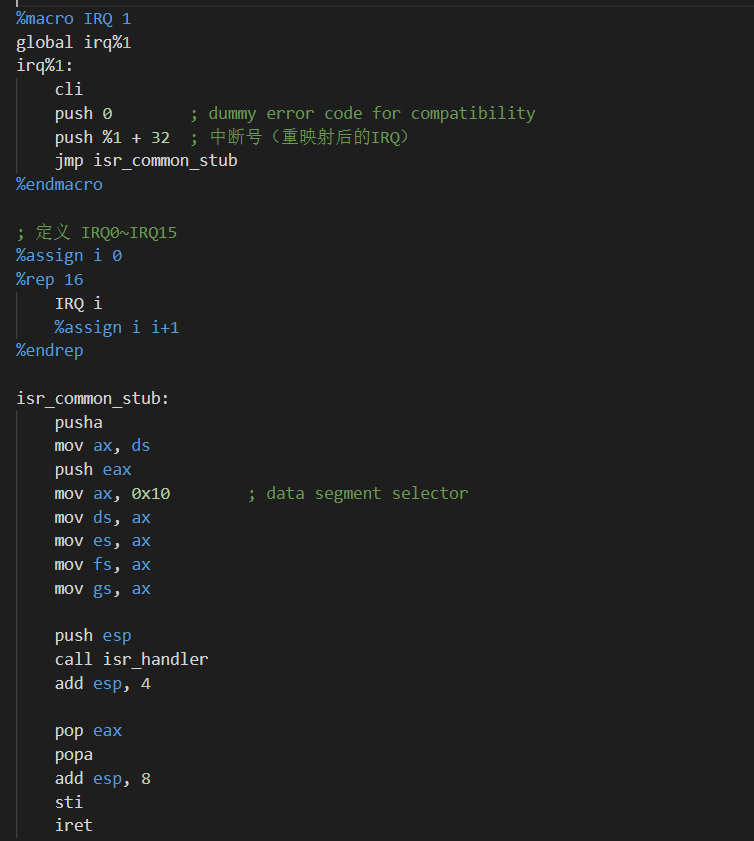
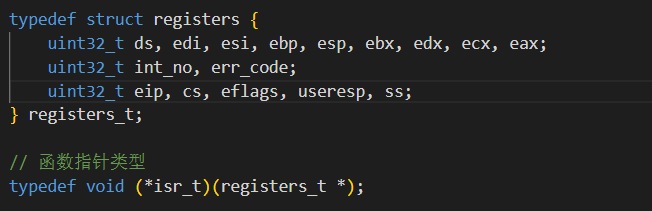
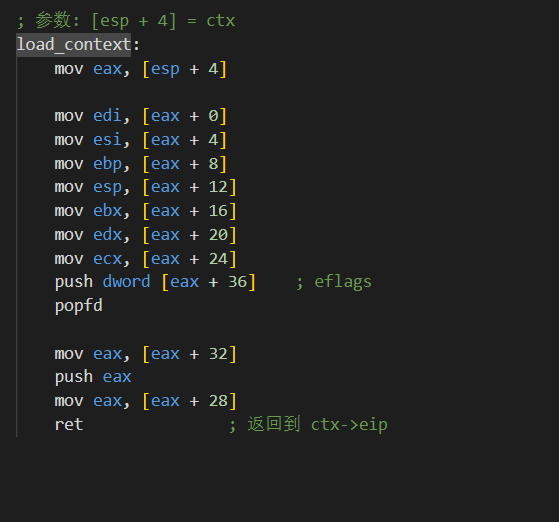
在进行实现进程和线程的实现之前,我们先处理几个之前遗留下来的问题。
分页后跳转处理
之前的实现中遗留了一个问题,就是我们开启分页后执行流还是在物理地址的恒等映射的前4MB上的,并没有切换到高虚拟地址处执行。这里我们先实现一下一开启分页就跳转到对应地址。这里我选择的是重新布局kernel.c,并将入口设置为kernel_init函数,从而一加载kernel就初始化堆管理并开启分页,之后我们vmm_init里就可以借助kernel_main函数的地址进行跳转了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| void kernel_init(void) {
pmm_init(MEMORY_MAP_ADDR);
vmm_init();
}
void kernel_main(void){
clear_screen();
idt_install();
irq_remap();
isr_install();
irq_install();
kheap_init();
asm volatile("sti");
while (1) {
asm volatile("hlt");
}
}
|
vmm.c的更改如下,主要加了一个跳转:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| extern void kernel_main();
void vmm_init() {
kernel_page_directory = (page_table_t*)pmm_alloc_page();
if (kernel_page_directory == 0) {
kernel_printf("vmm_init: failed to allocate page directory\n");
return;
}
memset(kernel_page_directory, 0, PAGE_SIZE);
page_table_t* identity_pt = (page_table_t*)pmm_alloc_page();
memset(identity_pt, 0, PAGE_SIZE);
for (uint32_t i = 0; i < PAGE_ENTRIES; i++) {
identity_pt->entries[i] = (i * PAGE_SIZE) | PAGE_FLAGS;
}
kernel_page_directory->entries[0] = ((uint32_t)identity_pt) | PAGE_FLAGS;
kernel_page_directory->entries[768] = ((uint32_t)identity_pt) | PAGE_FLAGS;
enable_paging(kernel_page_directory);
asm volatile("jmp *%0" :: "r"(kernel_main+0xC0000000));
}
|
之后把ld的入口函数改一下即可,这里需要注意的是,我们这样设置后,当我们跳转到虚拟地址执行时,会丢失掉调试符号。我们可以手动在gdb里add-symbol-file重新加载一下kernel.elf到地址0xc0100000处。
栈设置
我们一开始是在bootloader阶段设置好了esp的值为某一个物理地址,那么当我们启用分页后,理应尽可能少的利用前4MB的恒等映射,而是将其切换到别的虚拟地址处。
我们需要把栈设置到某个虚拟地址处,由于是函数调用,切换栈后会丢失原来的返回地址信息,所以需要事先把返回地址存到某个寄存器中然后最后跳转回去。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| #define KERNEL_STACK_SIZE 4096
#define KERNEL_BASE 0xC0100000
void kernel_main(void){
switch_to_kernel_stack();
clear_screen();
idt_install();
irq_remap();
isr_install();
irq_install();
kheap_init();
asm volatile("sti");
