复杂程序fuzz初探
复杂程序fuzz初探
什么是fuzz
Fuzz(Fuzzing,模糊测试)是一种自动化测试技术,用于发现程序中的漏洞或异常行为。它的核心思想是向程序输入大量随机、畸形(fuzzed)或异常的数据,观察程序的响应,以检测潜在的崩溃、内存泄漏、安全漏洞等问题。适用于二进制程序测试和Web 渗透测试。结合代码覆盖率分析和符号执行,现代 Fuzzing 工具能够高效发现程序中的安全漏洞,在 CTF、漏洞研究、软件测试等领域广泛应用。一个非常常用的工具是AFL++。
提到fuzz,我们经常听到另一个术语叫做插桩,插桩(Instrumentation)是一种在程序运行时插入额外代码的技术,主要用于:
- 监测代码覆盖率
- 记录执行路径
- 检测异常(如崩溃、内存错误)
AFL++ 主要通过编译时插桩来优化 Fuzzing 过程,比如:
- 在每个基本块(Basic Block)入口添加统计代码。
- 记录哪些路径已被执行。
- 反馈给 Fuzzing 引擎,生成更有效的输入数据。
AFL++安装
1 | git clone https://github.com/AFLplusplus/AFLplusplus |
编译方式如下,与gcc使用类似,这里可能会显示afl-gcc已经被移除了,那么我们可以换用afl-clang-fast进行编译。

1 | afl-clang-fast fuzz.c -o fuzz |
然后我们需要准备输入和输出两个目录,输入目录里存
1 | mkdir input |
提升fuzz效率
但是这里我发现跑的速度极慢,11分钟才完成了242个testcase。
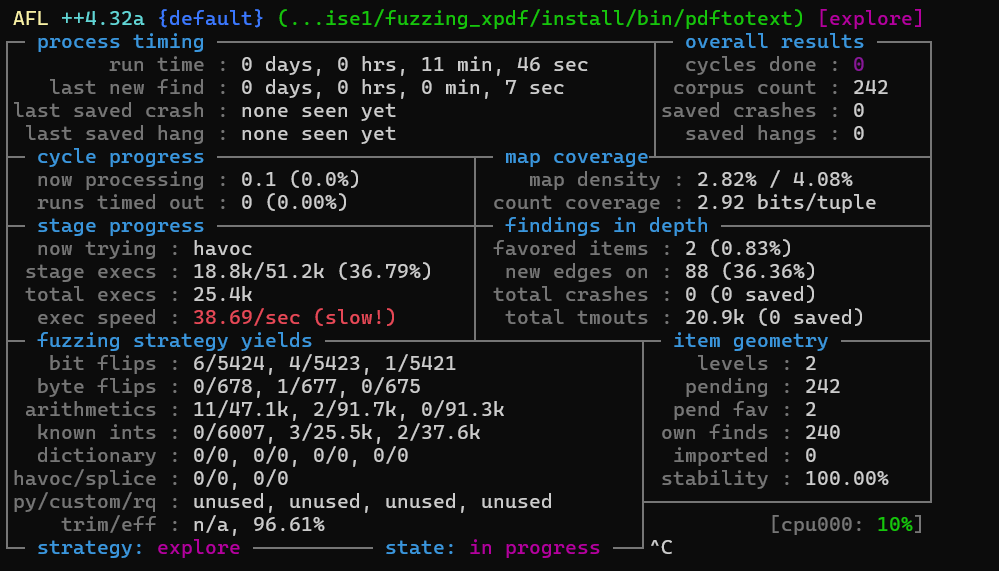
这里我尝试了多进程一起跑,结果wsl直接炸盘。后面看了相关介绍才知道wsl性能差的原因。
WSL 的 Fork 机制效率低
- AFL++ 依赖
fork()来创建新进程,但 WSL 的fork()性能 比原生 Linux 差几十倍,因为它底层用的是 Windows 的进程模型。 - 影响:每次 AFL++ 运行新变异输入,都会导致 WSL 执行
