CUDA编程模型初探
安装
可以在官网选择下载适合自己版本的cuDNN 。
然后下载CUDA ,根据安装程序的提示配置即可。
之后安装完成后可以把安装好的CUDA根目录下的bin目录设置为环境变量,然后用nvcc 测试一下是否设置成功。
然后把之前下好的cuDNN 中的lib、bin、include目录下的所有文件都拷贝到我们CUDA 对应的目录。
然后我们打开VS2022就能创建一个CUDA项目了。
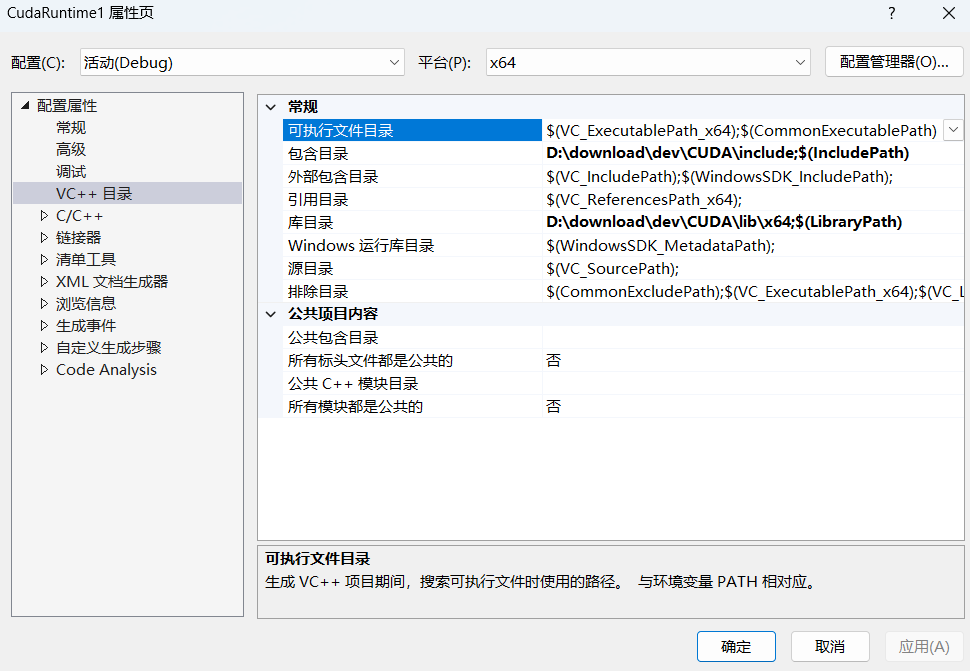
如果项目模板文件存在问题,我们可以手动对环境进行配置。右键项目→属性→
配置属性→
VC++目录 ,进去把包含目录指向我们下载的CUDA 的include 目录,把库目录指向我们下载的CUDA的lib/x64 目录。正常而言这里不需要我们进行手动配置。
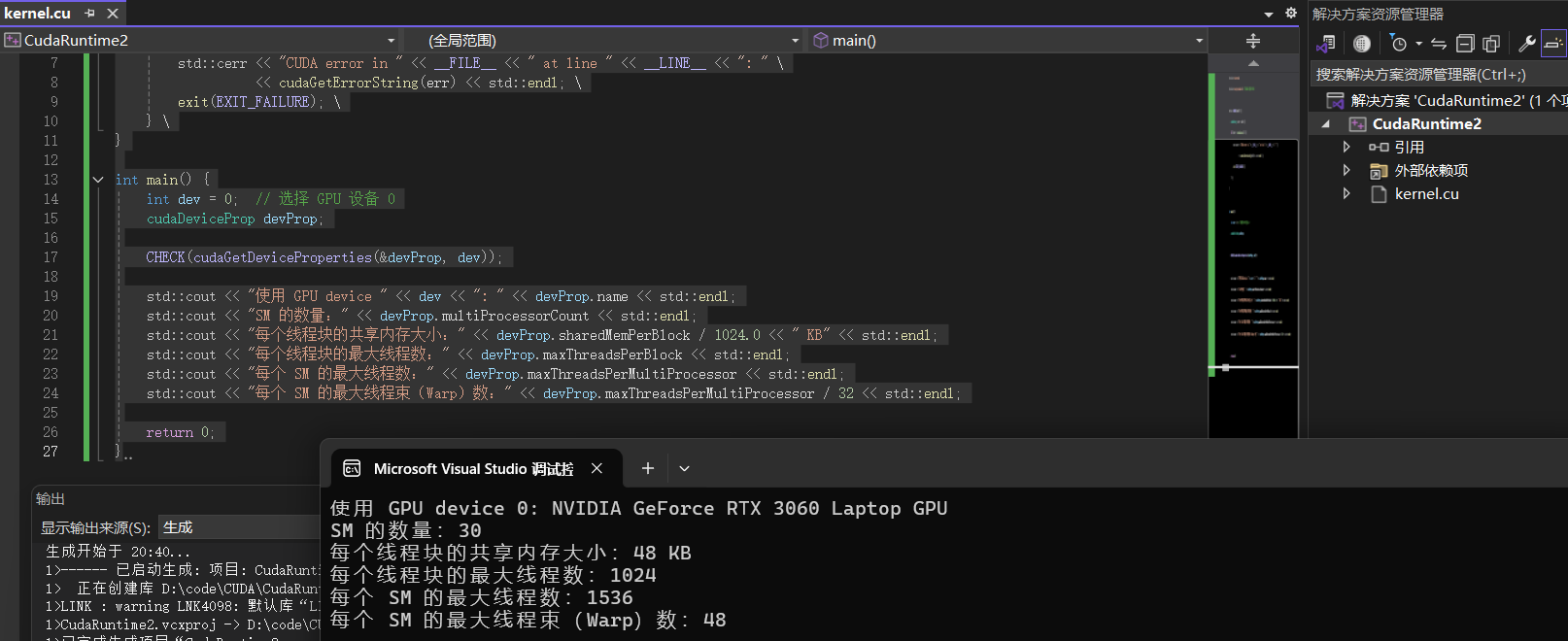
然后我们可以用一下程序跑一下,来查看我们的GPU的一些基本情况。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 #include <iostream> #include <cuda_runtime.h> #define CHECK(call) { \ cudaError_t err = call; \ if (err != cudaSuccess) { \ std::cerr << "CUDA error in " << __FILE__ << " at line " << __LINE__ << ": " \ << cudaGetErrorString(err) << std::endl; \ exit(EXIT_FAILURE); \ } \ } int main () int dev = 0 ; cudaDeviceProp devProp; CHECK (cudaGetDeviceProperties (&devProp, dev)); std::cout << "使用 GPU device " << dev << ": " << devProp.name << std::endl; std::cout << "SM 的数量:" << devProp.multiProcessorCount << std::endl; std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl; std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl; std::cout << "每个 SM 的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl; std::cout << "每个 SM 的最大线程束(Warp)数:" << devProp.maxThreadsPerMultiProcessor / 32 << std::endl; return 0 ; }
CUDA编程模型
在CUDA中,host 和device 是两个重要的概念,我们用host指代CPU及其内存,而用device指代GPU及其内存。CUDA程序中既包含host程序,又包含device程序,它们分别在CPU和GPU上运行。同时,host与device之间可以进行通信,这样它们之间可以进行数据拷贝。
CUDA 代码的核心是核函数(Kernel Function),使用
__global__ 关键字定义,并通过 <<<gridDim,
blockDim>>> 语法启动:
1 2 3 4 5 6 __global__ void add (int *a, int *b, int *c, int N) { int idx = blockIdx.x * blockDim.x + threadIdx.x; if (idx < N) { c[idx] = a[idx] + b[idx]; } }
主要会用到的三个函数类型限定词如下:
