采样
用于统计特定算法的特征,例如:
- 哈希函数:关注输入数据的平均长度;
- 二叉树:关注其高度和节点数;
- 排序算法:统计比较操作的次数。
基本方法是直接在代码中插入计数器:
1 | void query() { |
缺点是如果调用次数过多,这会带来额外的性能开销。实际上看似这里的count++也增加不了多少花销,但如果统计数据的存储需要:
- 存入数组 → 可能导致 CPU
缓存失效,因为
count++会不断写入一个变量,而采样写入的次数更少; - 写入日志/文件 → 频繁写入磁盘 I/O 代价极高,减少存储次数有利于性能;
- 存入数据库 → 频繁更新数据库可能导致事务开销增加。
比如query() 被调用 10 亿次,那么
stats 可能占用 多个 GB 内存,并且 CPU
可能会因为缓存未命中导致性能下降。
1 | // 直接计数,每次都写入数组 |
在这些情况下,随机采样可以降低存储和 I/O 开销。显著提高缓存命中率、减少 I/O 压力。
1 | void query() { |
不过上述随机采样实现方式也存在问题,如果我们要执行10亿次query,那就要调用10亿次rand函数。这里我们可以转用几何分布来进行随机抽样。几何分布的本质:它描述了成功事件(采样事件)发生之前的失败次数。假设我们仍然希望以
1% 的概率进行采样(即
p = 0.01),几何分布会直接生成下一个成功事件之前的失败次数。比如geometric_distribution(0.01)
可能返回 87,表示前 87 次都不会采样,第 88
次才会采样。
1 | void query() { |
比如我们用如下代码进行实验,最后就会输出10个左右的不同抽样值:
1 |
|
统计分析(Statistical Profiling)
在程序性能分析中,Instrumentation(插桩)方法虽然有效,但通常过于繁琐且容易带来额外开销。如果你需要分析程序中的多个小部分,或者需要较为细粒度的统计信息,Instrumentation的效果并不理想。Statistical Profiling(统计分析)则提供了一个更轻量且高效的方法。
Statistical Profiling的工作原理
统计分析通过在随机时间间隔中暂停程序的执行,并查看程序计数器指向的位置来进行性能分析。每次暂停时,程序的指令指针(Instruction Pointer,IP)会显示当前执行到的代码位置。通过在不同的函数块中进行暂停,可以得出一个大致的统计,反映出各个函数所消耗的执行时间。
硬件事件与性能计数器
硬件事件指的是与硬件行为相关的活动,如分支预测错误(branch mispredict)、缓存未命中(cache miss)等。这些事件在CPU上有对应的硬件性能计数器,这些计数器会记录特定硬件事件发生的次数。
- 硬件性能计数器:这些特殊的寄存器内置于微处理器中,用于存储某些硬件活动的发生次数。它们是非常轻量级的硬件组件,通常只有简单的二进制计数器和相应的激活信号。
- 事件触发的计数:每个性能计数器与大量的硬件电路连接,可以配置为在某个硬件事件发生时递增。例如,若程序发生了分支预测错误,或者缓存未命中,计数器就会增加。
- 事件多路复用:有时需要同时追踪多个硬件事件,可以通过多路复用技术,在不同的时间间隔内切换不同的计数器。虽然这种方法得到的统计是近似的,但它仍然能提供足够的信息用于性能分析。
与插桩方法相比,统计分析方法更加轻量,不会在每个函数调用时引入额外的开销,避免了程序执行的显著干扰。通过增加采样频率可以提高分析的准确性,但过高的采样频率可能会引起性能下降,从而影响统计数据的真实性。因此,通常需要较长时间的运行来获得更精确的统计数据。
分析工具
在linux系统上,主要使用 perf
进行分析,而在别的系统上,可以使用 VTune
实现类似功能。这里我在wsl环境下进行实验,也可以尝试用sudo apt install linux-tools-common进行安装,但是会一直显示内核环境不匹配。那我们可以去github下载源码手动编译。
1 | sudo apt install elfutils libunwind-dev libperl-dev liblzma-dev libzstd-dev libcap-dev libnuma-dev libbabeltrace-dev libpfm4-dev libtraceevent-dev |
然后我们准备一个cpp程序:
1 | // g++ -O3 -march=native ./test.cpp -o test |
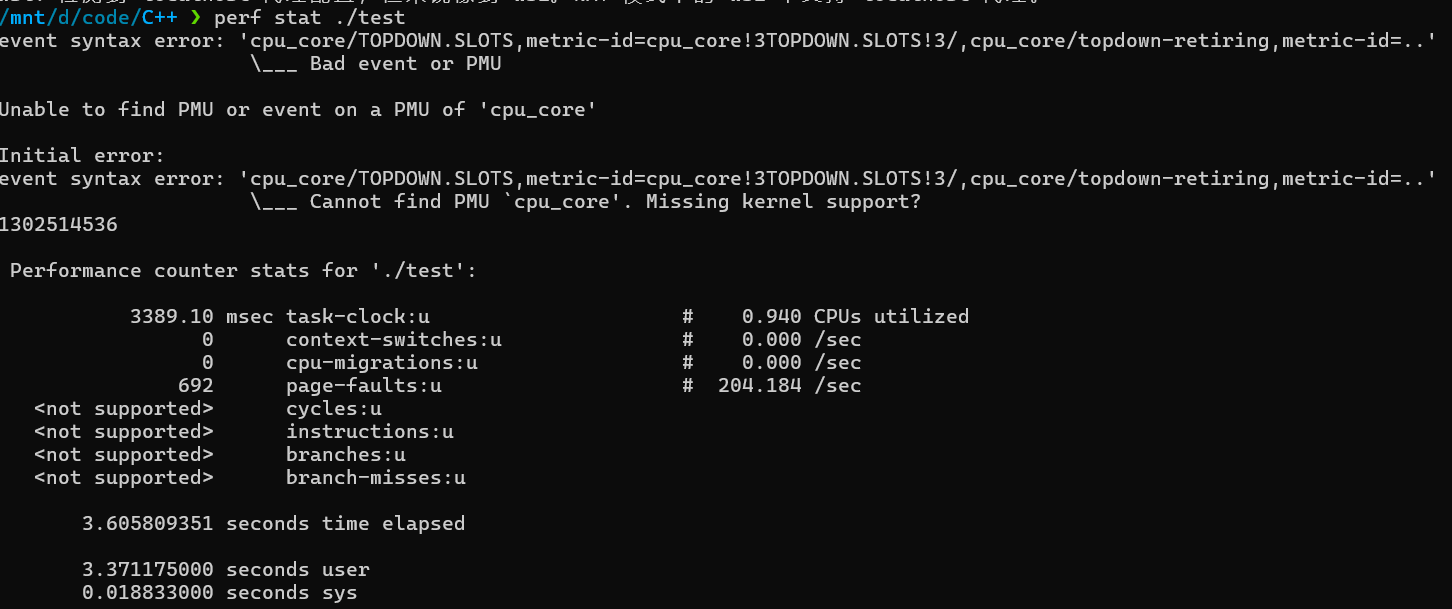
然后我们可以perf stat ./test