fork(),使 fuzzing 速度极慢。
WSL I/O 性能较差
- AFL++ 需要频繁读取/写入测试用例文件,但 WSL
下的文件 I/O 比原生 Linux 慢 10 倍以上(尤其是
/mnt挂载 Windows 磁盘时)。 - 影响:
exec speed变得很慢cycles done进度很慢timeouts过多
WSL 不能直接访问裸机 CPU
- WSL 运行在 Hyper-V
之上,但没有完整的虚拟化支持,所以:
- 不能利用 CPU 的 fuzzing 相关优化指令
afl-fuzz可能不能充分利用 CPU 多核- 性能远远低于裸机 Linux
所以这里换用vmware来作为虚拟的环境。这里github项目给了一个镜像。用户名为fuzz,密码为fuzz。
Fuzzing101例题复现
项目地址:https://github.com/antonio-morales/Fuzzing101/
Exercise 1
fuzz
环境准备:
1 | mkdir fuzzing_xpdf && cd fuzzing_xpdf/ |
用export来暂时将我们装好的程序所在bin目录加入PATH环境变量,方便我们使用命令。
1 | export PATH=path/to/fuzzing_xpdf/install/bin:$PATH |
然后可以找个目录下我们试用的pdf文件。
1 | mkdir pdf_examples && cd pdf_examples |
其中github教学中有个pdf的下载地址失效了,这里我自己写了个markdown文件转成pdf当作第三个输入种子用。内容是Test seed pdf file here,2级标题。
实际上我们如果要结合afl++来测这个xpdf的程序的话,我们需要用afl-clang-fast来对其进行编译。我们需要先把前面下好的install删了,然后清空所有之前编译好的文件。
1 | rm -r install |
然后我们就可以把fuzzer跑起来了。