__global__:在device上执行,从host中调用(一些特定的GPU也可以从device上调用),返回类型必须是void,不支持可变参数参数,不能成为类成员函数。注意用__global__定义的kernel是异步的,这意味着host不会等待kernel执行完就执行下一步。__device__:在device上执行,单仅可以从device中调用,不可以和__global__同时用。__host__:在host上执行,仅可以从host上调用,一般省略不写,不可以和__global__同时用,但可和__device__一起使用,此时函数会在device和host都编译。
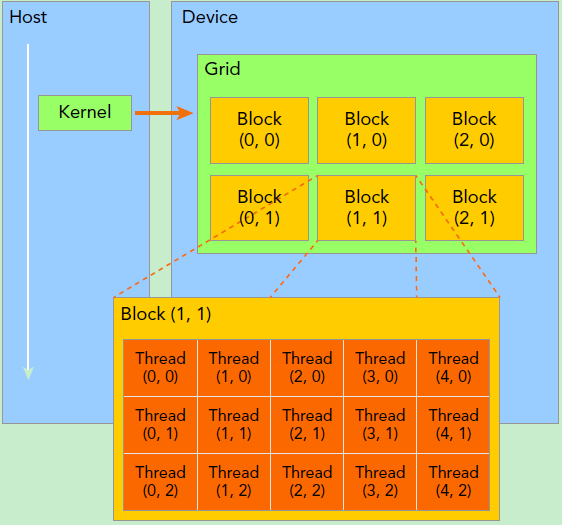
线程层次结构
线程(Thread) :CUDA
代码中的最小执行单元。
线程块(Block) :多个线程组成一个线程块,每个块在一个
SM 上执行。
网格(Grid) :多个线程块组成一个网格,控制整体计算任务。
grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构。CUDA
提供了一些内置变量来管理线程和线程块:
threadIdx.x、threadIdx.y、threadIdx.z:当前线程在线程块中的索引blockIdx.x、blockIdx.y、blockIdx.z:当前线程块在网格中的索引blockDim.x、blockDim.y、blockDim.z:线程块的大小gridDim.x、gridDim.y、gridDim.z:网格的大小
在 CUDA 编程中,一个 GPU 只能有一个 Grid,每次调用
kernel<<<gridDim, blockDim>>>();,都会启动
一个新的 Grid 。你可以多次调用 kernel 来创建多个
Grid。
1 2 kernel1<<<gridDim1, blockDim1>>>(...); kernel2<<<gridDim2, blockDim2>>>(...);
特点 :串行执行,每个 kernel
调用都会生成一个新的 Grid,但它们不会同时运行。
完整的索引计算:
1D 索引 (x 方向)
1 int idx = blockIdx.x * blockDim.x + threadIdx.x;
2D 索引 (x, y 方向)
1 2 int row = blockIdx.y * blockDim.y + threadIdx.y;int col = blockIdx.x * blockDim.x + threadIdx.x;
3D 索引 (x, y, z 方向)
适用于 三维网格、体渲染 (如 MRI、3D
物理模拟)。
1 2 3 int x = blockIdx.x * blockDim.x + threadIdx.x;int y = blockIdx.y * blockDim.y + threadIdx.y;int z = blockIdx.z * blockDim.z + threadIdx.z;
在 CUDA 计算架构中,Streaming Multiprocessor (SM) 是
GPU 计算的核心单元。每个 GPU 由多个 SM 组成。
一个 SM 可以看作是一个并行计算的“迷你
CPU”,但它专门优化用于 高吞吐量并行计算 。每个 SM
包含:
CUDA Cores (流处理器,SP):用于执行标量运算Warp Scheduler (线程束调度器):控制 32
个线程(warp)并行执行寄存器 (Registers) :线程级别的高效存储共享内存 (Shared Memory) :线程块 (Thread Block)
级别的快速存储Tensor Cores (部分 GPU 具有):用于矩阵乘法和 AI
计算Special Function Units
(SFU) :执行复杂数学运算,如三角函数和指数运算LD/ST 单元 (Load/Store Units) :处理全局内存(Global
Memory)读写
一个线程块只能在一个SM上被调度,SM一般可以调度多个线程块。
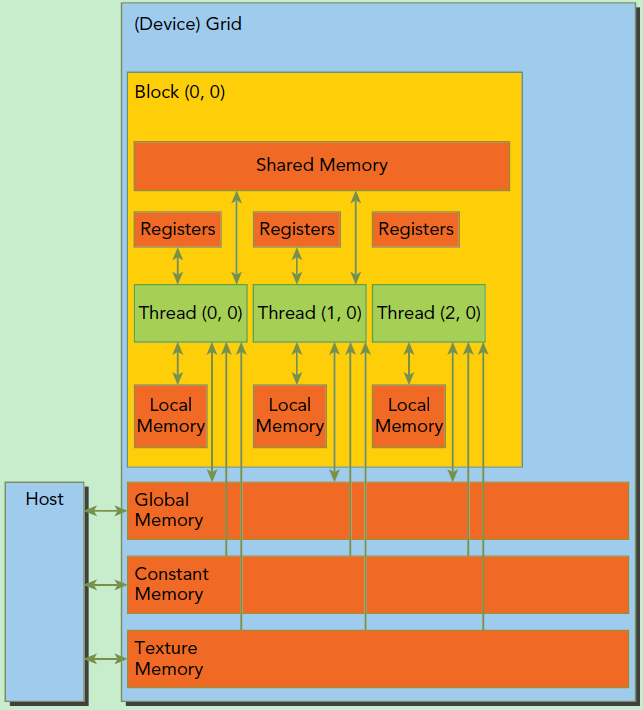
CUDA内存模型
每个线程有自己的私有本地内存(Local
Memory),而每个线程块有包含共享内存(Shared
Memory),可以被线程块中所有线程共享,其生命周期与线程块一致。此外,所有的线程都可以访问全局内存(Global