进行测试。但发现如上perf会显示如下错误,能够获取的信息很有限。之后看了这篇文章发现可能wsl2就是不支持硬件计数器的,所以最好我们还是用vm中的完整linux系统来进行模拟。
有时候会出现如下错误:
1 | Error: |
这是因为 perf_event_paranoid
级别过高,限制了非特权用户的访问。我们可以降低
perf_event_paranoid 级别来解决这个问题。
1. 临时调整权限(仅对当前会话有效)
1 | echo -1 | sudo tee /proc/sys/kernel/perf_event_paranoid |
解释:
-1允许所有用户访问几乎所有性能事件。- 该设置 仅对当前会话有效,重启后会恢复默认值。
2. 永久修改 perf_event_paranoid
设置
如果你希望每次启动系统时 perf 都能正常工作,可以修改
/etc/sysctl.conf:
1 | echo "kernel.perf_event_paranoid = -1" | sudo tee -a /etc/sysctl.conf |
这样每次重启后,perf_event_paranoid 都会自动设置为
-1。
正常的执行结果如下:
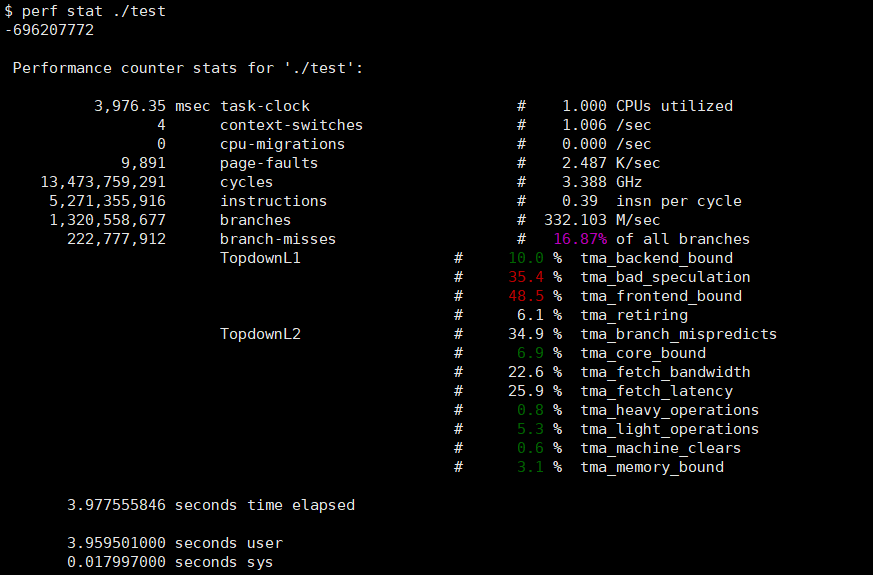
还可以用perf stat -e cache-references,cache-misses ./test来查看缓存的引用数以及不命中率。更多的可查看的事件可以通过perf list列出来。常用的还有perf record -g binary记录数据,perf report查看数据。
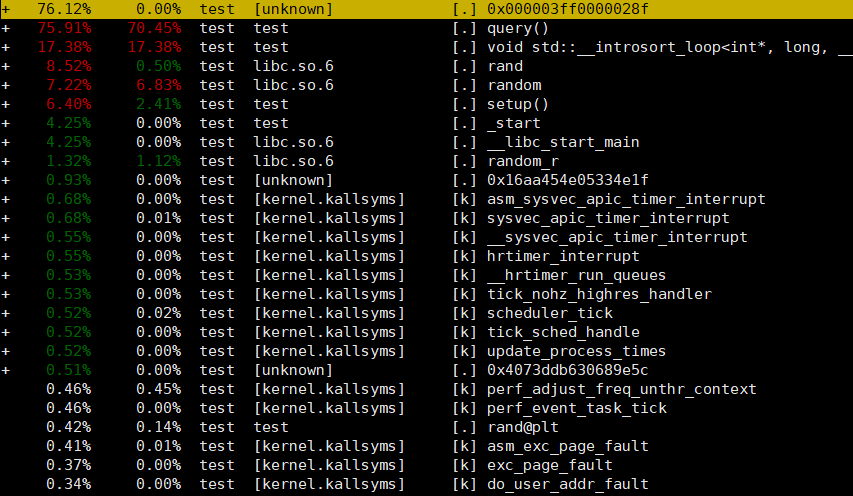
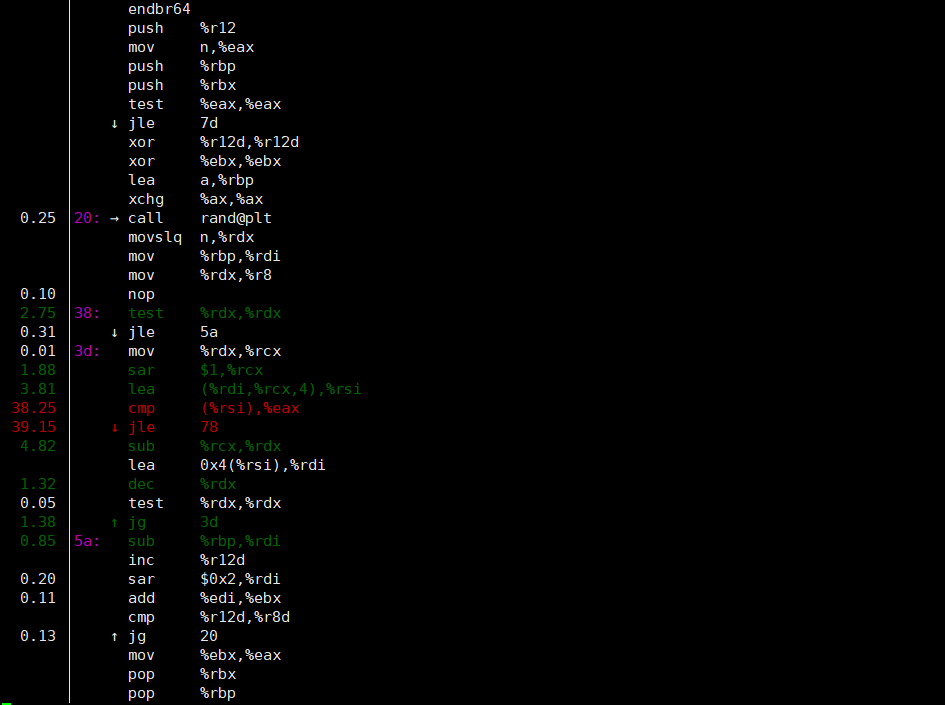
还能够跟进具体的函数查看哪个指令花费的时间最多。从下图可发现我们的程序大部分时间都在等待比较结果并跳转。
程序模拟(Program Simulation)
这类分析工具有许多不同的子类别,它们在模拟计算的不同方面有所区别。我们将重点关注缓存(caching)和分支预测(branch prediction),并使用 Cachegrind 进行分析。Cachegrind 是 Valgrind 的一个专门用于性能分析的组件,而 Valgrind 本身是一个广泛用于内存泄漏检测和内存调试的工具。我们可以通过这个工具清晰的看出缓存的命中率以及分支预测成功率。
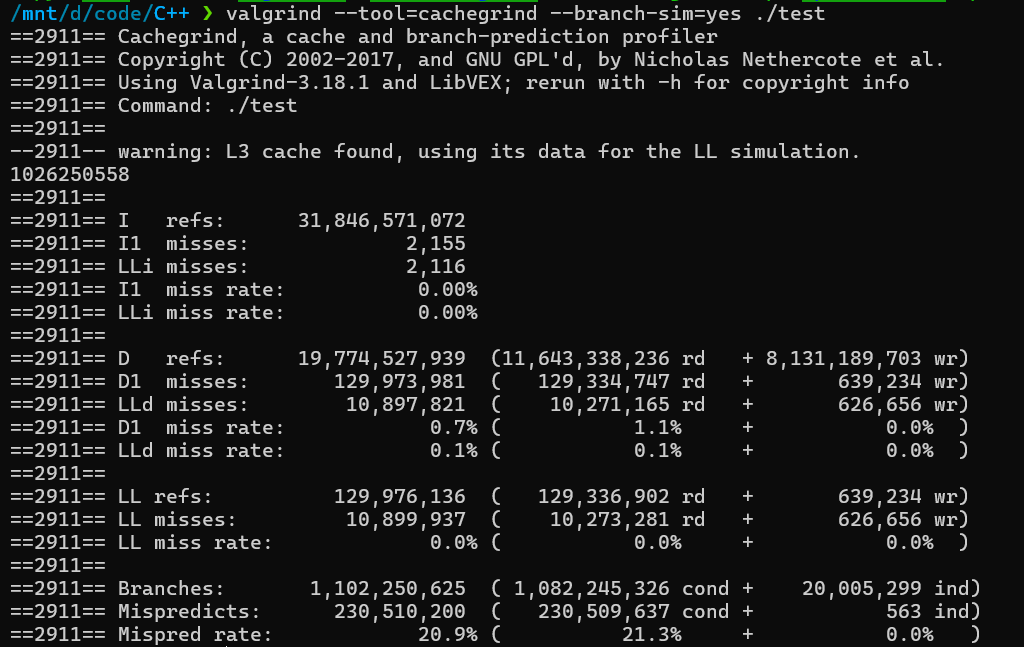
Cachegrind 只模拟了第一个(D1 数据缓存,I1
指令缓存)和最后一个(LL,统一缓存)级别的缓存,这些特性是从系统中推断出来的。它并不限制你使用,可以通过命令行设置它们,例如,要模拟
L2
缓存,可以使用:--LL=<size>,<associativity>,<line size>。
到目前为止,似乎它只是让程序变慢了,并没有提供比
perf stat
更多的信息。为了从中获得更多信息,我们可以检查它默认输出的包含分析信息的特殊文件,该文件通常会以
cachegrind.out.<pid>
的形式保存在同一目录中。它是可读的,但应该通过 cg_annotate
命令来读取:
1 | cg_annotate cachegrind.out.4159404 --show=Dr,D1mr,DLmr,Bc,Bcm |
Dr 代表数据读取,D1mr 代表 D1
缓存未命中,DLmr 代表 LL 缓存未命中,Bc
代表分支计数,Bcm 代表分支误预测计数。
首先会展示出缓存系统的一些参数:
1 | I1 cache: 32768 B, 64 B, 8-way associative |
接下来,它会输出一个类似 perf report
的每个函数的摘要:
1 | Dr D1mr DLmr Bc Bcm file:function |
这样我们就可以分析是在什么阶段出了很多 L1 缓存未命中 和 分支误预测。这是perf不具有的功能。
Cachegrind
还有一个非常好的特性是对源代码的逐行注解。为此,你需要用调试信息(-g)编译程序,并且显式告诉
cg_annotate 需要注解哪些源文件,或者直接使用
--auto=yes
选项,让它自动注解所有它能访问到的文件(包括标准库的源代码)。
1 | g++ -O3 -march=native ./test.cpp -g -o test |
不幸的是,Cachegrind
只追踪内存访问和分支。当瓶颈是由其他因素引起时,我们需要使用其他模拟工具进行分析。
机器码分析
主要用的工具是llvm-mca,我们将以数组求和作为简单的例子进行分析:
1 | loop: |
llvm-mca 的分析结果(以 Skylake 微架构为例)
1 | Iterations: 100 |