1 | afl-fuzz -i path/to/fuzzing_xpdf/pdf_examples -o path/to/fuzzing_xpdf/out/ -s 123 -- path/to/fuzzing_xpdf/install/bin/pdftotext @@ path/to/fuzzing_xpdf/output |
指令各部分拆解
| 选项 | 作用 |
|---|---|
afl-fuzz |
启动 AFL++ fuzz 测试工具 |
-i $HOME/fuzzing_xpdf/pdf_examples/ |
指定初始输入样本的目录,AFL++ 会从这里拿 PDF 文件作为初始种子输入 |
-o $HOME/fuzzing_xpdf/out/ |
指定 AFL++ 的输出目录,用于保存 fuzz 过程中的崩溃、超时、变异过的样本等 |
-s 123 |
指定 fuzzing 使用的随机种子(123),这样 fuzzing 的变异是可复现的,适合实验和调试 |
-- |
分隔符,告诉 AFL++,后面的都是被 fuzz 的目标程序及其参数 |
$HOME/fuzzing_xpdf/install/bin/pdftotext |
被 fuzz 的目标程序,这里是 pdftotext,Xpdf 项目中的 PDF
转文本工具 |
@@ |
占位符,AFL++ 会在每次 fuzz 时自动用一个输入文件的路径替换
@@ |
$HOME/fuzzing_xpdf/output |
pdftotext 的输出路径,转出来的文本会放到这里,不影响
fuzzing 行为,只是程序的正常参数 |
可能会有如下报错:
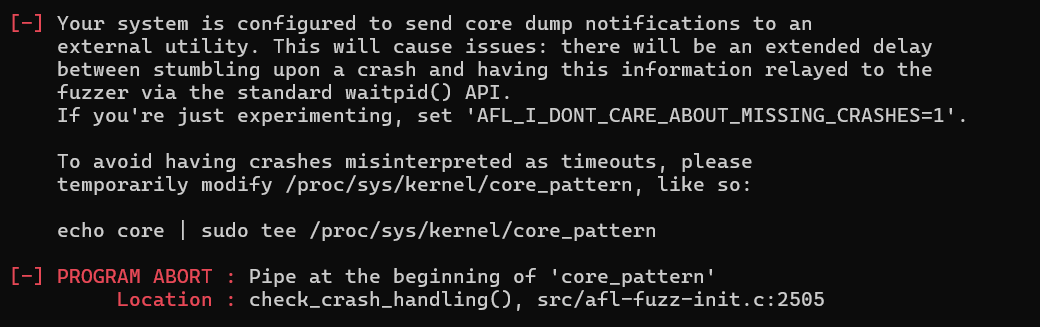
这说明 Linux 系统当前配置了
core_pattern,把崩溃的程序信息重定向到外部的 crash
handler(比如 apport,
systemd-coredump, core_collector
之类的工具)。
这会让 AFL++ 无法立即感知到目标程序崩溃,AFL++ 是靠
waitpid() 来实时感知崩溃的,但你现在系统的 core dump 是通过