while (1) {
asm volatile("hlt");
}
}
void switch_to_kernel_stack() {
uintptr_t stack_top = (uintptr_t)kernel_stack + KERNEL_STACK_SIZE + KERNEL_BASE;
uintptr_t return_addr;
asm volatile (
"mov 4(%%ebp), %0\n"
: "=r"(return_addr)
);
asm volatile (
"mov %0, %%esp\n"
"mov %0, %%ebp\n"
"jmp *%1\n"
:
: "r"(stack_top), "r"(return_addr)
);
}
|
内核线程实现
多线程执行实现
这里我们先实现一个最简单的内核线程控制,调度策略是顺序调度,每个线程分得相同的时间片。
首先可以设计一下管理线程的结构体,这里一开始主要只用到4个字段,stack主要用来存内核线程的栈指针,后续我们会为每个新建的线程用内核堆管理器分配1页内存作为stack;state是我们的线程状态,参考一些现有的操作系统这里分成了4种,方便后续调度器使用;time_slice是每个线程的时间片,后续就是在线程耗尽其拥有的时间片后进行顺序调度;next是一个链表的指针域,方便后续使用循环链表进行逐个线程依次调度。其中由于每个线程在触发调度切换时,需要保存当前线程的context(也就是所有寄存器状态),而被调度的新的线程需要从中加载自己之前的context,所以我们还需要知道context结构体的地址。这里我们可以直接把context存到栈底,节省空间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
#ifndef THREAD_H
#define THREAD_H
#include "stdint.h"
#define MAX_THREADS 4
#define KERNEL_STACK_SIZE 4096
typedef enum{
THREAD_READY,
THREAD_RUNNING,
THREAD_BLOCKED,
THREAD_EXITED,
} thread_state_t;
typedef struct thread_context {
uint32_t edi, esi, ebp, esp, ebx, edx, ecx, eax;
uint32_t eip;
uint32_t eflags;
} thread_context_t;
typedef struct thread {
uint8_t* stack;
thread_state_t state;
int time_slice;
struct thread* next;
} thread_t;
static inline thread_context_t* thread_get_context(thread_t* t) {
return (thread_context_t*)(t->stack + KERNEL_STACK_SIZE - sizeof(thread_context_t));
}
void thread_init();
int thread_create(void (*entry)(void));
#endif
|
创建线程的函数需要传入一个函数指针作为线程入口,这里我们维护了一个线程数组来管理线程,新线程的创立会从这个数组中找state为THREAD_EXITED的线程进行占用,并初始化context的eip,esp等字段。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#include "thread.h"
#include "heap.h"
#include "scheduler.h"
static thread_t threads[MAX_THREADS];
void thread_init() {
for (int i = 0; i < MAX_THREADS; i++){
threads[i].state = THREAD_EXITED;
}
scheduler_init();
}
int thread_create(void (*entry)(void)){
for (int i = 0; i < MAX_THREADS; i++){
thread_t *t = &threads[i];
if (t->state == THREAD_EXITED) {