运行信息:
llvm-mca模拟执行了 100 次循环,总共执行了 400 条指令,用时 108 个周期。- 这相当于每个周期平均执行约 3.7 条指令(IPC,即每周期指令数)。
- CPU 理论上每周期最多执行 6 条指令(调度宽度)。
- 每条指令的平均吞吐量为 0.8 周期。
指令信息:
- 每条指令的细节信息,包括它分解成的微操作数(uOps)、延迟、吞吐量等:
1 | [1] [2] [3] [4] [5] [6] Instructions: |
每条指令有:
- uOps:指令分解成的微操作数。
- 延迟:执行该指令所需的周期数。
- 吞吐量:指令在多个副本可以同时执行时的平均周期数。
- 资源压力图:
llvm-mca还会输出每条指令使用的CPU资源的压力情况。如下所示:
1 | Resource pressure by instruction: |
- 该图显示了每条指令在不同执行端口上的资源使用情况。
- 通过查看这些统计信息,可以诊断出哪些指令在执行过程中遇到了瓶颈,通常是由于资源争用导致的结构性危害。
基准测试
在软件工程中,大多数优秀的实践都涉及到如何缩短开发周期:你希望更快地编译软件(构建系统)、尽早捕获错误(静态分析、持续集成)、一有新版本就立即发布(持续部署),并且快速响应用户反馈(敏捷开发)。性能工程也是如此。如果做得正确,它应该类似于一个循环:
- 运行程序并收集度量指标。
- 找出瓶颈所在。
- 消除瓶颈,回到第 1 步。
编写基准测试代码有几种方法。可能最常见的方法是将要比较的多种同语言实现放在同一个文件中,在
main
函数中分别调用它们,并在同一个源文件中计算你想要的所有度量指标。
这种方法的缺点是你需要编写大量的样板代码,并且为每个实现重复这些代码,但可以通过元编程来部分消除这一点。例如,当你正在基准测试多个
gcd 实现时,可以通过这个高阶函数大大减少基准测试代码:
1 | const int N = 1e6, T = 1e9 / N; |
这种方法具有非常低的开销,可以让你运行更多的实验并从中获得更准确的结果。你仍然需要执行一些重复的操作,但它们可以通过框架自动化,Google
的 benchmark 库是 C++
中最流行的选择。一些编程语言也提供了方便的内置基准工具,例如 Python 的
timeit 函数和 Julia 的 @benchmark 宏。
分离实现代码
在 C/C++ 中,通常可以通过创建一个单一的头文件(例如
gcd.hh)来定义算法接口,并将所有的基准测试代码放在
main 函数中。这种做法的基本结构如下:
1 | // gcd.hh |
在上面的代码中,gcd.hh 头文件只声明了 gcd
函数,而其具体实现被写在不同的源文件中。这样可以让你在不修改主代码的情况下,测试不同版本的
gcd 算法。
不同版本的实现
每个算法版本的实现(例如,v1.cc、v2.cc
等)都可以包含这个头文件,并根据需要实现 gcd
函数。例如:
1 | // v1.cc |
这种方法使得你可以在命令行中指定某个版本的算法进行基准测试,而无需修改任何源代码。你只需在不同的实现文件之间切换或通过编译时参数选择实现版本。
动态调整参数
为了提高灵活性,可以通过命令行参数来传递运行时的参数。例如,你可以根据命令行参数设置数据集大小:
1 | // main.cpp |
这样,你就能够在不同的实验中灵活地调整输入数据的规模而无需重新编写代码。
使用编译时常量
另一种方法是使用 C 风格的全局宏定义,并通过编译时的 -D
标志来传递参数。例如,设置 N 的值:
1 | // gcd.hh |
然后在编译时使用 -D N=2000000 来设置 N
的值:
1 | g++ -D N=2000000 -o main main.cpp v1.cc |
这种方法的优势是能够利用编译时常量,这对于某些算法的性能优化非常有帮助。然而,缺点是每次更改参数时需要重新编译程序,这可能会增加收集多个参数值的度量数据所需的时间。
Makefile使用
为了提高编译速度,可以将源文件拆分,并使用像Make这样的缓存构建系统。Make是一个强大的工具,可以通过自动化编译过程来加速构建和测试循环。以下是一个常用的Makefile示例,适用于C++项目的构建:
1 | compile = g++ -std=c++17 -O3 -march=native -Wall |
解释
compile: 定义了一个编译命令,使用g++编译器,启用了C++17标准,开启了最大优化-O3,指定了本地体系结构优化-march=native,并显示警告信息-Wall。%.cc到gcd.hh:编译源文件(.cc)并链接到一个可执行文件(默认文件名)。$<表示当前依赖文件(在这种情况下是源代码文件)。%.s:为源文件生成汇编代码,使用了-S和-fverbose-asm,生成详细的汇编输出。$@是目标文件的名称。%.run:通过@./$<运行生成的可执行文件,$<表示编译后的目标文件。.PHONY: 用于声明伪目标,确保即使存在同名文件,Make也能正常执行。