pipe 发给了外部工具,导致 AFL++ 检测不到 crash,甚至误以为是
timeout。
临时关闭 core_pattern 的 pipe 重定向:
1 | echo core | sudo tee /proc/sys/kernel/core_pattern |
这样崩溃就会直接产出 core 文件,而不是送去外部工具,AFL++ 就能正常检测到 crash 了。
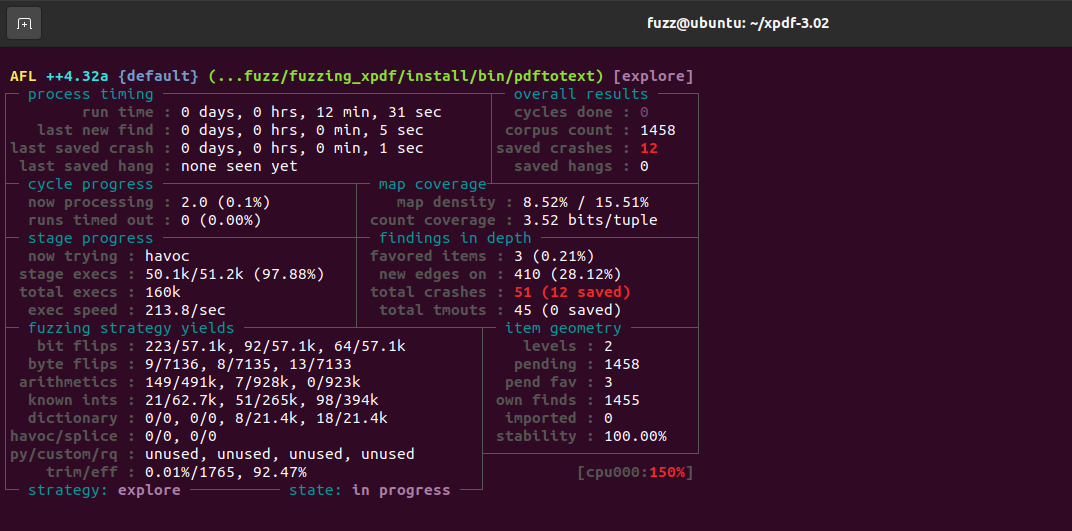
crash时的结果文件存在out/defalut/crashes中,我们可以选取一个样本,先确定是否能复现crash,具体来说就是用pdftotext再次跑一遍对应样本。
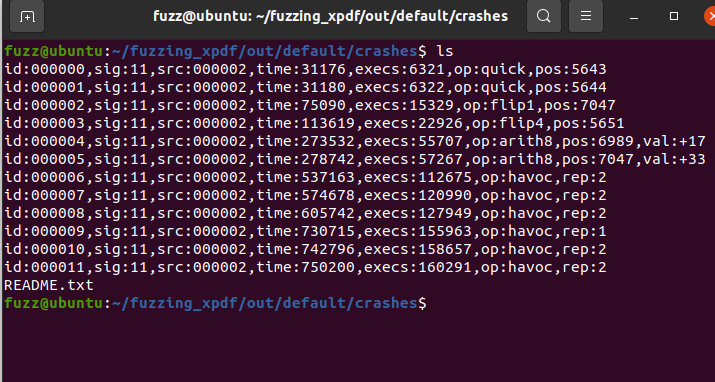
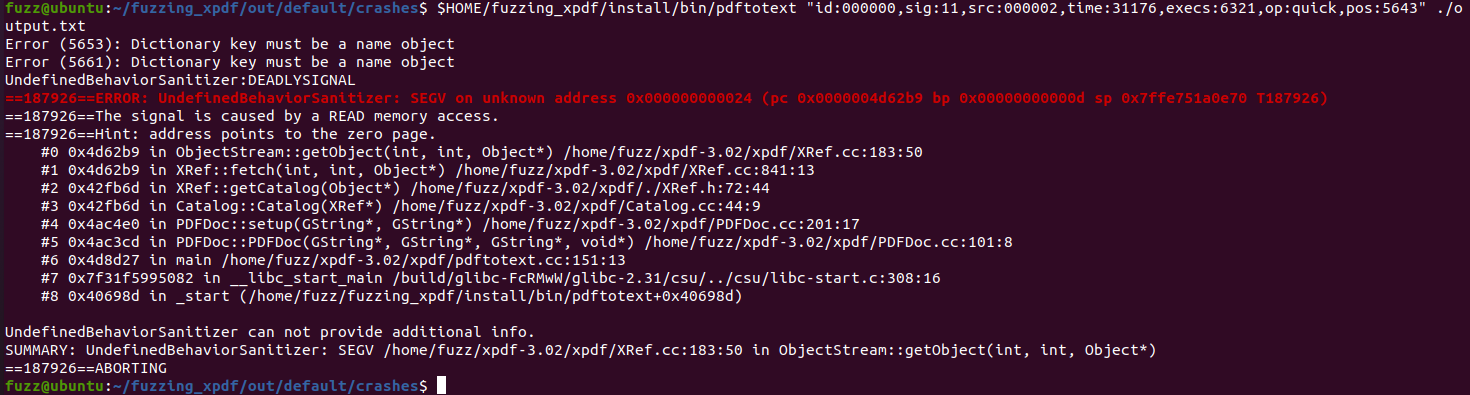
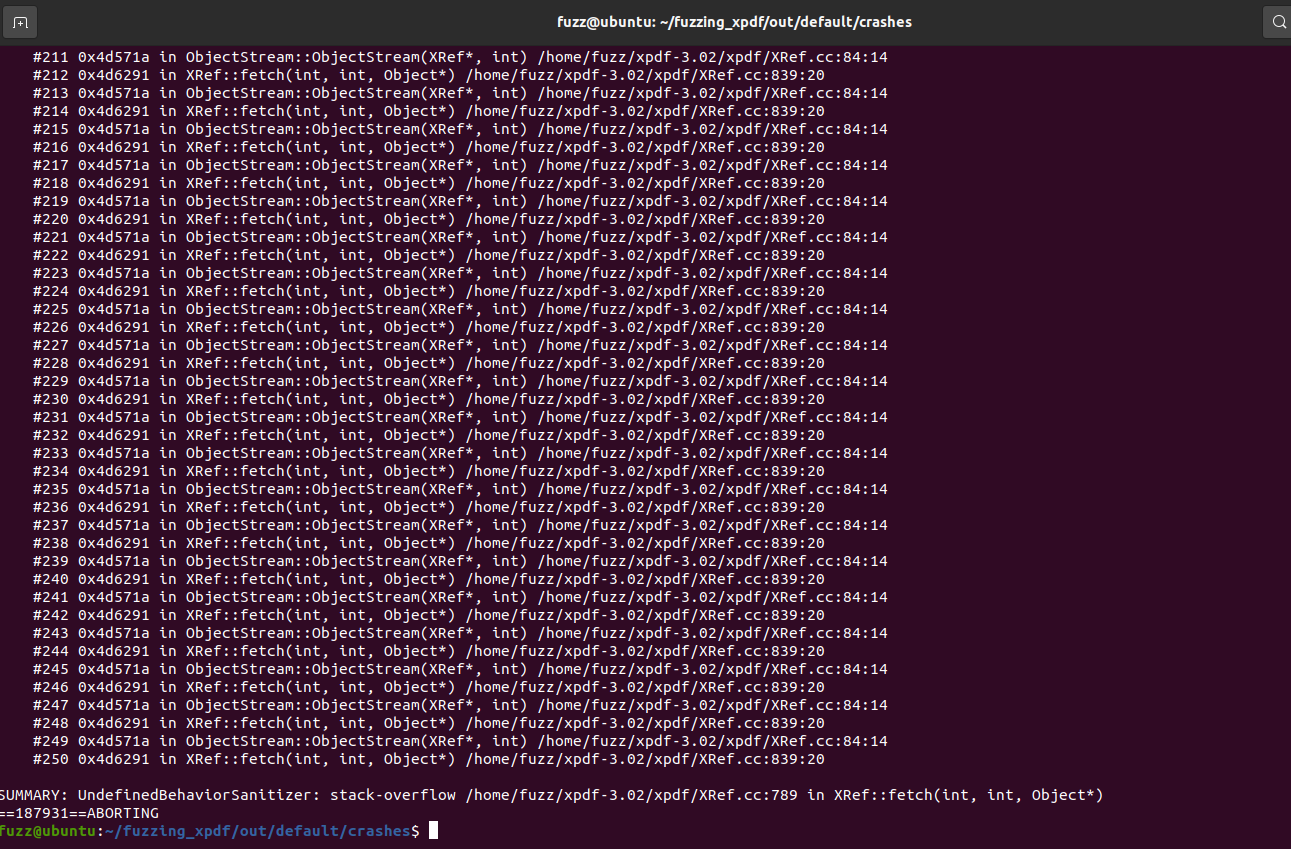
这里能看到崩溃时的调用栈,有样本是在执行getObject时崩溃的,也有样本发生了栈溢出(能看到函数调用栈深度来到了惊人的250)。
然后我们先来用pwndbg调试栈溢出的这个样本,首先是在call PDFDoc时崩溃退出的。
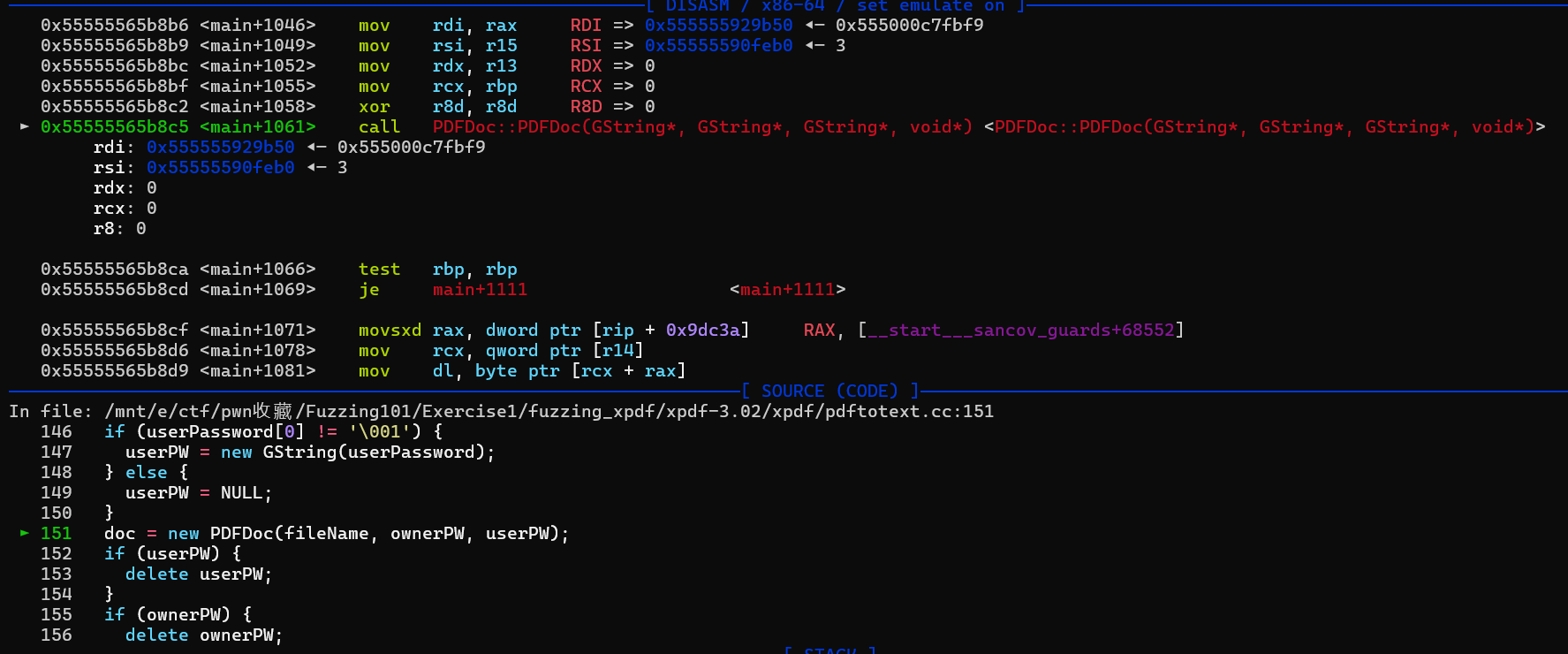
如果直接到崩溃点看内存映射以及寄存器,我们可以发现是rsp达到了stack段的起始位置,此时再次call一个函数就会超出可写的内存段,触发seg fault。
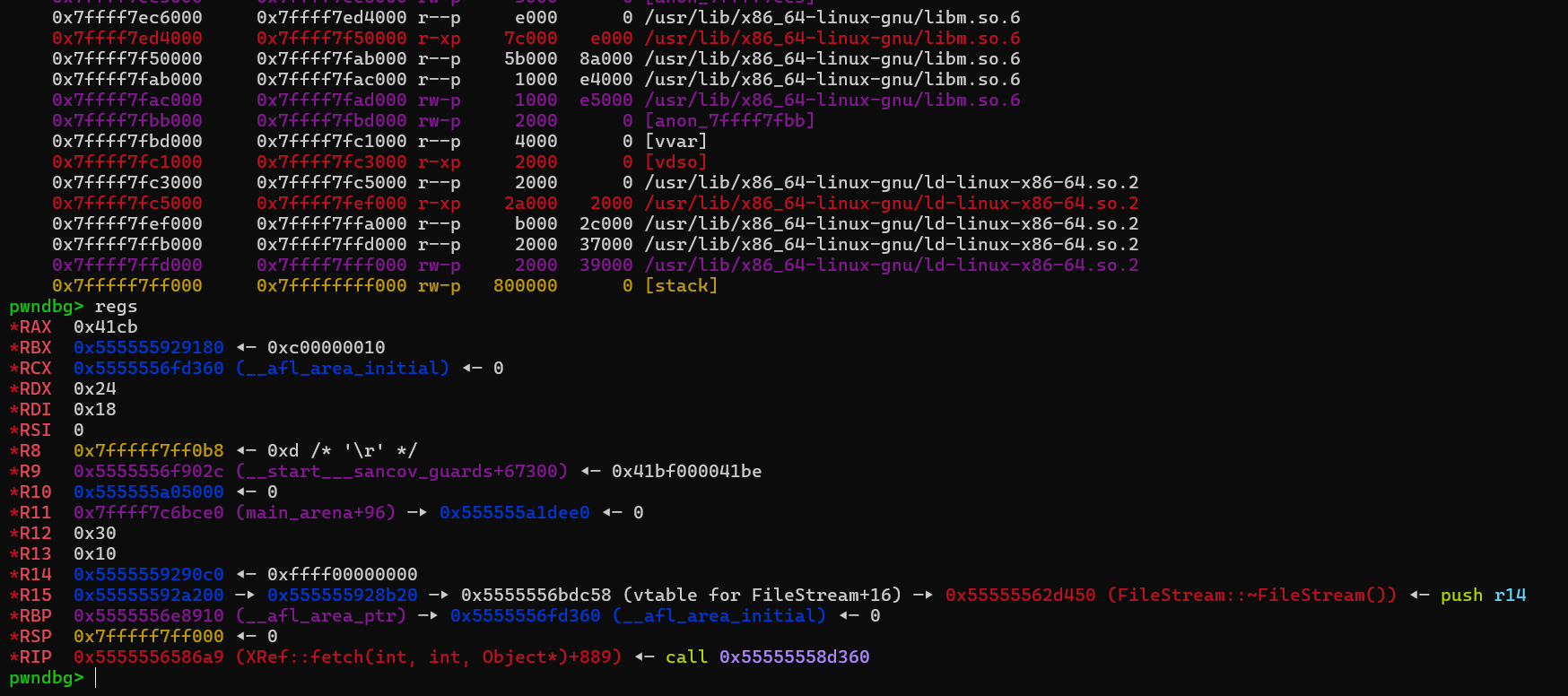
然后跟进去,发现call PDFDoc::setup会直接栈溢出崩溃,然后是call Catalog::Catalog崩溃,然后是call XRef::fetch崩溃。这样一直找也能逐渐找到漏洞所在点,其实我们如果观察之前fuzz时crashes结果直接扔pdftotext报错的结果,会发现栈溢出最后就是ObjectStream::ObjectStream与XRef::fetch反复互相调用导致的。
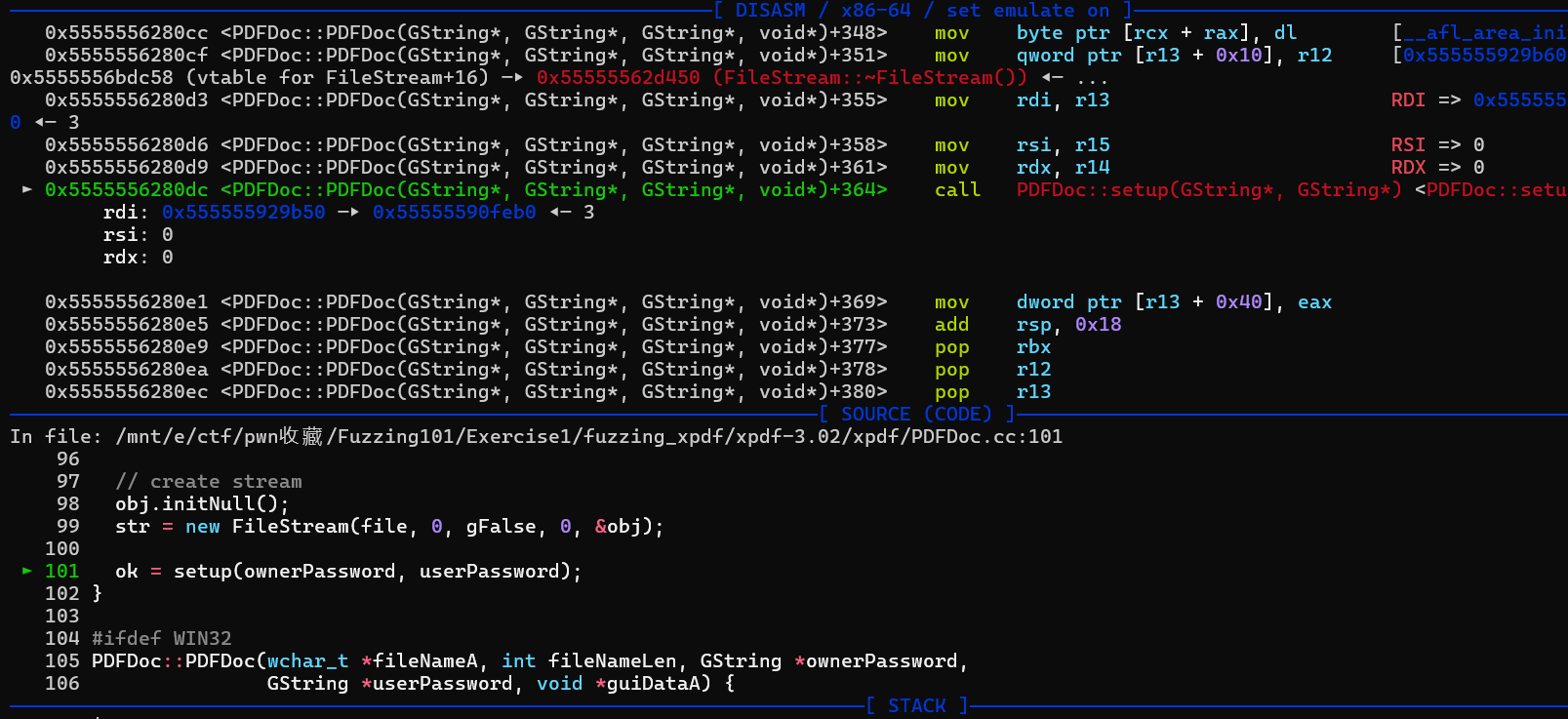
