这里借鉴slab/slub分配器的思想,往最简单实现一个内核堆分配器。之前我们已经用buddy
system实现了物理内存分配器(PMM),也开启分页机制,可以利用虚拟地址。因为PMM分配内存是以页(4KB,0x1000)为粒度的,如果申请一小块结构体的内存就需要申请一整页的内存就过于浪费,所以slab分配器的核心功能是分配远小于一页大小的内存。
主体分配逻辑
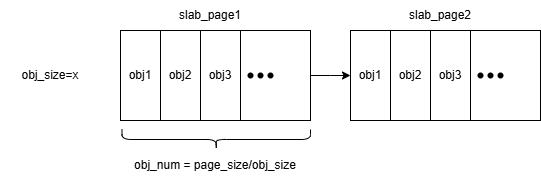
从PMM中申请到的一页内存可以内部划分成多个指定大小的内存块,这样的一页内存这里我称为是slab_page,而slab_page中的多个可划分内存块我称为是slab_obj。其中管理同一大小的slab_page用一个链表串联起来。一个slab_page内部可以采用bitmap或是freelist来管理其内部的内存块。用freelist管理的好处是可以快速进行分配,避免了使用bitmap时顺序查找第一个空闲块的过程,而且freelist管理时头部插入也比较方便,最近释放的块可以最先被分配出来,这样就可以提高TLB命中率和CPU
Cache 命中率,性能上表现也比较好。

然后我们可以设计三种缓存状态(full、partial、empty)的链表来分别管理全部分配满,部分分配以及全部未分配的slab_page,这样子做有很多好处。比如当我们分配完一个chunk,发现当前的slab_page已经全部占满(即freelist为空),则可以直接放到full链表中,full链表里的slab_page不参与未来分配,因为该页已经没有可分配对象,所以分配器跳过这类页,减少遍历时间。而empty链表则暂时存着全空的slab_page,而不是直接将物理内存释放的好处是快速复用,不需要重新申请页就可以重新初始化使用,省去了向物理内存申请页的成本。在极端情况下,我们申请一个堆块释放一个堆块,由于每次释放后freelist都为全空,如果不进行暂存的话,每次申请和释放就都需要调用PMM的接口来频繁申请/释放内存。将empty链表里的内存归还给物理内存的时机很有讲究,一般shrink的时机都是当empty链表存的slab_page超过了某个阈值时再进行全部释放。这里的三个链表我们用一个cache结构体来进行管理,一个cache负责一个固定大小的内存分配。
我们申请某个大小小于一页的内存,可以先判断大于请求大小的最小size的cache的partial是否为空,不空则可以直接从partial的freelist中直接取一个slab_obj作为分配的堆内存;否则尝试从empty链表取一个slab_page重新放回partial中;如果前两个尝试都失败了,最后就会调用PMM的接口去申请一段物理内存并手动建立好页表映射,加入到partial表中。最后就可以分配到堆内存。
这里我们发现实际上还需要申请物理内存并建立页表映射,物理内存分配的细节我们可以不关注(全交给pmm),但我们需要映射到的虚拟地址需要我们进行设计。这里我直接采用线性的方式来得到映射的虚拟地址,也就是说即使释放了某段虚拟地址对应的物理地址并接触了页表映射,这个用过的虚拟地址也不会再进行使用,分配的虚拟地址不断往高虚拟地址处增长。可以这样做的原因在于我们实际可用的虚拟地址较大,而且也不会浪费到实际的物理内存,在我们目前开发的初期可以不用实现繁琐的虚拟地址分配管理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| typedef struct slab_page {
struct slab_page_t *next;
uint32_t vaddr;
struct slab_object_t *freelist;
uint32_t used_count;
struct slab_cache *owner_cache;
uint8_t bitmap[16];
struct slab_page_t *next_hash;
} slab_page_t;
typedef struct slab_cache {
size_t object_size;
slab_page_t *partial;
slab_page_t *full;
slab_page_t *empty;
size_t empty_count;
} slab_cache_t;
typedef struct slab_object {
struct slab_object *next;
} slab_object_t;
|
动态 slab_page
元数据管理设计
实际上我们还需要一片区域来存slab_page的这个结构体,一种可行的方案是让在初始化free_list时就保留前面结构体大小的空间,后面的空间再用来存对应的内存分配对象obj,再相应调整bitmap的寻址逻辑即可。但这种设计会减少每个slab_page能够管理的obj数量,极端情况下,比如2048大小的块管理,由于1页空间为4096,本来一个slab_page可以管2个obj,如果预留了slab_page结构体的空间,那么就只能存下1个obj,那么我们可以单独为存这个
slab_page
结构体设计一个申请释放逻辑。这里我们的slab_page结构体的内存实际上作为slab_obj进行管理,slab_page_meta_chunk可以存很多个slab_page,同样也是用链表的分配逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
| #define SLAB_PAGE_META_PER_PAGE (4096 / sizeof(slab_page_t))
typedef struct slab_page_meta_chunk {
struct slab_page_meta_chunk *next;
slab_page_t entries[SLAB_PAGE_META_PER_PAGE];
} slab_page_meta_chunk_t;
static slab_page_meta_chunk_t *meta_chunk_list = NULL;