Memory)。还可以访问一些只读内存块:常量内存(Constant
Memory)和纹理内存(Texture Memory)。
内存管理API
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 cudaError_t cudaMalloc (void ** devPtr, size_t size) ; cudaError_t cudaFree (void ** devPtr) ; cudaError_t cudaMemcpy (void * dst, const void * src, size_t count, cudaMemcpyKind kind) ; enum __device_builtin__ cudaMemcpyKind { cudaMemcpyHostToHost = 0 , cudaMemcpyHostToDevice = 1 , cudaMemcpyDeviceToHost = 2 , cudaMemcpyDeviceToDevice = 3 , cudaMemcpyDefault = 4 }; cudaError_t cudaMallocManaged (void **devPtr, size_t size, unsigned int flag=0 ) ;
向量加法实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <iostream> #include <cuda_runtime.h> #include <device_launch_parameters.h> __global__ void add (float * x, float * y, float * z, int n) int index = threadIdx.x + blockIdx.x * blockDim.x; int stride = blockDim.x * gridDim.x; for (int i = index; i < n; i += stride) { z[i] = x[i] + y[i]; } } int main () int N = 1 << 20 ; int nBytes = N * sizeof (float ); float *x, *y, *z; x = (float *)malloc (nBytes); y = (float *)malloc (nBytes); z = (float *)malloc (nBytes); for (int i = 0 ; i < N; ++i) { x[i] = 10.0 ; y[i] = 20.0 ; } float *d_x, *d_y, *d_z; cudaMalloc ((void **)&d_x, nBytes); cudaMalloc ((void **)&d_y, nBytes); cudaMalloc ((void **)&d_z, nBytes); cudaMemcpy ((void *)d_x, (void *)x, nBytes, cudaMemcpyHostToDevice); cudaMemcpy ((void *)d_y, (void *)y, nBytes, cudaMemcpyHostToDevice); dim3 blockSize (256 ) ; dim3 gridSize ((N + blockSize.x - 1 ) / blockSize.x) ; add <<< gridSize, blockSize >>>(d_x, d_y, d_z, N); cudaMemcpy ((void *)z, (void *)d_z, nBytes, cudaMemcpyDeviceToHost); float maxError = 0.0 ; for (int i = 0 ; i < N; i++) maxError = fmax (maxError, fabs (z[i] - 30.0 )); std::cout << "最大误差: " << maxError << std::endl; cudaFree (d_x); cudaFree (d_y); cudaFree (d_z); free (x); free (y); free (z); return 0 ; }