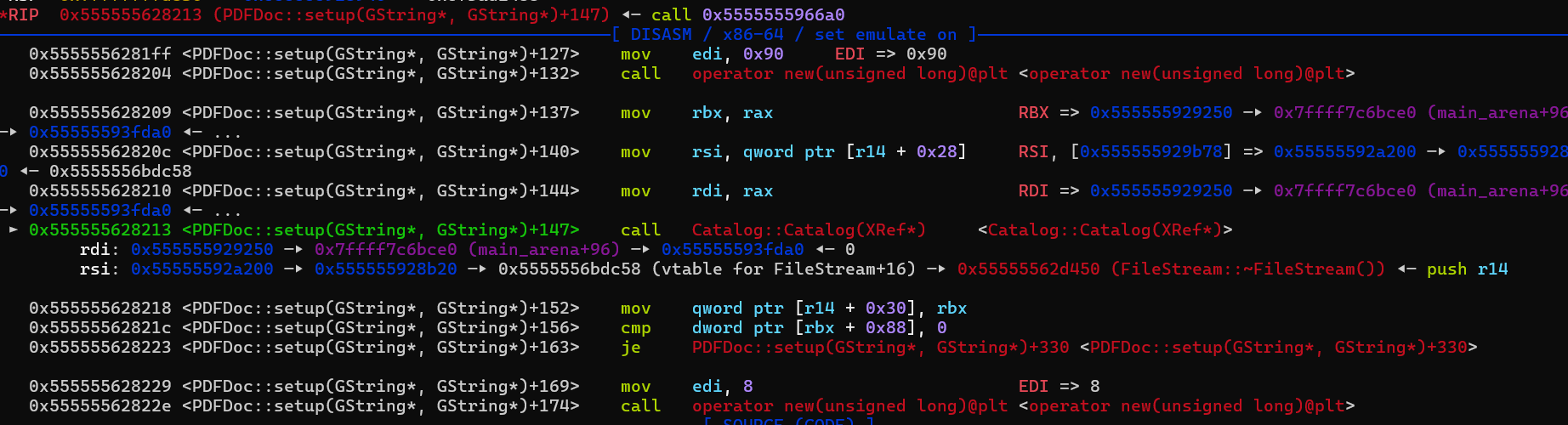
因为这里我们有程序的源码,所以我们可以看着关键源码分析,并看看能不能将bug修复。
1 | ObjectStream::ObjectStream(XRef *xref, int objStrNumA) { |
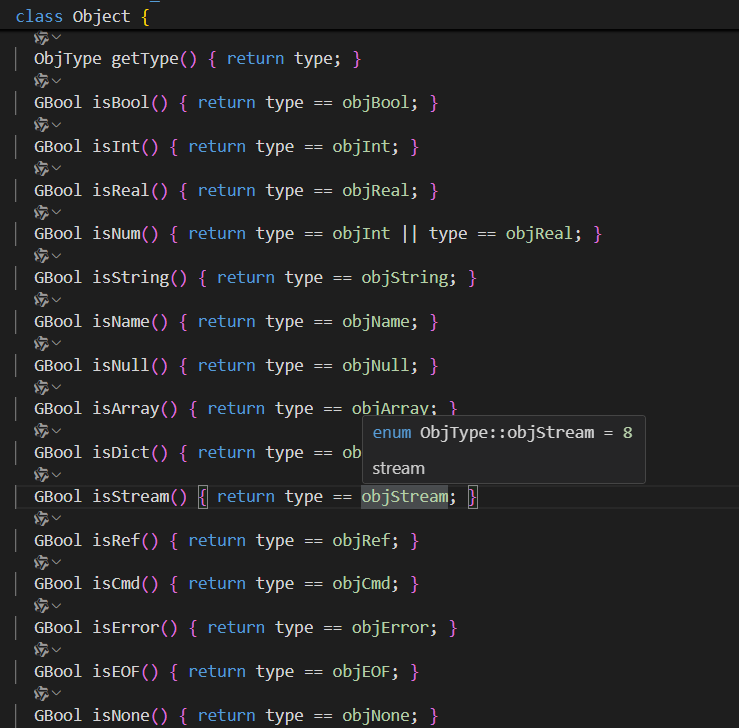
其中Object类的一些类型的判断是通过type字段实现的。当
Type 为 ObjStream 时,表示该对象是
对象流(Object Stream)。对象流是 PDF 1.5
引入的一种优化机制,目的是减少 PDF 文档的大小和提高解析效率。
对象流的主要特征:
- 存储压缩对象:对象流用于存储多个 PDF 对象(通常是小型的、非结构化的 PDF 对象,如字典和数组)。
- 被压缩存储:通常使用 FlateDecode(基于 zlib 的压缩算法)进行压缩。
- 非直接引用:被包含在对象流中的对象不会在 xref
表中单独列出,而是由
ObjStm统一管理。
pdf结构介绍
这里我们可以先了解一下pdf的文件结构,以前面的helloworld.pdf为例:
1 | %PDF-1.7 |
1. 头部(Header)
1 | %PDF-1.7 |
PDF-1.7:表明该 PDF 使用 PDF 1.7 版本 规范。- 注意:有些 PDF 在此之后会加上一行二进制数据,以避免文本编辑器错误处理 PDF。
2. 对象(Body)
2.1 根目录对象 (Catalog)
1 | 1 0 obj % entry point |
- 对象 ID:
1 0 obj /Type /Catalog:表明这是 PDF 的 根目录对象(Catalog)。/Pages 2 0 R:指向 页面树对象2 0 obj,用于管理 PDF 页面。
2.2 页面树对象 (Pages)
1 | 2 0 obj |
- 对象 ID:
2 0 obj /Type /Pages:标明它是 页面集合,用于管理 PDF 页面。/MediaBox [ 0 0 200 200 ]:- 定义 页面大小(单位:PostScript Points,1pt ≈ 1/72 英寸)。
(0,0)是左下角,(200,200)是右上角。
/Count 1:表示这个 PDF 只有 1 页。/Kids [ 3 0 R ]:- 该数组存储了 PDF 页面对象的引用,这里只有
3 0 obj(即唯一的页面)。
- 该数组存储了 PDF 页面对象的引用,这里只有
2.3 页面对象 (Page)
1 | 3 0 obj |
- 对象 ID:
3 0 obj /Type /Page:标明它是 页面对象。/Parent 2 0 R:指向 父级Pages对象2 0 obj。/Resources:- 存储该页面的资源信息(如字体、图片等)。
/Font << /F1 4 0 R >>:- 定义了字体资源,
F1代表该页面的 字体名称,实际引用4 0 obj(字体对象)。
- 定义了字体资源,
/Contents 5 0 R:- 指向
页面内容流(
5 0 obj),用于绘制文本或图形。
- 指向
页面内容流(
2.4 字体对象 (Font)
1 | 4 0 obj |
- 对象 ID:
4 0 obj /Type /Font:表明该对象是 字体对象。/Subtype /Type1:PDF 1.0 时代的 Type1 字体,用于打印设备。/BaseFont /Times-Roman:- 指定 Times-Roman 字体(标准 14 种字体之一)。
- 由于 标准字体内置在 PDF 查看器中,所以 PDF 不需要嵌入该字体。
2.5 页面内容 (Contents)
1 | 5 0 obj % page content |
- 对象 ID:
5 0 obj /Length 44:- 流的长度为 44 字节(实际计算时可能不包括换行符)。
stream ... endstream:- 包含绘制指令,PDF 使用 PostScript 类似的 页面描述语言。
- 解释
stream指令:BT:开始文本模式 (Begin Text)。70 50 TD:- 移动文本位置(