t->stack = (uint8_t *)kmalloc(KERNEL_STACK_SIZE);
scheduler_add(t);
uint32_t *stack_top = t->stack + KERNEL_STACK_SIZE;
thread_context_t *ctx = thread_get_context(t);
ctx->eip = (uint32_t) entry;
ctx->eflags = 0x202;
ctx->esp = (uint32_t) stack_top - sizeof(thread_context_t);
return i;
}
}
return -1;
}
|
然后是调度器的实现,scheduler_add主要是往就绪循环链表中添加一个新的线程,schedule核心调度逻辑就是将正在执行的线程状态设置为就绪(READY),保存其此时的context,然后读取新的被调度的线程的context,将状态设置为RUNNING并切换过去执行。
save_context的实现主要依赖于之前实现的isr的通用入口保存的寄存器状态,我们的线程被时钟中断打断时,就会直接跳转到对应注册好的irq入口执行,硬件会自动将一些关键寄存器保存push入栈(比如关键的eip),然后我们还会手动push中断号以及错误码入栈。这里除了esp保存的并不直接是前一个线程执行的esp以外,其它寄存器状态都完全是前一个线程的context。而esp相对于真实值的偏移也是固定的,因为前面多push的值的数量是确定的,我们恢复esp时需要手动加上偏移来适配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #ifndef SCHEDULER_H
#define SCHEDULER_H
#include "thread.h"
#include "heap.h"
#define DEFAULT_SLICE 5
static thread_t* current_thread = NULL;
static thread_t* ready_queue = NULL;
void scheduler_init();
void scheduler_add(thread_t* thread);
void schedule();
#endif
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
|
#include "thread.h"
#include "scheduler.h"
#include "isr.h"
void scheduler_init() {
ready_queue = NULL;
current_thread = NULL;
}
void scheduler_add(thread_t* thread) {
thread->state = THREAD_READY;
thread->time_slice = DEFAULT_SLICE;
if (!ready_queue) {
ready_queue = thread;
thread->next = thread;
} else {
thread_t* temp = ready_queue;
while (temp->next != ready_queue)
temp = temp->next;
temp->next = thread;
thread->next = ready_queue;
}
}
extern void load_context(thread_context_t* ctx);
void schedule(registers_t* r) {
thread_t* prev = current_thread;
if (!current_thread) {
current_thread = ready_queue;
} else {
current_thread->state = THREAD_READY;
current_thread = current_thread->next;
}
current_thread->state = THREAD_RUNNING;
current_thread->time_slice = DEFAULT_SLICE;
if (prev)
save_context(thread_get_context(prev),r);
load_context(thread_get_context(current_thread));
}
void save_context(thread_context_t* ctx, registers_t* r) {