使用这个Makefile,你可以通过简单的命令来编译和运行程序,例如:
1 | make example # 编译example.cc为可执行文件 |
与性能分析结合
你还可以在Makefile中加入性能分析的脚本。例如,通过
perf stat 来自动化性能剖析:
1 | %.perf: % |
这样,你就可以运行 make example.perf
来获取运行的性能统计数据。
Jupyter Notebooks使用
为了进一步加速高层次的分析,你可以在Jupyter Notebook中整理你的脚本并生成图表。可以通过编写一个基准测试函数来自动化测试不同算法实现的性能:
1 | def bench(source, n=2**20): |
在这个函数中,make -s {source}
会编译源代码并生成目标文件。如果编译失败,它会抛出异常。然后,使用
!./{source} {n} 运行编译后的程序并返回执行时间。
一旦有了基准测试的函数,你就可以轻松地编写清晰的分析代码:
1 | ns = list(int(1.17**k) for k in range(30, 60)) |
获取准确的结果
为了使测试的结果更加准确,我们需要考虑如下的几个点:
1.不同的数据集
由于很多算法的效率很大程度上受数据分布的影响,我们需要选取尽可能贴近实际使用的数据分布来进行测试。例如如下的有序数据集,会使分支很容易预测。而随机打乱的数据集就会让cpu难以通过执行的历史预测之后的分支取向。
1 | // don't do this |
2.多个优化目标
如哈希表,可能需要在内存占用、查询时间等多个维度进行权衡。
3.吞吐量 vs 延迟
在现代 CPU 上,指令并不会严格顺序执行,而是可以 乱序执行 和 流水线并行处理。因此,如果一个任务可以与其他任务同时进行,那么它的吞吐量可能比单个操作的真实延迟更低。所以下面的代码只能测试吞吐量。
1 | for (int i = 0; i < N; i++) |
为了测试真实的延迟,我们需要手动引入数据依赖,这样子CPU
无法并行执行多个查询,每个 lower_bound
必须等待前一个完全结束,流水线和乱序执行的优化作用变小。测得的时间更接近单个查询的真实执行时间。
1 | for (int i = 0; i < N; i++) |
4.冷缓存
当数据最初不在 CPU 缓存(cache)中时,内存读取的时间会更长。在开始正式测量之前,先运行一次预热(warm-up),这样数据就会被加载到缓存中,避免缓存未命中的影响:
1 | // 预热运行(warm-up run) |
过度优化(Over-Optimization)
有时基准测试(benchmark)本身是不正确的,因为编译器可能直接优化掉被测试的代码,导致测量结果没有意义。
如何防止编译器优化掉基准测试?
使用校验和(checksum)
在测试代码中使用
checksum变量,并在最后输出,避免编译器省略计算。例如:
1
2
3
4
5int checksum = 0;
for (int i = 0; i < N; i++)
checksum ^= lower_bound(q[i]);
printf("checksum: %d\n", checksum); // 防止优化如果
lower_bound(q[i])的计算结果没有影响最终程序逻辑,编译器可能会认为它是无效计算并移除,导致错误的测量结果。使用
volatile限定符volatile关键字告诉编译器不要优化该变量的访问,确保它在每次循环迭代时都被真正计算:1
2
3volatile int checksum = 0;
for (int i = 0; i < N; i++)
checksum ^= lower_bound(q[i]);作用:
防止编译器优化掉整个计算过程。
防止循环迭代之间的指令重排(interleaving),确保按顺序执行。
减少噪音
在基准测试(benchmarking)中,除了偏差(bias),还有噪声(noise)*会影响测量结果。偏差通常会*系统性地使某个算法占优,而噪声则会导致随机波动,增加测试的方差(variance),使结果不稳定。
噪声的来源
外部干扰(Side Effects & External Noise)
- 其他进程运行时占用 CPU 资源,影响算法性能测试。
- CPU 频率自动调节(CPU Frequency Scaling)。
- 超线程(Hyper-Threading)导致 CPU 资源共享,影响单核性能。
如何减少噪声?