70,50)。 TD(Text Move):移动到(70, 50)位置(相对于左下角)。
- 移动文本位置(
/F1 12 Tf:- 设置字体
F1(即4 0 obj的Times-Roman)。 - 字体大小
12pt。
- 设置字体
(Hello, world!) Tj:- 绘制字符串
Hello, world!。
- 绘制字符串
ET:结束文本模式 (End Text)。
3. 交叉引用表(xref)
1 | xref |
xref表示交叉引用表的开始。0 6:- 表示
xref表含有 6 个对象(编号0到5)。
- 表示
每行解释:
1
2
3
4
5
60000000000 65535 f % 0 号对象(特殊空闲对象)
0000000010 00000 n % 1 号对象在文件的第 10 字节
0000000079 00000 n % 2 号对象在文件的第 79 字节
0000000173 00000 n % 3 号对象在文件的第 173 字节
0000000301 00000 n % 4 号对象在文件的第 301 字节
0000000380 00000 n % 5 号对象在文件的第 380 字节n表示 该对象已使用。f表示 该对象已被删除或未使用(0号对象)。
4. Trailer(尾部信息)
1 | trailer |
/Size 6:- PDF 文件一共 包含 6 个对象(编号
0到5)。
- PDF 文件一共 包含 6 个对象(编号
/Root 1 0 R:- PDF 根目录对象是
1 0 obj(即Catalog)。
- PDF 根目录对象是
5. 文件结尾
1 | startxref |
startxref 492:- 交叉引用表 (
xref) 在 文件偏移量 492 处。
- 交叉引用表 (
%%EOF:- PDF 文件的结束标志。
代码分析
1 | // XRef::fetch |
当 xref 表项是 压缩对象流
(xrefEntryCompressed) 时,它会:
- 创建一个新的 ObjectStream
- 调用 ObjectStream::getObject 来获取具体的对象