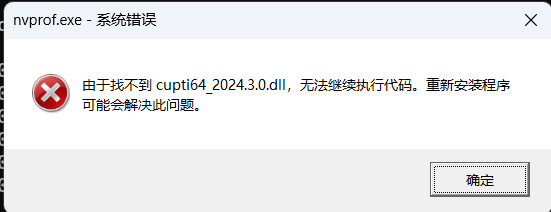
然后我们可以用nvprof 工具进行性能测试,可能会有如下报错,我们只需进入CUDA根目录下的extras\CUPTI\lib64复制里面对应的dll,然后放在CUDA根目录下的bin 目录即可。但正常执行还是报错,因为nvprof是旧工具,已经不能用了,换用Nsight
systems(nsys)。该可执行文件在C:\Program Files\NVIDIA Corporation\Nsight Systems 2024.4.2\target-windows-x64目录下,需要手动设置下环境变量。
然后进行分析
1 2 nsys profile CudaRuntime2.exe # 先生成.nsys-rep文件 nsys stats report1.nsys-rep
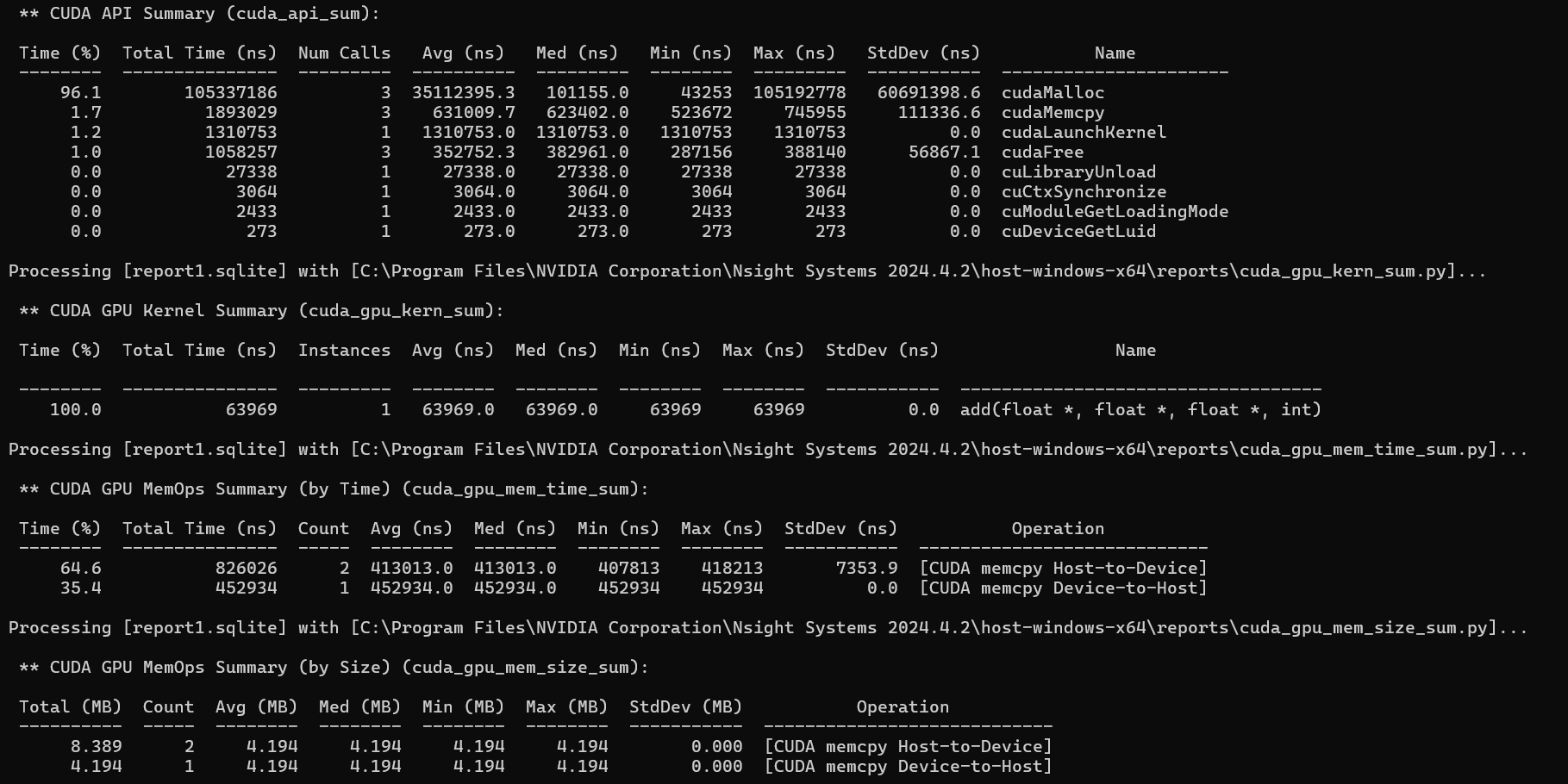
能看到我们的kernel 函数add 平均总执行时间为63969.0ns 。然后我们可以调整block 大小进行对比查看结果(上图是bolocksize为256的结果)。经测试size
64为98125.0ns ,128为69123.0ns ,512为72099.0ns 。可以看出blocksize并不是越大越好的,要适当调整。
上述代码也可以利用host和device共享的托管内存进行管理,简化了内存申请的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 int main () int N = 1 << 20 ; int nBytes = N * sizeof (float ); float * x, * y, * z; cudaMallocManaged ((void **)&x, nBytes); cudaMallocManaged ((void **)&y, nBytes); cudaMallocManaged ((void **)&z, nBytes); for (int i = 0 ; i < N; ++i) { x[i] = 10.0 ; y[i] = 20.0 ; } dim3 blockSize (256 ) ; dim3 gridSize ((N + blockSize.x - 1 ) / blockSize.x) ; add << < gridSize, blockSize >> > (x, y, z, N); cudaDeviceSynchronize (); float maxError = 0.0 ; for (int i = 0 ; i < N; i++) maxError = fmax (maxError, fabs (z[i] - 30.0 )); std::cout << "最大误差: " << maxError << std::endl; cudaFree (x); cudaFree (y); cudaFree (z); return 0 ; }
矩阵乘法实例
这里由于矩阵是二维的,所以我们要逻辑上把grid和block都设置为2维的方便调用。主要的思路就是让位于(x,y)唯一定位到的thread处理矩阵x行y列的数据,所以在划分grid 和block 时需要刚好让每个矩阵中的某个元素与一个thread 一一对应。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 #include <iostream> #include <cuda_runtime.h> #include <device_launch_parameters.h> using namespace std;struct Matrix { int width; int height; float * elements; }; __device__ float getElem (Matrix *A, int row, int col) { return A->elements[row * A->width + col]; } __device__ void setElem (Matrix* A, int row, int col, float val) { A->elements[row * A->width + col] = val; } __global__ void mul (Matrix* A, Matrix* B, Matrix* C) { float Cvalue = 0.0 ; int row = threadIdx.y + blockIdx.y * blockDim.y; int col = threadIdx.x + blockIdx.x * blockDim.x; for (int i = 0 ; i < A->width;++i) { Cvalue += getElem (A, row, i) * getElem (B, i, col); } setElem (C, row, col, Cvalue); } int main () int width = 1 << 10 ; int height = 1 << 10 ; Matrix* A, * B, * C; cudaMallocManaged ((void **)&A, sizeof (Matrix)); cudaMallocManaged ((void **)&B, sizeof (Matrix)); cudaMallocManaged ((void **)&C, sizeof (Matrix)); int nBytes = width * height * sizeof (float ); cudaMallocManaged ((void **)&A->elements, nBytes); cudaMallocManaged ((void **)&B->elements, nBytes); cudaMallocManaged ((void **)&C->elements, nBytes); A->height = height; A->width = width; B->height = height; B->width = width; C->height = height; C->width = width; for (int i = 0 ; i < width*height; ++i) { A->elements[i] = 1.0f ; B->elements[i] = 2.0f ; } dim3 blockSize (32 ,32 ) ; dim3 gridSize ((width + blockSize.x - 1 ) / blockSize.x, (height + blockSize.y - 1 ) / blockSize.y) ; cout << "blockSize: " << blockSize.x << "x" << blockSize.y << endl; cout << "gridSize: " << gridSize.x << "x" << gridSize.y << endl; mul << < gridSize, blockSize >> > (A, B, C); cudaDeviceSynchronize (); float maxError = 0.0 ; for (int i = 0 ; i < width * height; ++i) maxError = fmax (maxError, fabs (C->elements[i] - 2 * width)); std::cout << "最大误差: " << maxError << std::endl; return 0 ; }
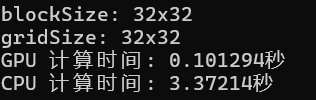