使用
perf stat统计 CPU 周期(cycles)- 若基准测试的是计算密集型(compute-bound)算法,推荐使用
perf stat直接测量 CPU 执行指令的周期,而不是依赖时间戳。 - CPU 频率可能会波动,影响测试的时间,但
perf stat计数的指令周期数不会受到影响,这样可以得到一个独立于 CPU 频率波动的性能测量。
固定 CPU 频率
CPU 可能会根据负载自动调整频率,这会导致每次运行基准测试的结果不同,因此需要手动锁定频率:
1
sudo cpupower frequency-set -g performance # 设置为最高性能模式
或者:
1
sudo cpupower frequency-set -g powersave # 限制 CPU 频率最低
这样可以确保 CPU 频率不会在测试过程中波动。
关闭超线程(Hyper-Threading)
超线程允许 CPU 一个物理核心同时运行两个线程,但这可能导致基准测试结果受其他进程影响。
关闭超线程的方法:
1
echo off | sudo tee /sys/devices/system/cpu/smt/control
或者在 BIOS/UEFI 中手动禁用超线程。
绑定 CPU 核心,确保独占
如果希望某个程序只运行在特定 CPU 核心上,可以使用
taskset绑定:1
taskset -c 0 ./my_program # 仅在 CPU 0 上运行
这样可以避免操作系统随意调度进程到不同核心,减少基准测试的波动。
关闭网络和不必要的进程
- 关闭后台进程,特别是可能影响 CPU 占用的任务,如自动更新、后台同步等。
- 关闭 Wi-Fi 和网络,以防止网络中断或后台任务影响基准测试。
尽量减少用户操作
- 鼠标移动等 UI 交互会触发 CPU 处理中断,可能影响测试结果。
- 若基准测试的是计算密集型(compute-bound)算法,推荐使用
即使采取了以上所有措施,仍然无法完全消除噪声。例如程序的名字也会影响执行速度。
- 因为可执行文件名会存储在环境变量中,环境变量存储在调用栈(call stack)中,导致栈的对齐(stack alignment)发生变化。
- 这可能会让数据访问跨越 cache line 或 内存页边界(memory page boundary),导致访问速度变慢。
如何正确分析基准测试结果
- 不要过分解读小幅度变化
- 在 笔记本电脑 或 测试时间小于 1 秒 时,±5% 的波动是完全正常的,不要过度解读微小的性能变化。
- 如果你看到 +1% 的性能提升,不要立刻下结论,而是运行足够多次,计算方差和 p-value,确保统计显著性(statistical significance)。
- 使用 A/B 测试方法
- 和 A/B 测试一样,要多次运行并比较两个版本的性能,不要只跑一次就下结论。
- 计算均值、方差、p 值,确保你的优化方案确实带来了可测量的提升。
六、算术(Arithmetic)
浮点数
事实上,浮点运算通常比整数运算更快,这是因为现代处理器中有专门的浮点运算指令。此外,浮点数的表示方法经过严格的标准化,并遵循简单且确定性的舍入规则,使得计算误差可以可靠地管理。当我们需要对数字执行位运算时,浮点运算单元(FPU,负责浮点计算的协处理器)通常不支持这些操作。此时,数值需要被转换为整数。
在正式介绍浮点数规则之前,我们可以先来看一下一些其它的可能的解决方案。
符号表达式
第一种也是最繁琐的方法是存储产生结果的代数表达式,而不是直接存储计算后的数值。在某些应用(如计算几何)中,除了加、减、乘运算之外,还需要执行不带舍入的除法,即使用两个整数的比值(即有理数)来精确表示结果。
1 | struct r { |
这种方法可以保持绝对精度,不会因浮点运算误差导致结果不准确。但它的计算代价很高:
- 计算机需要存储每一步计算的历史操作,而不是简单存储最终数值。
- 计算时不仅要计算当前结果,还需要考虑所有之前的计算过程,这会导致计算量呈指数级增长。
因此,这种方法通常适用于:
- 计算精度要求极高的场景(如代数几何、数论)。
- 计算步骤相对较少的应用(如解析数学计算)。
- 计算机代数系统(CAS),如 Mathematica、SymPy 和 SageMath。
但在一般数值计算中,由于其高昂的存储和计算成本,往往采用浮点数近似计算来提高效率。
定点数
定点数是一种仅使用整数但隐式表示小数的方法,本质上就是把数值乘以一个固定的比例因子(通常是某个 10 的幂或 2 的幂)。
这种方法类似于更改测量单位,让所有运算都在放大后的整数范围内进行。
金融软件通常使用固定精度来存储货币值,例如 NASDAQ 股票交易所使用 1/10000 美元作为最小单位,即所有金额精确到小数点后 4 位。
1 | struct money { |
定点数的一个重大问题是比例因子选得不合适时,可能会导致整数溢出或精度损失。定点数不适用于大范围数值计算。比如考虑爱因斯坦质能方程:m 大约是
1.67 × 10⁻²⁷ kg。光速 c 约为 3 ×
10⁹ m/s。
在这种场景下:
- 如果比例因子太大,那么
m可能会被舍入到0,导致能量计算错误。 - 如果比例因子太小,那么
E可能会溢出,导致计算无法进行。
浮点数
在实际的应用场景中,我们主要关注数据的相对误差。我们通常希望计算结果的误差不超过0.01%。我们关心的是这个误差相对于数值本身的比例,而不关心它的绝对大小。
为了满足这个需求,浮点数使用了一种特殊的存储方式,它存储一个数字的有效数字(又称尾数或manitssa),并通过一个指数(exponent)进行缩放。在计算机中,数值是用固定长度的二进制字来存储的,因此我们希望设计一种固定长度的二进制浮点格式,其中部分比特用于存储尾数(以提供更高的精度),而另一部分比特用于存储指数(以提供更大的数值范围)。
1 | struct fp { |
这样,一个浮点数可以表示为:
这里的定义是m作为小数点后的尾数,并且这是因为浮点数的表示并不是唯一的。例如,数字
1 可以表示为:
然后我们看这个自定义的浮点数的乘法运算符合的规律:
- 乘法运算之后m的值域成了
我们需要进行处理将其归为标准的 ,采用的公式如下:
这样我们通过提取一个系数2增加了e,又能够成功将m的值域变回
- 可能因为精度不够而无法对结果进行表示,因为
m_a * m_b可能会超过可表示的范围。我们能够做的就是进行四舍五入。
完整的乘法实现如下,由于计算 m_a * m_b
需要额外的精度,我们使用 64
位整数进行中间计算,并进行标准化处理::
1 | fp operator*(fp a, fp b) { |
硬件浮点运算
在某些应用中,我们需要更高的精度,这时候可以使用软件浮点运算(如
fp
结构体实现的方式)。但是,软件浮点计算的效率很低,因为它需要执行多个指令。
为了提高效率,现代 CPU 使用专门的硬件单元(如 x86 的浮点运算单元 FPU,又称 x87)。这些单元提供:
- 专门的寄存器(x87 寄存器栈)
- 支持浮点运算的指令集
- 支持三角函数、指数、对数、平方根等复杂运算
这些硬件优化让浮点计算变得高效,并且大多数现代处理器都集成了浮点单元(如 x86 的 SSE、AVX 指令集)。
在后续部分,我们会探讨浮点数表示的一些更详细的特性,以及它如何在现代 CPU 中实际运作。
IEEE 754 浮点算术标准
当我们设计自己的浮点数类型时,我们省略了许多重要的细节,例如:
- 我们应该为尾数(Mantissa)和指数(Exponent)分别分配多少位?
- 符号位(Sign bit)为 0 是否表示正数,还是相反?
- 这些位在内存中是如何存储的?
- 零(0)应该如何表示?
- 具体的舍入(Rounding)规则是什么?
- 如果我们对零进行除法运算,会发生什么?
- 如果我们对负数求平方根,会发生什么?
- 如果我们递增到最大可表示的数,会发生什么?
- 我们是否能检测到上述某些特殊情况发生了?