1 | // ObjectStream::ObjectStream |
当 ObjectStream::ObjectStream 试图加载
objStrNum 时,它会调用 xref->fetch
来获取对应的对象,而这个 fetch 可能会继续触发
ObjectStream::ObjectStream,导致无限递归。
漏洞根因
- 当 PDF 文件中的交叉引用表 (xref) 让某个对象指向
另一个压缩对象流,但该压缩对象流本身也存储在另一个压缩对象流内,这样
fetch和ObjectStream之间会无限调用,最终导致 栈溢出 (stack overflow)。 - 这个错误通常发生在 循环引用 (circular reference) 或 递归解压 (recursive decompression) 时。
漏洞修复
需要修复的源码位于xpdf/XRef.cc中。我们可以用 哈希表 (std::unordered_set) 记录访问过的对象,避免重复解析。为了保留原始版本这里我们再解压一边xpdf-3.02,并将其命名为fixed-xpdf-3.02。
1 |
|
然后再次编译,把二进制文件输出到fixed/bin目录下。
1 | cd fixed-xpdf-3.02 |
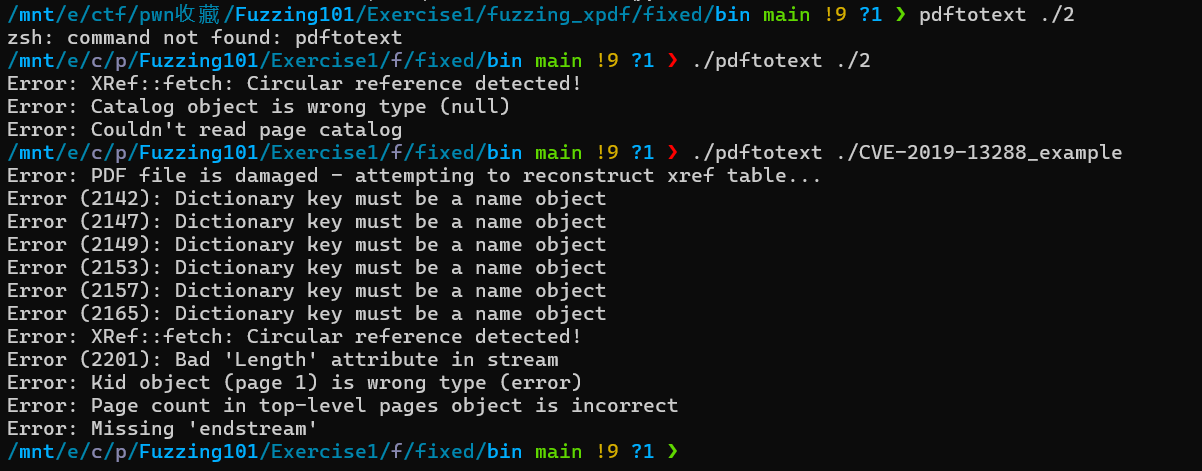
之后用修复好编译后的pdftotext用之前触发crash的样本进行测试,此时就会输出Circular reference detected!而不是直接seg fault,这里的2就是前面fuzz出的id为2的样本,只是改了个名,然后也用github仓库中对应给的solution进行了验证,也是成功的进行了修复。
- 标题: 复杂程序fuzz初探
- 作者: collectcrop
- 创建于 : 2025-04-01 14:27:10
- 更新于 : 2025-04-01 14:27:10
- 链接: https://collectcrop.github.io/2025/04/01/复杂程序fuzz初探/
- 版权声明: 本文章采用 CC BY-NC-SA 4.0 进行许可。