我们也可以对GPU与CPU进行矩阵乘法运算的效率进行一个简单的对比:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 #include <iostream> #include <cuda_runtime.h> #include <device_launch_parameters.h> #include <chrono> using namespace std;struct Matrix { int width; int height; float * elements; }; __device__ float getElem (Matrix *A, int row, int col) { return A->elements[row * A->width + col]; } __device__ void setElem (Matrix* A, int row, int col, float val) { A->elements[row * A->width + col] = val; } __global__ void mul (Matrix* A, Matrix* B, Matrix* C) { float Cvalue = 0.0 ; int row = threadIdx.y + blockIdx.y * blockDim.y; int col = threadIdx.x + blockIdx.x * blockDim.x; for (int i = 0 ; i < A->width;++i) { Cvalue += getElem (A, row, i) * getElem (B, i, col); } setElem (C, row, col, Cvalue); } void matMulCPU (Matrix* A, Matrix* B, Matrix* C) for (int i = 0 ; i < A->height; ++i) { for (int j = 0 ; j < B->width; ++j) { float sum = 0.0 ; for (int k = 0 ; k < A->width; ++k) { sum += A->elements[i * A->width + k] * B->elements[k * B->width + j]; } C->elements[i * C->width + j] = sum; } } } int main () int width = 1 << 10 ; int height = 1 << 10 ; Matrix* A, * B, * C, *D; cudaMallocManaged ((void **)&A, sizeof (Matrix)); cudaMallocManaged ((void **)&B, sizeof (Matrix)); cudaMallocManaged ((void **)&C, sizeof (Matrix)); cudaMallocManaged ((void **)&D, sizeof (Matrix)); int nBytes = width * height * sizeof (float ); cudaMallocManaged ((void **)&A->elements, nBytes); cudaMallocManaged ((void **)&B->elements, nBytes); cudaMallocManaged ((void **)&C->elements, nBytes); cudaMallocManaged ((void **)&D->elements, nBytes); A->height = height; A->width = width; B->height = height; B->width = width; C->height = height; C->width = width; D->height = height; D->width = width; for (int i = 0 ; i < width*height; ++i) { A->elements[i] = 1.0f ; B->elements[i] = 2.0f ; } dim3 blockSize (32 ,32 ) ; dim3 gridSize ((width + blockSize.x - 1 ) / blockSize.x, (height + blockSize.y - 1 ) / blockSize.y) ; cout << "blockSize: " << blockSize.x << "x" << blockSize.y << endl; cout << "gridSize: " << gridSize.x << "x" << gridSize.y << endl; auto start_gpu = std::chrono::high_resolution_clock::now (); mul << < gridSize, blockSize >> > (A, B, C); cudaDeviceSynchronize (); auto end_gpu = std::chrono::high_resolution_clock::now (); std::chrono::duration<double > duration_gpu = end_gpu - start_gpu; std::cout << "GPU 计算时间: " << duration_gpu.count () << "秒" << std::endl; auto start_cpu = std::chrono::high_resolution_clock::now (); matMulCPU (A, B, C); auto end_cpu = std::chrono::high_resolution_clock::now (); std::chrono::duration<double > duration_cpu = end_cpu - start_cpu; std::cout << "CPU 计算时间: " << duration_cpu.count () << "秒" << std::endl; cudaFree (A->elements); cudaFree (B->elements); cudaFree (C->elements); cudaFree (D->elements); cudaFree (A); cudaFree (B); cudaFree (C); cudaFree (D); return 0 ; }
发现GPU计算的效率大概是CPU计算效率的30倍!
获取 blockSize 和 gridSize
限制
在 CUDA 中,blockSize(线程块大小)和
gridSize(网格大小)的上限取决于 GPU
的架构 。这些上限可以使用 CUDA 设备查询 API
获取。可以使用 cudaGetDeviceProperties() 来查询
最大线程数、线程块大小和网格大小 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 #include <iostream> #include <cuda_runtime.h> int main () cudaDeviceProp prop; int device; cudaGetDevice (&device); cudaGetDeviceProperties (&prop, device); std::cout << "设备名称: " << prop.name << std::endl; std::cout << "SM 数量: " << prop.multiProcessorCount << std::endl; std::cout << "最大线程块大小 (blockSize): " << prop.maxThreadsPerBlock << std::endl; std::cout << "每个维度的最大线程数 (blockDim): (" << prop.maxThreadsDim[0 ] << ", " << prop.maxThreadsDim[1 ] << ", " << prop.maxThreadsDim[2 ] << ")" << std::endl; std::cout << "最大网格大小 (gridSize): (" << prop.maxGridSize[0 ] << ", " << prop.maxGridSize[1 ] << ", " << prop.maxGridSize[2 ] << ")" << std::endl; return 0 ; }
参考内容
https://zhuanlan.zhihu.com/p/34587739