在早期计算机中,通常不支持浮点运算。当各大厂商开始添加浮点协处理器时,它们对这些问题的答案各不相同。不同的浮点数实现使得浮点运算的可靠性和可移植性变得困难,尤其是对编译器开发者而言。
IEEE 754 标准 1985 年,IEEE(电气和电子工程师学会) 发布了 IEEE 754 标准,该标准正式规范了浮点数的运作方式。很快,各大厂商纷纷采纳该标准,如今它几乎被所有通用计算机采用。
与我们自己实现的浮点数类似,硬件浮点数 采用 1 位表示符号,指数和尾数部分的位数则因格式而异。例如,标准的 32 位浮点数(单精度) 采用:
- 最高位(1 位):符号位(Sign bit)
- 接下来的 8 位:指数位(Exponent)
- 剩下的 23 位:尾数(Mantissa)

采用这个存储顺序的原因之一是便于比较和排序。 在硬件中,我们可以直接使用无符号整数比较器来比较浮点数,仅在负数情况下对部分位进行翻转,以确保比较的正确性。
指数的偏移量(Bias)
为了表示小于 1 的值(负指数),IEEE 754 对指数值进行了偏移: 实际的指数值 = 存储的指数值 - 偏移量(Bias)
- 对于 单精度浮点数(float),偏移量是
127,即:
- 对于 双精度浮点数(double),偏移量是
1023,即:
假设上图为 IEEE 754 单精度浮点数:
- 符号位 0,表示正数。
- 指数部分 01111100₂ = 124,计算真实指数:
- 尾数部分 IEEE 754 规定隐含的 1,即:
- 计算结果:
IEEE 754 标准定义了多个不同的浮点数格式,常见的有:
| 类型 | 符号位 | 指数位 | 尾数位 | 总位数 | 约等于十进制精度 |
|---|---|---|---|---|---|
| 单精度(float) | 1 | 8 | 23 | 32 | ~7.2 位 |
| 双精度(double) | 1 | 11 | 52 | 64 | ~15.9 位 |
| 半精度(half) | 1 | 5 | 10 | 16 | ~3.3 位 |
| 扩展精度(extended) | 1 | 15 | 64 | 80 | ~19.2 位 |
| 四倍精度(quadruple) | 1 | 15 | 112 | 128 | ~34.0 位 |
| bfloat16 | 1 | 8 | 7 | 16 | ~2.3 位 |
不同格式的应用
- 单精度(float)和双精度(double):大多数 CPU
都支持,C 语言中的
float和double对应这两种格式。 - 扩展精度(extended):主要用于 x86
架构,C 语言中的
long double通常是 80 位(部分 ARM 架构降级为 64 位)。 - 四倍精度(quadruple)和 256 位“八倍精度”:主要用于高精度科学计算,不受主流硬件支持。
- 半精度(half):由于存储空间小、计算快,常用于 深度学习 和 计算机图形学。
- bfloat16:牺牲 3 位尾数,以获得与单精度相同的指数范围,适用于 机器学习(尤其是 神经网络)。
较低精度的浮点数占用更少的存储空间,在某些应用场景下可以大幅提高运算速度。例如:
- 深度学习 中,通常不需要很高的数值精度,而是更关注计算吞吐量和并行性。
- Google TPU(张量处理单元) 专门为
bfloat16设计,并能够 一次性计算 128×128 的矩阵乘法。 - NVIDIA Tensor Cores 可 一次执行 4×4 的矩阵运算,显著加速深度学习任务。
处理边界情况
默认情况下,整数运算在遇到边界情况(Corner Cases)(例如除零)时,会导致程序崩溃。1996 年,阿丽亚娜 5 号(Ariane 5) 运载火箭首飞失败,原因就是计算系统在遇到算术错误时采取了终止计算的策略。具体来说,这次错误是由于浮点数转换为整数时溢出(Floating-point to Integer Overflow)。这个错误导致导航系统错误地认为火箭偏离了轨道,于是计算机进行了大幅修正,最终导致火箭解体,直接损失 2 亿美元($200M)。
硬件中断(Hardware Interrupts) 提供了一种更优雅的方式来处理异常情况。
当程序发生异常时,CPU 会:
- 中断程序的执行(Interrupt Execution)。
- 收集所有相关信息,并存入一个特殊的数据结构,称为 “中断向量(Interrupt Vector)”。
- 将中断向量交给操作系统(OS)
- 如果程序提供了异常处理代码(类似于
try-except机制),OS 会调用处理代码。 - 如果没有,则直接终止程序。
- 如果程序提供了异常处理代码(类似于
硬件中断虽然可以优雅地处理异常,但速度很慢,不适合实时系统(如火箭导航)。
NaNs、零和无穷大
| 类型 | 特点 | 数学运算 | 二进制表示 |
|---|---|---|---|
| 无穷大(Infinity) | 由于数值溢出产生 | 指数全 1,尾数全 0 | |
| 正零(+0.0) | 可能导致优化问题 | 所有位为 0 | |
| 负零(-0.0) | 更适合作为初始化值 | 符号位 1,其余 0 | |
| NaN(非数) | 计算非法数学运算时出现 | 指数全 1,尾数非 0 | |
| 信号 NaN(sNaN) | 触发异常标志 | 可能引发中断 | 指数全 1,尾数部分非 0 |
| 静默 NaN(qNaN) | 在计算中传播 | 结果仍然是 NaN | 指数全 1,尾数部分非 0 |
舍入误差
硬件浮点数的舍入方式非常简单:只有当运算结果无法精确表示时才会发生舍入,默认情况下向最接近的可表示数舍入(如果有两个同样接近的候选值,则优先选择以 0 结尾的那个)。
1 | float x = 0; |
预期数学结果: x
变得足够大时,x + 1
可能无法被精确表示,导致舍入误差。
具体来说:
- 32 位
float使用 23 位尾数 ,有效的精度为 24 位二进制位。 - 当
x = 2^{24} = 16777216时:- 计算
x + 1 = 16777217,由于16777217无法在float精度范围内精确表示,它会被舍入回 16777216(因为16777217与16777216距离相等,按“以 0 结尾优先”的规则,舍入回16777216)。
- 计算
- 由于
x不再发生变化,循环继续执行但x不再增长,最终x仍然停留在16777216。
在 2^24 之前,x + 1
可以被精确表示,所以加 1 没有舍入误差,一直到
x = 2^24 才开始丢失精度。比如当 x = 2^{24}
时,它的二进制表示如下,注意到为了与24的指数对齐(每乘一个2相当于小数点右移一位),下面的表示有24位的尾数,实际上最后的一位0是不存在的:
这时,如果我们 加 1(即 x + 1),结果是: x + 1被舍入回x。
浮点运算顺序影响结果
浮点运算的结果可能取决于计算顺序,即使它们在数学上是等价的。
在数学上,加法和乘法满足:
通常,编译器不会随意调整计算顺序,以保证符合 IEEE 754
规范。但如果开启
-ffast-math(GCC/Clang),编译器会忽略一些浮点计算的精度规则,可能会:
- 重新排序运算,提高性能
- 产生不同的浮点计算结果
如果在上面的 x++ 循环代码中开启
-ffast-math,程序可能会跳过中间精度检查,从而最终得到
33554432,但这也可能带来更大的舍入误差。
不同的舍入模式
除了默认的向偶数舍入(Banker’s Rounding),IEEE 754 还提供了 4 种舍入模式:
| 舍入模式 | 描述 |
|---|---|