static slab_page_t *meta_free_list = NULL;
static slab_page_t *slab_page_map[SLAB_PAGE_HASH_SIZE];
static inline size_t slab_page_hash(uintptr_t vaddr) {
return (vaddr >> 12) % SLAB_PAGE_HASH_SIZE;
}
void remove_slab_page_from_hash(slab_page_t *page){
size_t index = slab_page_hash((uintptr_t)page->vaddr);
slab_page_t **cur = &slab_page_map[index];
while (*cur) {
if (*cur == page) {
*cur = page->next_hash;
break;
}
cur = &(*cur)->next_hash;
}
}
void _alloc_slab_page_meta() {
void *vaddr = alloc_heap_page();
slab_page_meta_chunk_t *chunk = (slab_page_meta_chunk_t *)vaddr;
chunk->next = meta_chunk_list;
meta_chunk_list = chunk;
for (int i = SLAB_PAGE_META_PER_PAGE - 1; i >= 0; i--) {
slab_page_t *page = &chunk->entries[i];
((slab_object_t *)page)->next = meta_free_list;
meta_free_list = (slab_object_t *)page;
}
}
slab_page_t *alloc_slab_page_meta() {
if (!meta_free_list) {
_alloc_slab_page_meta();
if (!meta_free_list) return NULL;
}
slab_page_t *page = (slab_page_t *)meta_free_list;
meta_free_list = meta_free_list->next;
memset(page, 0, sizeof(slab_page_t));
return page;
}
void free_slab_page_meta(slab_page_t *page) {
((slab_object_t *)page)->next = meta_free_list;
meta_free_list = (slab_object_t *)page;
}
|
由于我们之后实现slab_free时,需要通过一个slab_obj的地址来反过来查出所属的slab_page,而我们的slab_page结构体存的位置和其obj的位置是分离的。所以我们需要维护一个hash
table,从而可以从obj所在的虚拟地址页高效查出对应slab_page。这里我们还需要解决hash冲突的问题,所以在前面的slab_page中定义了一个next_hash的字段来管理一个链表,从而在hash冲突时可以通过遍历这个链表来找到对应slab_page。
基本实现
其中我保留了bitmap在slab_page结构体中,主要是为了可以方便判断是否存在double
free,也可以快速定位到某页内存中哪些空间已经被分配利用。
其中向PMM申请内存并进行页表映射操作都被封装进了alloc_heap_page()这个函数中,分配堆内存时只有在对应管理结构的链表的freelist全为空时才会用这个接口去申请物理内存,而且虚拟堆地址的增长也是在这个函数里完成的。
最后我还实现了一个dump_slab_cache_partial_freelist接口来用于打印partial的freelist从而进行调试。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
|
#pragma once
#include <stdint.h>
#include "heap.h"
#define HEAP_BASE 0xC1000000
#define HEAP_MAX_SIZE 0x01000000
#define PAGE_SIZE 4096
#define SLAB_MIN_SIZE 16
#define SLAB_MAX_SIZE 2048
#define SLAB_STEP 16
#define NUM_SLAB_CLASSES ((SLAB_MAX_SIZE / SLAB_STEP) + 1)
#define SLAB_PAGE_META_PER_PAGE (4096 / sizeof(slab_page_t))
#define MAX_EMPTY_PAGES 8
#define SLAB_PAGE_HASH_SIZE 4096
typedef struct slab_page {
struct slab_page_t *next;
uint32_t vaddr;
struct slab_object_t *freelist;
uint32_t used_count;
struct slab_cache *owner_cache;
uint8_t bitmap[16];
struct slab_page_t *next_hash;
} slab_page_t;
typedef struct slab_cache {
size_t object_size;
slab_page_t *partial;
slab_page_t *full;
slab_page_t *empty;
size_t empty_count;
} slab_cache_t;
typedef struct slab_object {
struct slab_object *next;
} slab_object_t;
typedef struct slab_page_meta_chunk {