ctx->edi = r->edi;
ctx->esi = r->esi;
ctx->ebp = r->ebp;
ctx->esp = (r->esp+0x14);
ctx->ebx = r->ebx;
ctx->edx = r->edx;
ctx->ecx = r->ecx;
ctx->eax = r->eax;
ctx->eip = r->eip;
ctx->eflags = r->eflags;
}
|

其中load_context由汇编实现,这里我们需要利用一个通用寄存器(这里选用的是eax),先设置好其它寄存器的值,尤其是把目标跳转的eip需要push入栈,最后再还原eax的值。这里比较巧妙的是esp的还原,因为我们后续需要利用栈来存eflags和eip,所以不可避免的会修改esp的值并往较低地址处写入内容,那这是否会有一种情况我们push的值会破坏掉线程后面需要利用到的值呢?事实上正常函数执行时,其局部变量地址都是高于esp的,所以我们的push并不会影响线程的执行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| ; thread_switch.asm
global load_context
; 参数: [esp + 4] = ctx
load_context:
mov eax, [esp + 4]
mov edi, [eax + 0]
mov esi, [eax + 4]
mov ebp, [eax + 8]
mov esp, [eax + 12]
mov ebx, [eax + 16]
mov edx, [eax + 20]
mov ecx, [eax + 24]
push dword [eax + 36] ; eflags
popfd
mov eax, [eax + 32]
push eax
mov eax, [eax + 28]
ret ; 返回到 ctx->eip
|
最后加入两个线程执行看看结果,发现可以正常交错打印字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| void kernel_main(void){
switch_to_kernel_stack();
clear_screen();
idt_install();
irq_remap();
isr_install();
irq_install();
kheap_init();
thread_init();
thread_create(thread_a);
thread_create(thread_b);
asm volatile("sti");
while (1) {
asm volatile("hlt");
}
}
void thread_a() {
while (1) {
kernel_printf("A");
for (int i = 0; i < 1000000; i++);
}
}
void thread_b() {
while (1) {
kernel_printf("B");
for (int i = 0; i < 1000000; i++);
}
}
|
增加线程返回处理
上述线程是在死循环中执行的,所以没什么问题,但是肯定不是所有的线程都是会一直持续下去。我们之前进入线程一直都是在load_context里面直接根据context进行跳转。但如果执行到了一个线程的ret,那么会直接返回到一个非法的地址崩溃。所以我们需要为线程的结束设置一个处理函数。
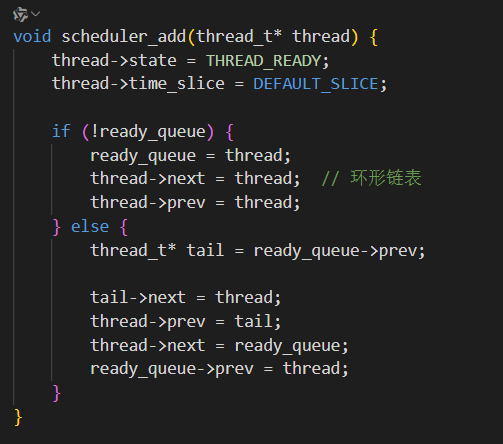
由于线程退出我们需要回收线程栈所占的内存以及将退出的线程从调度就绪列表中移除,一开始我们是维护了一个next指针域来实现一个循环链表,但这样在链表中移除某个线程时会比较麻烦,所以我就加了一个prev域来维护一个双向循环链表。
然后遇到的问题是,我们如何让我们的thread在退出时不会直接崩溃,而是回来调用thread_exit进行统一处理。这里其实我们可以往外套一层thread_start来进行包装整个线程执行,其接受线程入口函数指针作为参数,然后thread_start在执行完线程函数后会调用thread_exit,这样就能让线程正常退出了。我们所需要微调的就是一开始创建线程时的context赋值,这里我们需要把eip设置为thread_start入口,然后手动将参数写入栈中。之前定位esp是通过栈底地址减去context结构体大小得到的,这里由于需要腾出存func参数的空间,所以干脆直接指定栈底到实际可用栈底的偏移STACK_OFFSET,预留一部分空间在中间。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #define STACK_OFFSET 0x40