| Round to Nearest (默认) | 取最近的可表示值,在两边距离相等时取偶数 |
Round Up (FE_UPWARD) |
向 +∞ 方向舍入(负数趋向于 0) |
Round Down (FE_DOWNWARD) |
向 -∞ 方向舍入(负数远离 0) |
Round Toward Zero (FE_TOWARDZERO) |
直接截断,不做四舍五入 |
示例:
1 |
|
解释
- 在
2^24之后,每次x + 1被舍入到x + 2,因此增长速度翻倍。 - 继续增长到
2^25后,每次x + 1会被舍入到x + 4,增长速度再翻倍。 - 最终
x以四倍速增长,达到2^26 = 67108864。
误差测量
在计算机执行浮点数运算时,我们通常关心 两种误差测量方式:
单位最后一位误差(ULP, Units in the Last Place)
- 这是衡量计算结果和真实值之间的偏差,以 可表示浮点数单位 计算的误差。
- 例如,如果某个计算结果比真实值小 1 ULP,意味着它比实际值小了一个可表示的浮点数单位。
- 在 IEEE 754 标准下,单次基本运算的最坏情况 不会超过 0.5 ULP,因为采用的是“四舍五入到最接近可表示数”策略。
相对误差
计算公式:
其中, 是 理论值, 是 浮点运算后的值。 数值分析中,更关心 相对误差,因为它衡量了结果的 比例误差,而不仅仅是绝对误差。
机器精度(Machine Epsilon, ϵ)
机器精度
有 23 位尾数,所以:
这意味着,最小可区分的数大约是
。
对于 IEEE 754 双精度浮点数(double, 64-bit):
- 有 52 位尾数,所以:
误差范围估计
假设执行单次浮点运算后,得到结果
浮点数比较
由于浮点数存在精度误差,直接比较 a == b
可能不可靠,所以通常采用 “误差范围判断”:
1 |
|
- 如果
a和b相差小于机器精度eps,就认为它们相等。 - 但这种方法
只适用于单次运算误差,多个计算累积误差后可能需要更大的
eps进行容忍。
浮点误差的累积
如果进行 n 次 乘法运算,每次的误差上界约为
数值不稳定性与避免方法
某些计算方式会放大浮点误差,导致数值不稳定。例如:
不稳定计算
计算误差分析:
稳定计算方式
Kahan 求和算法
标准的浮点数求和算法如下:
1 | float s = 0; |
如果数值的数量级不同(特别是存在非常大的数和非常小的数),则相对误差不再仅仅是
1 | const int n = (1<<24); |
这里 float 的 23 位尾数(mantissa)
所能精确表示的范围,因此所有的 +1.0 操作
都会被舍入掉,导致最终的计算结果没有变化。
这种情况表明,绝对误差 为 n
变大,错误也不会自动被归一化,而是会无限增长。
Kahan 求和算法核心思想
为了减少舍入误差,我们可以将 未被累加的部分存储起来,并在后续计算中补偿它:
1 | float s = 0, c = 0; |
y = a[i] - c:提取的 低精度部分。 t = s + y:执行加法,但y可能过小以至于无法准确表示。c = (t - s) - y:从计算结果t中恢复被丢弃的低精度部分,并存入c进行下一轮补偿。
Kahan 求和的 相对误差上界 为:
如果需要进一步提高精度,可以使用 double-double
算术,即用两个 double 变量存储一个高精度数:
a存储高位部分(高精度)b存储低位部分(误差修正)
这种方法可以推广到 四精度(quad-double),甚至更高精度的算术运算。
牛顿法
牛顿法是一个简单而强大的算法,用于寻找实值函数的近似根,也就是解决以下通用方程的根:
牛顿法的基本思想是:从某个初始的近似值
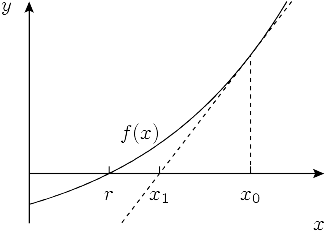
为了得到交点
平方根的牛顿法求解
首先,假设我们要解的是方程:
在实际应用中,我们希望在结果足够接近真实值时停止迭代。可以通过检查每次迭代后的结果差距是否小于某个阈值来实现这一点。以下是用代码实现的例子:
1 | const double EPS = 1e-9; |
该算法对于许多函数都是收敛的,但它只对某些特定类型的函数(如凸函数)能可靠地收敛。另一个问题是收敛的速度,若收敛发生,它的速度如何?对于平方根的求解,牛顿法通常表现得非常快。
收敛速度分析
以求
1 | 1.0000000000000000000000000000000000000000000000000000000000000 |
仔细观察,我们可以看到每次迭代后正确的数字位数大约是翻倍的。这种惊人的收敛速度并非偶然。
定量分析收敛速度
为了定量地分析收敛速度,我们需要考虑第
我们可以表达
误差的平方
从上面的公式可以得出:
对数与准确位数
由于
一般性的二次收敛
事实上,这种二次收敛不仅限于求平方根的问题。根据详细的证明可以证明,一般来说,对于任何合适的函数,牛顿法的误差会以二次速度收敛。假设函数的导数
具体公式如下:
平方根倒数速算法
倒数平方根是浮点数的一个重要计算,广泛应用于计算归一化向量,而归一化向量又在各种模拟场景中得到广泛应用,例如计算机图形学(例如,用于确定入射角和反射角来模拟光照)。
归一化向量的计算公式如下:
直接计算倒数平方根的方法,即先计算平方根再求倒数,速度非常慢,因为这两项操作虽然在硬件中实现,但仍然非常耗时。
然而,存在一种非常高效的近似算法,它利用了浮点数在内存中的存储方式。事实上,这个算法非常优秀,以至于它被直接实现到硬件中,因此它对软件开发者来说不再那么重要。然而,考虑到它的内在美和教育价值,仍然值得我们深入探讨。
近似对数的计算
根据对数的性质,有如下恒等式:
回顾浮点数的表示方式,它按顺序存储符号位(对正数来说为0)、指数
重新解释浮点数
现在,基于这个近似,我们定义

从上述公式我们可以反解出
1 | i = * ( long * ) &y; |
与牛顿法结合
然后我们求
1 | x2 = number * 0.5F; |
这样我们用平方根倒数速算法得到的初始值就比较接近真实值,第一次迭代后,结果已经精确到正确答案的99.8%,并且可以通过多次迭代进一步提高精度——这就是硬件中的实现方式:x86指令进行几次迭代,确保相对误差不超过
整数运算
虽然整数的表示形式相对简单,但它的简洁性使得很多操作可以通过其他操作来表达。而浮点数的表示形式复杂,以至于许多操作都需要硬件实现。而高效处理整数运算需要在指令集上更加巧妙的应用。关于无符号整型以及有符号整型等的表示方法这里不在赘述。
整数类型
整数有不同的大小,但它们的基本操作方式大致相同。以下是常见的整数类型及其对应的字节和C语言数据类型:
| 位数 | 字节数 | 有符号类型 | 无符号类型 | 汇编 |
|---|---|---|---|---|
| 8 | 1 | signed char | unsigned char | byte |
| 16 | 2 | short | unsigned short | word |
| 32 | 4 | int | unsigned int | dword |
| 64 | 8 | long long | unsigned long long | qword |
字节顺序(Endianness)
整数的字节存储顺序存在两种可能性:
- 小端(Little-endian):低位字节存储在前。例如,4210 = 1010102 会存储为 010101。
- 大端(Big-endian):高位字节存储在前。所有前面的例子都采用了大端。
小端有一个优势是,转换数据类型时(如将64位整数转换为32位整数),可以通过加载较少的字节(几乎不需要额外操作)来实现类型转换。而大端则有助于提升某些操作的效率,比如比较和打印。