struct slab_page_meta_chunk *next;
slab_page_t entries[SLAB_PAGE_META_PER_PAGE];
} slab_page_meta_chunk_t;
void slab_init();
void* slab_alloc(size_t size);
void slab_free(void * ptr);
void init_freelist(slab_page_t *page, size_t object_size);
void add_to_list(slab_page_t **list, slab_page_t *page);
void remove_from_list(slab_page_t **list, slab_page_t *page);
static uint32_t alloc_heap_page(void);
slab_page_t* get_slab_page(void *vaddr);
void dump_slab_cache_partial_freelist(size_t size);
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
|
#include "slab.h"
#include "pmm.h"
#include "vmm.h"
#include "printf.h"
#include "common.h"
#include "string.h"
static slab_cache_t slab_caches[NUM_SLAB_CLASSES];
static uint32_t heap_next_free = HEAP_BASE;
static slab_page_meta_chunk_t *meta_chunk_list = NULL;
static slab_page_t *meta_free_list = NULL;
static slab_page_t *slab_page_map[SLAB_PAGE_HASH_SIZE];
static inline size_t slab_page_hash(uintptr_t vaddr) {
return (vaddr >> 12) % SLAB_PAGE_HASH_SIZE;
}
void remove_slab_page_from_hash(slab_page_t *page){
size_t index = slab_page_hash((uintptr_t)page->vaddr);
slab_page_t **cur = &slab_page_map[index];
while (*cur) {
if (*cur == page) {
*cur = page->next_hash;
break;
}
cur = &(*cur)->next_hash;
}
}
void _alloc_slab_page_meta() {
void *vaddr = alloc_heap_page();
slab_page_meta_chunk_t *chunk = (slab_page_meta_chunk_t *)vaddr;
chunk->next = meta_chunk_list;
meta_chunk_list = chunk;
for (int i = SLAB_PAGE_META_PER_PAGE - 1; i >= 0; i--) {
slab_page_t *page = &chunk->entries[i];
((slab_object_t *)page)->next = meta_free_list;
meta_free_list = (slab_object_t *)page;
}
}
slab_page_t *alloc_slab_page_meta() {
if (!meta_free_list) {
_alloc_slab_page_meta();
if (!meta_free_list) return NULL;
}
slab_page_t *page = (slab_page_t *)meta_free_list;
meta_free_list = meta_free_list->next;
memset(page, 0, sizeof(slab_page_t));
return page;
}
void free_slab_page_meta(slab_page_t *page) {
((slab_object_t *)page)->next = meta_free_list;
meta_free_list = (slab_object_t *)page;
}
static inline int slab_index(size_t size) {
if (size > SLAB_MAX_SIZE) return -1;
int idx = (size - 1) / SLAB_STEP;
return idx;
}
static uint32_t alloc_heap_page() {
if (heap_next_free >= HEAP_BASE + HEAP_MAX_SIZE) return 0;
uint32_t vaddr = heap_next_free;
heap_next_free += PAGE_SIZE;
uint32_t phys = pmm_alloc_page();
if (!phys) return 0;
map_page(vaddr, phys, PAGE_RW|PAGE_PRESENT);
if (DEBUG) kernel_printf("alloc_heap_page: %x\n", vaddr);
return vaddr;
}
void free_heap_page(slab_page_t *page){
unmap_page(page->vaddr);
free_slab_page_meta(page);
remove_slab_page_from_hash(page);
}
void slab_init(){