int thread_create(void (*entry)(void)){
for (int i = 0; i < MAX_THREADS; i++){
thread_t *t = &threads[i];
if (t->state == THREAD_EXITED) {
t->stack = (uint8_t *)kmalloc(KERNEL_STACK_SIZE);
scheduler_add(t);
uint32_t *stack_top = t->stack + KERNEL_STACK_SIZE;
thread_context_t *ctx = thread_get_context(t);
ctx->eip = (uint32_t) thread_start;
ctx->eflags = 0x202;
ctx->esp = (uint32_t) stack_top - STACK_OFFSET;
((uint32_t*)(ctx->esp))[1] = (uint32_t)entry;
return i;
}
}
return -1;
}
void thread_start(void (*func)(void)) {
func();
thread_exit();
}
|
然后就是实现具体的退出函数,主要就是把线程的状态修改为退出,并把对应线程从调度链表中删除,最后回收线程栈。这里需要注意一开始要把中断关掉,避免在退出或调度时又有新的中断打断执行导致无法预期的情况发生,最后可以在load_context中ret到对应线程执行地址前再打开中断。
后面的schedule函数逻辑也需要进行微调,因为退出的线程调用schedule时实际上不需要保存对应寄存器状态,直接切换即可。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
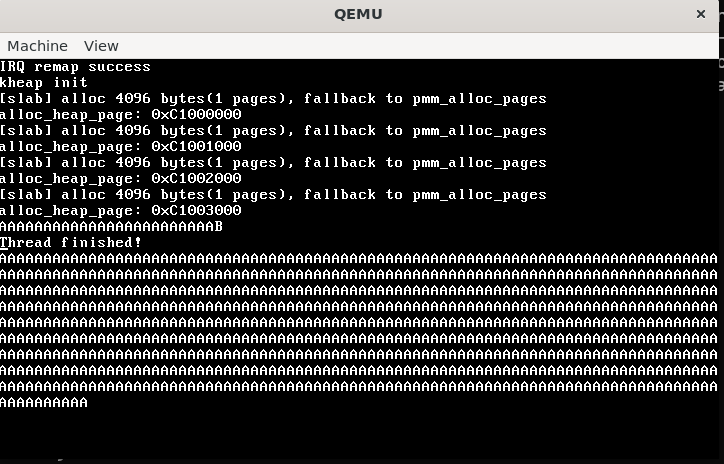
| void thread_exit() {
asm ("cli");
kernel_printf("\nThread finished!\n");
current_thread->state = THREAD_EXITED;
thread_remove(current_thread);
kfree(current_thread->stack);
schedule(NULL);
while (1);
}
void thread_remove(thread_t* thread) {
if (!thread || !ready_queue) return;
if (thread->next == thread) {
ready_queue = NULL;
} else {
thread->prev->next = thread->next;
thread->next->prev = thread->prev;
}
}
void schedule(registers_t* r) {
asm ("cli");
thread_t* prev = current_thread;
if (!current_thread) {
current_thread = ready_queue;
} else {
if (current_thread->state == THREAD_RUNNING){
current_thread->state = THREAD_READY;
current_thread = current_thread->next;
}
else if(current_thread->state == THREAD_EXITED){
current_thread = current_thread->next;
prev->next = NULL;
prev->prev = NULL;
}
}
current_thread->state = THREAD_RUNNING;
current_thread->time_slice = DEFAULT_SLICE;
if (prev&&prev->state!=THREAD_EXITED)
save_context(thread_get_context(prev),r);
load_context(thread_get_context(current_thread));
}
|