128位整数
有时我们需要将两个64位整数相乘,得到一个128位整数。由于没有128位寄存器来存储这个结果,乘法指令通常会将结果分为两个部分:低64位和高64位。
例如:
1 | ; 输入:64位整数a和b,存储在rsi和rdi寄存器中 |
有些编译器提供了对128位整数的支持。例如,在GCC和Clang中,提供了__int128类型。
例如:
1 | void prod(int64_t a, int64_t b, __int128 *c) { |
128位整数的典型使用场景: 在没有直接支持128位整数的系统中,这些大整数通常会被分成两个64位寄存器。当需要存储两个64位整数相乘的结果时,结果将是一个128位的数字。由于没有128位寄存器,这个结果会被存储在两个独立的64位寄存器中——一个存储低64位,另一个存储高64位。
1 | __int128_t x = 1; |
在上面的例子中:
- 通过将
x右移64位,提取出128位值的高64位。 - 低64位通过将128位类型强制转换为64位类型来提取,这会丢弃高64位(即截断)。
128位整数的限制: 除了乘法运算,128位整数通常作为两个独立的64位寄存器进行处理。因此,在大多数情况下,使用一个完整的128位类型并不实际,因此对其的支持通常仅限于诸如乘法之类的操作。以下是一个简单的128位整数加法函数的例子,它使用了两个64位寄存器:
1 | __int128_t add(__int128_t a, __int128_t b) { |
当这个函数被编译时,它会被转换成汇编代码,通过两个64位值来进行处理。例如:
1 | add: |
在这段汇编代码中:
rax和rdx分别存储操作数a的低64位和高64位。rsi和rcx分别存储操作数b的低64位和高64位。- 对两个部分分别进行加法操作,进位操作(
adc)确保了低64位加法溢出时,高64位部分正确处理。
其他平台:
其他平台,如ARM,使用专门的指令(如mulhi、mullo)来返回乘法结果的高低部分,这使得处理大于字长的值变得更容易。类似地,x86
SIMD扩展也有32位指令来处理此类情况。
整数除法
与其他算术操作相比,除法通常表现得非常糟糕。无论是浮点数还是整数除法,硬件实现都非常复杂。其电路在算术逻辑单元(ALU)中占用了大量空间,计算过程涉及多个阶段,因此除法指令(div)及其相关操作通常需要10到20个时钟周期来完成。较小的数据类型可能会稍微减少延迟,但除法操作的复杂度和延迟依旧较高。
由于没有人想为取余操作单独实现一套逻辑,div指令同时负责除法和取余的计算。要执行一个32位整数除法,必须将被除数放入eax寄存器,并将除数作为唯一操作数传递给div指令。执行后,商(quotient)将存储在eax寄存器中,而余数(remainder)则存储在edx寄存器中。
需要注意的是,被除数必须存储在两个寄存器中:eax和edx。这种机制使得64位除以32位甚至128位除以64位的除法成为可能,类似于128位乘法的处理方式。在执行普通的32位整数除法时,我们需要将eax寄存器的值扩展为64位,并将高位部分存储在edx中:
1 | div(int, int): |
为了理解为什么需要扩展的实现,我们先来了解以下cdq指令是什么。cdq
的全称是 Convert Double to Quadword,它的作用是:
- 输入:
eax(32 位整数) - 输出:
- 如果
eax是正数,edx设为0 - 如果
eax是负数,edx设为0xFFFFFFFF(即-1)
- 如果
换句话说,cdq 负责对 eax 进行
符号扩展,确保 edx:eax 组成一个正确的
64 位被除数。x86 的
idiv(有符号除法)和
div(无符号除法)指令是针对 64
位被除数 ÷ 32 位除数 设计的,而 eax 只有
32 位,为了让 idiv
进行除法运算,必须扩展为 64 位 存储在
edx:eax 组合中。
对于无符号除法,你只需将edx寄存器置为0,以避免它干扰计算:
1 | div(unsigned, unsigned): |
在这两种情况下,除了eax中的商外,你还可以通过edx访问余数。
取余操作
1 | mod(unsigned, unsigned): |
优化方式
整数除法在 CPU 中的执行速度通常非常慢,即使是完全由硬件实现的
div
指令,其执行周期也远高于加法或乘法。为了解决这个问题,如果
除数是一个常数,可以使用一些优化技巧,将
除法转换为乘法,以提高效率。
如果除数是 2 的幂,可以使用
二进制移位 来替代
div,从而极大地提高计算速度:
x / 2^n可以用 右移 (x >> n) 代替。x % 2^n可以用 按位与 (x & (2^n - 1)) 代替。
还有种方式是在编译阶段估算除数的倒数d,然后在运行时直接乘上d即可。
Barrett 约简(Barrett Reduction)
上述d的估算成了我们现在待解决的问题,我们可以改写d为:
x / (10^9 + 7),可以用以下汇编指令代替:
1 | ; 输入 (rdi): x |
这样就避免了昂贵的整数除法。现在我们的问题就变成了是否肯定存在并能找到那么一组m与s可以进行表示1/y。
如果我们指定一个固定的移位值s,那么我们的m主要有两种选择,
最坏情况发生在最接近 1 的除法,即:
总的来说,巴雷特约简就是将运行时的除法开销转移到了编译时。
Lemire 约简(Lemire Reduction)
Barrett 约简是一种比较复杂的算法,而且它通过间接计算来生成一系列指令用于求模运算,因此可能会带来一些性能上的开销。而一种新的方法——Lemire 降维法(2019年提出)则更简单,并且在某些情况下,实际上比 Barrett 方法更快。尽管目前这个方法还没有一个公认的名称,但在这里我们称其为 Lemire 约简。
假设我们有一个整数 179 和除数
6,它们的除法结果可以表示为:
- 整数部分(29)可以通过简单地取浮点数的小数点前部分(即取整)来获得。
- 小数部分(即分数
)可以通过取小数点后的部分得到。 - 余数(5)则可以通过将小数部分乘以除数
y来得到。
对于 32 位整数,我们可以设定一个常量 s = 64,并查看在
乘法和移位 方案中的计算方式: m 来乘以
x,然后通过移位和取整来实现。
如果我们不是取高位(整数部分),而是取低位,这就对应于小数部分。如果我们再将其乘以除数
y,并取整,就能得到余数:
以下是实现 Lemire 约简的代码:
1 | uint32_t y; |
除法可除性检查
我们还可以通过乘法来检查 x 是否能被 y
整除。具体地,x 能被 y
整除当且仅当:如果乘法后的小数部分(即 m * x 的低 64
位)没有超过 m,则 x 可被 y
整除。如果超过了,乘法的结果在再次与 y 相乘并右移 64
位时会得到一个非零数值。
1 | bool is_divisible(uint32_t x) { |
缺点
Lemire 约简的唯一缺点是,它需要使用原始整数类型的 4 倍大小来进行乘法操作,而其他约简方法(如 Barrett 约简)只需要双精度浮点数就可以工作。因此,这种方法在内存上可能会有一定的开销。
- 标题: Algorithmica-HPC研读记录2
- 作者: collectcrop
- 创建于 : 2025-03-15 20:58:38
- 更新于 : 2025-03-16 00:03:26
- 链接: https://collectcrop.github.io/2025/03/15/Algorithmica-HPC研读记录2/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