for (int i = 0; i < NUM_SLAB_CLASSES; i++) {
slab_caches[i].object_size = SLAB_MIN_SIZE + i * SLAB_STEP;
slab_caches[i].partial = NULL;
slab_caches[i].full = NULL;
slab_caches[i].empty = NULL;
slab_caches[i].empty_count = 0;
}
}
void *slab_alloc(size_t size) {
slab_page_t *page = NULL;
if (size == 0) return NULL;
int idx = slab_index(size);
if (idx < 0 || idx >= NUM_SLAB_CLASSES) {
uint32_t pages = (size + PAGE_SIZE - 1) / PAGE_SIZE;
void *ptr = (void *)heap_next_free;
for (uint32_t i = 0; i < pages; i++) alloc_heap_page();
return ptr;
}
slab_cache_t *cache = &slab_caches[idx];
size_t objs_per_page = PAGE_SIZE / cache->object_size;
size_t obj_size = cache->object_size;
if (cache->partial) {
page = cache->partial;
}
else if (cache->empty) {
page = cache->empty;
cache->empty = page->next;
page->next = NULL;
cache->empty_count--;
init_freelist(page, cache->object_size);
page->used_count = 0;
add_to_list(&cache->partial, page);
}
else {
page = alloc_slab_page_meta();
if (!page) return NULL;
uint32_t vaddr = alloc_heap_page();
if (!vaddr) return NULL;
page->vaddr = vaddr;
page->used_count = 0;
page->owner_cache = cache;
memset(page->bitmap, 0, sizeof(page->bitmap));
init_freelist(page, cache->object_size);
size_t index = slab_page_hash((uintptr_t)vaddr);
page->next_hash = slab_page_map[index];
slab_page_map[index] = page;
add_to_list(&cache->partial, page);
}
slab_object_t *obj = page->freelist;
if (!obj) return NULL;
uint32_t offset = (uint32_t)obj - page->vaddr;
size_t index = offset / obj_size;
uint8_t bit_offset = index % 8;
page->bitmap[index/8] |= (1 << bit_offset);
page->freelist = obj->next;
page->used_count++;
memset(obj, 0, obj_size);
if (page->used_count == objs_per_page) {
remove_from_list(&cache->partial, page);
add_to_list(&cache->full, page);
}
if (DEBUG) kernel_printf("slab alloc: %x, size:%d\n", obj, obj_size);
return (void *)obj;
}
void slab_free(void *ptr) {
if (!ptr) return;
uint32_t vaddr = (uint32_t)ptr;
slab_page_t *page = get_slab_page(vaddr);
if (!page || !page->owner_cache) return;
slab_cache_t *cache = page->owner_cache;
size_t obj_size = cache->object_size;
size_t objs_per_page = PAGE_SIZE / obj_size;
uint32_t offset = vaddr - page->vaddr;
if (offset % obj_size != 0 || offset >= PAGE_SIZE) return;
size_t index = offset / obj_size;
size_t byte_index = index / 8;
size_t bit_offset = index % 8;
if (((page->bitmap[byte_index] >> bit_offset) & 1) == 0) {
kernel_printf("double free detected!\n");
return;
}
page->bitmap[byte_index] &= ~(1 << bit_offset);
((slab_object_t *)ptr)->next = page->freelist;
page->freelist = (slab_object_t *)ptr;
page->used_count--;
if (page->used_count == objs_per_page - 1) {
remove_from_list(&cache->full, page);
add_to_list(&cache->partial, page);
}
else if (page->used_count == 0) {
remove_from_list(&cache->partial, page);
add_to_list(&cache->empty, page);
cache->empty_count++;
if (cache->empty_count > MAX_EMPTY_PAGES) {
shrink_slab_cache(cache);
}
}
}
void shrink_slab_cache(slab_cache_t *cache) {
slab_page_t *page = cache->empty;
while (page) {
free_heap_page((void *)page);
page = page->next;
}
cache->empty_count = 0;
cache->empty = NULL;
}
slab_page_t *get_slab_page(void *ptr) {
uintptr_t page_base = (uintptr_t)ptr & ~(PAGE_SIZE - 1);
size_t index = slab_page_hash(page_base);
slab_page_t *cur = slab_page_map[index];
while (cur) {
if (cur->vaddr == page_base)
return cur;
cur = cur->next_hash;
}
return NULL;
}
void init_freelist(slab_page_t *page, size_t obj_size) {
size_t objs_per_page = PAGE_SIZE / obj_size;
page->freelist = NULL;
for (int i = objs_per_page - 1; i >= 0; i--) {
slab_object_t *obj = (slab_object_t *)(page->vaddr + i * obj_size);
obj->next = page->freelist;
page->freelist = obj;
}
}
void dump_slab_cache_partial_freelist(size_t size) {
if (size == 0 || size>=NUM_SLAB_CLASSES*SLAB_STEP) return;
slab_cache_t *cache = &slab_caches[(size-1) / SLAB_STEP];
slab_page_t *partial = cache->partial;
if (!partial) return;
kernel_printf("slab cache partial list for size %d:\n", cache->object_size);
size_t cnt1 = 0;
size_t cnt2 = 0;
for (slab_page_t *p = partial; p&&cnt2<=5; p = p->next,cnt2++){
kernel_printf("partial-%d freelist:",cnt2);
for (slab_page_t *page = p->freelist; page&&cnt1<=5; page = page->next,cnt1++) {
kernel_printf(" %x->", page);
}
}
kernel_printf("\n");
}
void add_to_list(slab_page_t **list, slab_page_t *page) {
page->next = *list;
*list = page;
}
void remove_from_list(slab_page_t **list, slab_page_t *page) {
slab_page_t *prev = NULL, *cur = *list;
while (cur) {
if (cur == page) {
if (prev) prev->next = cur->next;
else *list = cur->next;
break;
}
prev = cur;
cur = cur->next;
}
}
|
简单测试结果
这里在kernel_main里写几个测试堆分配的函数,调用这些函数看看堆管理的基本行为是否符合预期。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| void test_basic_alloc_free() {
void *a = kmalloc(32);
void *b = kmalloc(32);
void *c = kmalloc(32);
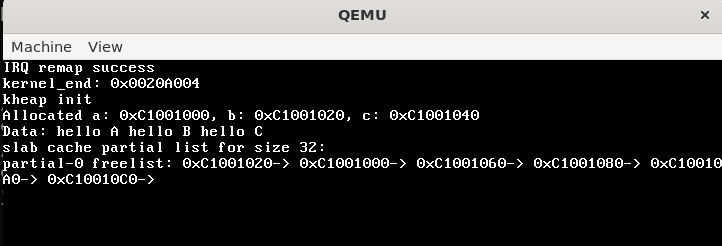
kernel_printf("Allocated a: %x, b: %x, c: %x\n", a, b, c);
strcpy(a, "hello A");
strcpy(b, "hello B");
strcpy(c, "hello C");
kernel_printf("Data: %s %s %s\n", (char *)a, (char *)b, (char *)c);
kfree(a);
kfree(b);
dump_slab_cache_partial(32);
kfree(c);
}
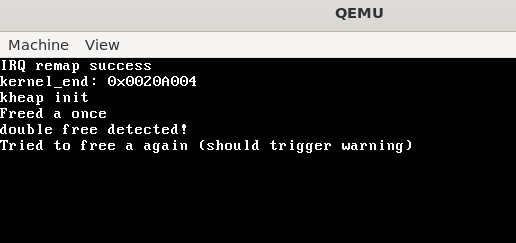
void test_double_free() {
void *a = kmalloc(64);
kfree(a);
kernel_printf("Freed a once\n");
kfree(a);
kernel_printf("Tried to free a again (should trigger warning)\n");
}
void test_multiple_sizes() {
void *s1 = kmalloc(32);
void *s2 = kmalloc(128);
void *s3 = kmalloc(256);
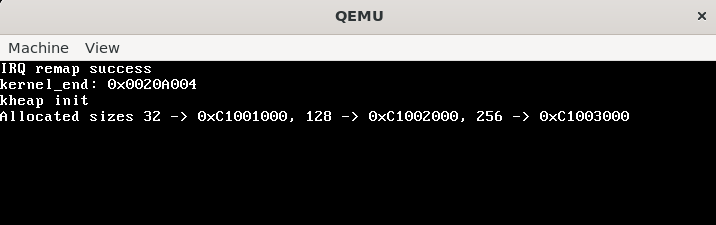
kernel_printf("Allocated sizes 32 -> %p, 128 -> %p, 256 -> %p\n", s1, s2, s3);
kfree(s1);
kfree(s2);
kfree(s3);
}
void test_reuse() {
void *a1 = kmalloc(64);
kfree(a1);
void *a2 = kmalloc(64);
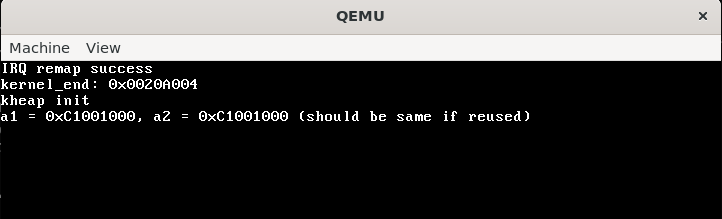
kernel_printf("a1 = %p, a2 = %p (should be same if reused)\n", a1, a2);
kfree(a2);
}
|
test_basic_alloc_free结果如下,发现首先分配到的是连续的堆空间的地址,然后也可以写入而不触发缺页异常。在free之后我们可以发现后free的b会在partial的freelist的链表头部,符合我们设计的头插FILO的链表。
test_multiple_sizes结果如下,因为一开始每个cache中都是空的,所以会映射一片新的页来存储。连续的分配新页符合预期。
test_reuse也正常工作,相同大小的的chunk可以复用。
test_double_free也可以检测到重复释放,从而不进行任何操作返回。
现在可以进行简单的运用,虽然没有尝试大量分配内存后是否会存在bug,但目前简单实现还是比较成功的。后续还可以扩展超过1页内存的大页分配逻辑。
大页分配逻辑扩展
我们这里复用之前的slab_page来表示大页,其中用到一个新的字段pages。这里我们先简单实现一个大页分配器,主要是用一个链表来存所有已分配的大页,而释放时也先不加入缓存机制,可以直接归还物理内存并从分配链表中移除。
1
2
3
4
5
6
7
8
9
10
| typedef struct slab_page {
struct slab_page_t *next;
uint32_t vaddr;
struct slab_object_t *freelist;
uint32_t used_count;
struct slab_cache *owner_cache;
uint8_t bitmap[16];
struct slab_page_t *next_hash;
uint32_t pages;
} slab_page_t;
|
这里相应可以复用alloc_slab_page_meta来申请存slab
page元数据结构体的空间,也可以填入hash
table中方便后续slab_free时可以用之前实现的get_slab_page得到对应的slab
page。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| static slab_page_t *large_alloc_list = NULL;
void *slab_alloc(size_t size) {
slab_page_t *page = NULL;
if (size == 0) return NULL;
int idx = slab_index(size);
if (idx < 0 || idx >= NUM_SLAB_CLASSES) {
uint32_t pages = (size + PAGE_SIZE - 1) / PAGE_SIZE;
kernel_printf("[slab] alloc %d bytes(%d pages), fallback to pmm_alloc_pages\n", size, pages);
page = alloc_slab_page_meta();
if (!page) return NULL;
page->pages = pages;
void *ptr = (void *)heap_next_free;
page->vaddr = (uint32_t)ptr;
for (uint32_t i = 0; i < pages; i++) alloc_heap_page();
size_t index = slab_page_hash((uintptr_t)ptr);
page->next_hash = slab_page_map[index];
slab_page_map[index] = page;
add_to_list(&large_alloc_list, page);
return ptr;
}
......
}
void free_heap_pages(slab_page_t *page,uint32_t count){
for (int i=0;i<count;i++) {
unmap_page(page->vaddr + i * PAGE_SIZE);
}
free_slab_page_meta(page);
remove_slab_page_from_hash(page);
}
void slab_free(void *ptr) {
if (!ptr) return;
uint32_t vaddr = (uint32_t)ptr;
slab_page_t *page = get_slab_page(vaddr);
if (!page || !page->owner_cache) return;
if (page->pages==0){
......
}else{
remove_from_list(&large_alloc_list, page);
free_heap_pages(page,page->pages);
}
}
|